 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Guided Hyperspectral Object Tracking via Semantics Fusion and Contextual Template Updating
Jun 08, 2026Hyperspectral object tracking (HOT) leverages the rich spectral information provided by hyperspectral videos (HSVs), offering substantial potential for object tracking. However, efficiently extracting and exploiting spectral information from redundant spectral bands remains a fundamental challenge, which severely limits model generalization and tracking performance. Moreover, in dynamic scenes, targets often experience drastic appearance variations due to factors such as occlusion and illumination changes. These variations lead to large deformations between the current frame and the template. Such discrepancies pose major challenges for existing temporal modeling approaches. In this work, we propose VLHTrack, a novel hyperspectral vision-language (VL) joint tracking framework. Specifically, we incorporate language priors to address the fundamental challenge of spectral redundancy by designing a Language-Guided Band Selection Module (LBSM). By leveraging Large Language Model (LLM) descriptions, LBSM establishes a semantic-to-spectral mapping that mitigates redundancy and accentuates discriminative spectral features. A Multi-Modal Vision-Language Fusion Module is then employed to seamlessly integrate visual and linguistic embeddings, harnessing their complementary advantages to learn coherent cross-modal representations. To address target deformation in long-term sequences, we propose a dynamic update template feature strategy implemented via the Dynamic Template Update with Mamba (DTUM) module. By leveraging selective state space modeling, DTUM learns inter-frame dependencies to update template feature, ensuring efficient template feature evolution guided by temporal context. Experiments on HOT2023 and HOT2024 demonstrate that VLHTrack outperforms state-of-the-art (SOTA) methods.
Unified framework for outage-constrained rate maximization in secure ISAC under various sensing metrics
Mar 13, 2026Integrated sensing and communication (ISAC) is poised to redefine the landscape of wireless networks by seamlessly combining data transmission and environmental sensing. However, ISAC systems remain susceptible to eavesdropping, especially under uncertainty in eavesdroppers' channel state information, which can lead to secrecy outages. On the other hand, diverse and complex sensing performance requirements further complicate resource optimization, often requiring custom solutions for each scenario. To this end, this paper introduces a unified optimization framework that holistically addresses both the worst-case user secrecy rate and the sum secrecy rate across multiple users. Besides putting the two commonly used objectives into a single but flexible objective function, the framework accurately controls secrecy outage probabilities while accommodating a broad spectrum of sensing constraints. To solve such a general problem, we integrate the sensing requirements into the objective function through an auxiliary variable. This enables efficient alternating optimization and the proposed approach is theoretically guaranteed to converge to at least a stationary point of the original problem. Extensive simulation results show that the proposed framework consistently achieves higher optimized secrecy rates under various sensing constraints compared to existing methods. These results underscore the proposed unified framework's superiority and versatility in secure ISAC systems.
Content-Adaptive Image Retouching Guided by Attribute-Based Text Representation
Dec 10, 2025Image retouching has received significant attention due to its ability to achieve high-quality visual content. Existing approaches mainly rely on uniform pixel-wise color mapping across entire images, neglecting the inherent color variations induced by image content. This limitation hinders existing approaches from achieving adaptive retouching that accommodates both diverse color distributions and user-defined style preferences. To address these challenges, we propose a novel Content-Adaptive image retouching method guided by Attribute-based Text Representation (CA-ATP). Specifically, we propose a content-adaptive curve mapping module, which leverages a series of basis curves to establish multiple color mapping relationships and learns the corresponding weight maps, enabling content-aware color adjustments. The proposed module can capture color diversity within the image content, allowing similar color values to receive distinct transformations based on their spatial context. In addition, we propose an attribute text prediction module that generates text representations from multiple image attributes, which explicitly represent user-defined style preferences. These attribute-based text representations are subsequently integrated with visual features via a multimodal model, providing user-friendly guidance for image retouching. Extensive experiments on several public datasets demonstrate that our method achieves state-of-the-art performance.
DTTNet: Improving Video Shadow Detection via Dark-Aware Guidance and Tokenized Temporal Modeling
Nov 10, 2025Video shadow detection confronts two entwined difficulties: distinguishing shadows from complex backgrounds and modeling dynamic shadow deformations under varying illumination. To address shadow-background ambiguity, we leverage linguistic priors through the proposed Vision-language Match Module (VMM) and a Dark-aware Semantic Block (DSB), extracting text-guided features to explicitly differentiate shadows from dark objects. Furthermore, we introduce adaptive mask reweighting to downweight penumbra regions during training and apply edge masks at the final decoder stage for better supervision. For temporal modeling of variable shadow shapes, we propose a Tokenized Temporal Block (TTB) that decouples spatiotemporal learning. TTB summarizes cross-frame shadow semantics into learnable temporal tokens, enabling efficient sequence encoding with minimal computation overhead. Comprehensive Experiments on multiple benchmark datasets demonstrate state-of-the-art accuracy and real-time inference efficiency. Codes are available at https://github.com/city-cheng/DTTNet.
Modality-Guided Dynamic Graph Fusion and Temporal Diffusion for Self-Supervised RGB-T Tracking
May 06, 2025To reduce the reliance on large-scale annotations, self-supervised RGB-T tracking approaches have garnered significant attention. However, the omission of the object region by erroneous pseudo-label or the introduction of background noise affects the efficiency of modality fusion, while pseudo-label noise triggered by similar object noise can further affect the tracking performance. In this paper, we propose GDSTrack, a novel approach that introduces dynamic graph fusion and temporal diffusion to address the above challenges in self-supervised RGB-T tracking. GDSTrack dynamically fuses the modalities of neighboring frames, treats them as distractor noise, and leverages the denoising capability of a generative model. Specifically, by constructing an adjacency matrix via an Adjacency Matrix Generator (AMG), the proposed Modality-guided Dynamic Graph Fusion (MDGF) module uses a dynamic adjacency matrix to guide graph attention, focusing on and fusing the object's coherent regions. Temporal Graph-Informed Diffusion (TGID) models MDGF features from neighboring frames as interference, and thus improving robustness against similar-object noise. Extensive experiments conducted on four public RGB-T tracking datasets demonstrate that GDSTrack outperforms the existing state-of-the-art methods. The source code is available at https://github.com/LiShenglana/GDSTrack.
A General Optimization Framework for Tackling Distance Constraints in Movable Antenna-Aided Systems
Mar 04, 2025The recently emerged movable antenna (MA) shows great promise in leveraging spatial degrees of freedom to enhance the performance of wireless systems. However, resource allocation in MA-aided systems faces challenges due to the nonconvex and coupled constraints on antenna positions. This paper systematically reveals the challenges posed by the minimum antenna separation distance constraints. Furthermore, we propose a penalty optimization framework for resource allocation under such new constraints for MA-aided systems. Specifically, the proposed framework separates the non-convex and coupled antenna distance constraints from the movable region constraints by introducing auxiliary variables. Subsequently, the resulting problem is efficiently solved by alternating optimization, where the optimization of the original variables resembles that in conventional resource allocation problem while the optimization with respect to the auxiliary variables is achieved in closedform solutions. To illustrate the effectiveness of the proposed framework, we present three case studies: capacity maximization, latency minimization, and regularized zero-forcing precoding. Simulation results demonstrate that the proposed optimization framework consistently outperforms state-of-the-art schemes.
Facial Action Unit Detection by Adaptively Constraining Self-Attention and Causally Deconfounding Sample
Oct 02, 2024Facial action unit (AU) detection remains a challenging task, due to the subtlety, dynamics, and diversity of AUs. Recently, the prevailing techniques of self-attention and causal inference have been introduced to AU detection. However, most existing methods directly learn self-attention guided by AU detection, or employ common patterns for all AUs during causal intervention. The former often captures irrelevant information in a global range, and the latter ignores the specific causal characteristic of each AU. In this paper, we propose a novel AU detection framework called AC2D by adaptively constraining self-attention weight distribution and causally deconfounding the sample confounder. Specifically, we explore the mechanism of self-attention weight distribution, in which the self-attention weight distribution of each AU is regarded as spatial distribution and is adaptively learned under the constraint of location-predefined attention and the guidance of AU detection. Moreover, we propose a causal intervention module for each AU, in which the bias caused by training samples and the interference from irrelevant AUs are both suppressed. Extensive experiments show that our method achieves competitive performance compared to state-of-the-art AU detection approaches on challenging benchmarks, including BP4D, DISFA, GFT, and BP4D+ in constrained scenarios and Aff-Wild2 in unconstrained scenarios. The code is available at https://github.com/ZhiwenShao/AC2D.
OrientedFormer: An End-to-End Transformer-Based Oriented Object Detector in Remote Sensing Images
Sep 29, 2024Oriented object detection in remote sensing images is a challenging task due to objects being distributed in multi-orientation. Recently, end-to-end transformer-based methods have achieved success by eliminating the need for post-processing operators compared to traditional CNN-based methods. However, directly extending transformers to oriented object detection presents three main issues: 1) objects rotate arbitrarily, necessitating the encoding of angles along with position and size; 2) the geometric relations of oriented objects are lacking in self-attention, due to the absence of interaction between content and positional queries; and 3) oriented objects cause misalignment, mainly between values and positional queries in cross-attention, making accurate classification and localization difficult. In this paper, we propose an end-to-end transformer-based oriented object detector, consisting of three dedicated modules to address these issues. First, Gaussian positional encoding is proposed to encode the angle, position, and size of oriented boxes using Gaussian distributions. Second, Wasserstein self-attention is proposed to introduce geometric relations and facilitate interaction between content and positional queries by utilizing Gaussian Wasserstein distance scores. Third, oriented cross-attention is proposed to align values and positional queries by rotating sampling points around the positional query according to their angles. Experiments on six datasets DIOR-R, a series of DOTA, HRSC2016 and ICDAR2015 show the effectiveness of our approach. Compared with previous end-to-end detectors, the OrientedFormer gains 1.16 and 1.21 AP$_{50}$ on DIOR-R and DOTA-v1.0 respectively, while reducing training epochs from 3$\times$ to 1$\times$. The codes are available at https://github.com/wokaikaixinxin/OrientedFormer.
Revisiting Trace Norm Minimization for Tensor Tucker Completion: A Direct Multilinear Rank Learning Approach
Sep 10, 2024



To efficiently express tensor data using the Tucker format, a critical task is to minimize the multilinear rank such that the model would not be over-flexible and lead to overfitting. Due to the lack of rank minimization tools in tensor, existing works connect Tucker multilinear rank minimization to trace norm minimization of matrices unfolded from the tensor data. While these formulations try to exploit the common aim of identifying the low-dimensional structure of the tensor and matrix, this paper reveals that existing trace norm-based formulations in Tucker completion are inefficient in multilinear rank minimization. We further propose a new interpretation of Tucker format such that trace norm minimization is applied to the factor matrices of the equivalent representation, rather than some matrices unfolded from tensor data. Based on the newly established problem formulation, a fixed point iteration algorithm is proposed, and its convergence is proved. Numerical results are presented to show that the proposed algorithm exhibits significant improved performance in terms of multilinear rank learning and consequently tensor signal recovery accuracy, compared to existing trace norm based Tucker completion methods.
Efficient Decoder for End-to-End Oriented Object Detection in Remote Sensing Images
Dec 02, 2023
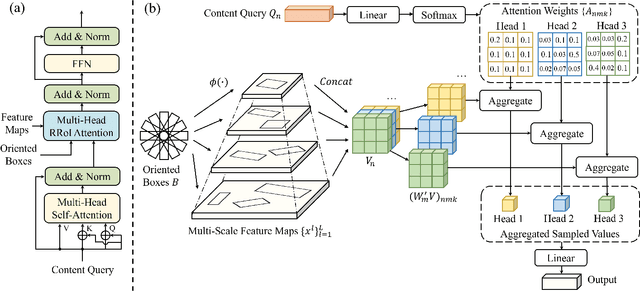
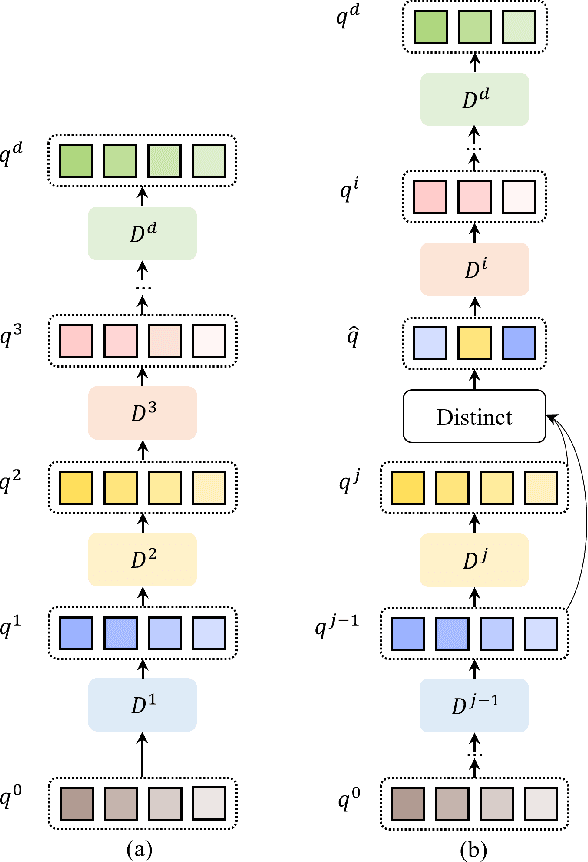
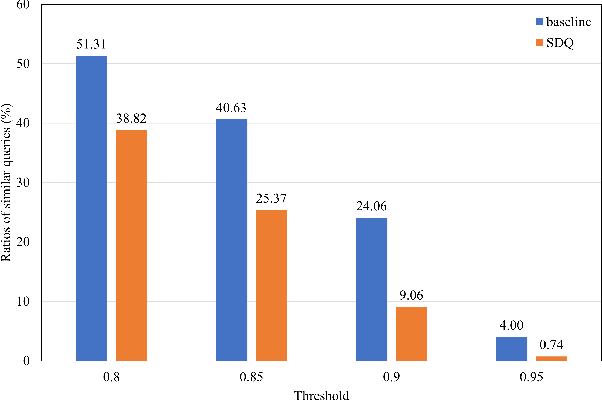
Object instances in remote sensing images often distribute with multi-orientations, varying scales, and dense distribution. These issues bring challenges to end-to-end oriented object detectors including multi-scale features alignment and a large number of queries. To address these limitations, we propose an end-to-end oriented detector equipped with an efficient decoder, which incorporates two technologies, Rotated RoI attention (RRoI attention) and Selective Distinct Queries (SDQ). Specifically, RRoI attention effectively focuses on oriented regions of interest through a cross-attention mechanism and aligns multi-scale features. SDQ collects queries from intermediate decoder layers and then filters similar queries to obtain distinct queries. The proposed SDQ can facilitate the optimization of one-to-one label assignment, without introducing redundant initial queries or extra auxiliary branches. Extensive experiments on five datasets demonstrate the effectiveness of our method. Notably, our method achieves state-of-the-art performance on DIOR-R (67.31% mAP), DOTA-v1.5 (67.43% mAP), and DOTA-v2.0 (53.28% mAP) with the ResNet50 backbone.