 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking AI Agents for Addressing Scientific Challenges Across Scales
Jun 10, 2026AI agents are increasingly being developed to accelerate scientific discovery, yet their practical capabilities in real research settings remain poorly understood. Existing benchmarks for AI agents rarely capture the complexity, heterogeneity, and extended reasoning required by scientific work, whereas benchmarks for scientific tasks often reduce research to static, direct problems and provide limited support for interactive evaluation. Here, we introduce SciAgentArena, a systematic benchmark for evaluating AI agents in real-world scientific research scenarios drawn from emerging needs across multiple domains. SciAgentArena comprises approximately 200 tasks with stepwise verification and an interactive, agent-agnostic environment for assessing diverse AI agents. Using this benchmark, we find that current agents can contribute effectively to well-specified data-analysis workflows, particularly when the task structure and evaluation criteria are clear. However, their performance remains uneven across scientific contexts: agents struggle to generate genuinely novel insights, sustain self-directed exploration, and formulate robust solutions for open-ended research questions. We further characterize common failure modes across agents and identify opportunities for improving their reliability, autonomy, and scientific reasoning. Together, SciAgentArena provides a practical framework for measuring progress in AI agents for science and for guiding the design of future agents capable of addressing complex scientific challenges. Full codes, tasks, and datasets can be accessed via this link: https://sciagentarena.github.io/.
Towards Diverse Scientific Hypothesis Search with Large Language Models
Jun 09, 2026Large language models (LLMs) are on the rise for accelerating scientific discovery, most recently in advanced tasks such as generating valid scientific hypotheses. Yet in many discovery settings, the goal is not to identify a single best hypothesis since validation can be noisy and expensive, and scientists benefit from a set of high-quality alternative hypotheses that hedge against downstream uncertainty for the best solutions. Nevertheless, commonly used evolutionary search recipes tend to prioritize optimization over exploration in hypothesis generation, and the resulting selection pressure during the search process leads to diversity collapse. Motivated by these limitations, we formulate hypothesis search as a sampling problem, where the objective is to efficiently produce diverse, high-quality hypotheses under a fixed validation budget. Building on this perspective, we propose \ours, an evolutionary framework inspired by the classical parallel tempering algorithm that searches hypotheses at multiple temperature levels and enables principled information exchange across temperatures to improve exploration without disrupting convergence. Across domains including molecular discovery, equation discovery, and algorithm discovery, our approach consistently improves both hypothesis quality and diversity under the same validation budget, and produces candidates that remain robust under more expensive downstream computational validations.
Vision-Language Guided Hyperspectral Object Tracking via Semantics Fusion and Contextual Template Updating
Jun 08, 2026Hyperspectral object tracking (HOT) leverages the rich spectral information provided by hyperspectral videos (HSVs), offering substantial potential for object tracking. However, efficiently extracting and exploiting spectral information from redundant spectral bands remains a fundamental challenge, which severely limits model generalization and tracking performance. Moreover, in dynamic scenes, targets often experience drastic appearance variations due to factors such as occlusion and illumination changes. These variations lead to large deformations between the current frame and the template. Such discrepancies pose major challenges for existing temporal modeling approaches. In this work, we propose VLHTrack, a novel hyperspectral vision-language (VL) joint tracking framework. Specifically, we incorporate language priors to address the fundamental challenge of spectral redundancy by designing a Language-Guided Band Selection Module (LBSM). By leveraging Large Language Model (LLM) descriptions, LBSM establishes a semantic-to-spectral mapping that mitigates redundancy and accentuates discriminative spectral features. A Multi-Modal Vision-Language Fusion Module is then employed to seamlessly integrate visual and linguistic embeddings, harnessing their complementary advantages to learn coherent cross-modal representations. To address target deformation in long-term sequences, we propose a dynamic update template feature strategy implemented via the Dynamic Template Update with Mamba (DTUM) module. By leveraging selective state space modeling, DTUM learns inter-frame dependencies to update template feature, ensuring efficient template feature evolution guided by temporal context. Experiments on HOT2023 and HOT2024 demonstrate that VLHTrack outperforms state-of-the-art (SOTA) methods.
Agents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Content-Adaptive Image Retouching Guided by Attribute-Based Text Representation
Dec 10, 2025Image retouching has received significant attention due to its ability to achieve high-quality visual content. Existing approaches mainly rely on uniform pixel-wise color mapping across entire images, neglecting the inherent color variations induced by image content. This limitation hinders existing approaches from achieving adaptive retouching that accommodates both diverse color distributions and user-defined style preferences. To address these challenges, we propose a novel Content-Adaptive image retouching method guided by Attribute-based Text Representation (CA-ATP). Specifically, we propose a content-adaptive curve mapping module, which leverages a series of basis curves to establish multiple color mapping relationships and learns the corresponding weight maps, enabling content-aware color adjustments. The proposed module can capture color diversity within the image content, allowing similar color values to receive distinct transformations based on their spatial context. In addition, we propose an attribute text prediction module that generates text representations from multiple image attributes, which explicitly represent user-defined style preferences. These attribute-based text representations are subsequently integrated with visual features via a multimodal model, providing user-friendly guidance for image retouching. Extensive experiments on several public datasets demonstrate that our method achieves state-of-the-art performance.
DTTNet: Improving Video Shadow Detection via Dark-Aware Guidance and Tokenized Temporal Modeling
Nov 10, 2025Video shadow detection confronts two entwined difficulties: distinguishing shadows from complex backgrounds and modeling dynamic shadow deformations under varying illumination. To address shadow-background ambiguity, we leverage linguistic priors through the proposed Vision-language Match Module (VMM) and a Dark-aware Semantic Block (DSB), extracting text-guided features to explicitly differentiate shadows from dark objects. Furthermore, we introduce adaptive mask reweighting to downweight penumbra regions during training and apply edge masks at the final decoder stage for better supervision. For temporal modeling of variable shadow shapes, we propose a Tokenized Temporal Block (TTB) that decouples spatiotemporal learning. TTB summarizes cross-frame shadow semantics into learnable temporal tokens, enabling efficient sequence encoding with minimal computation overhead. Comprehensive Experiments on multiple benchmark datasets demonstrate state-of-the-art accuracy and real-time inference efficiency. Codes are available at https://github.com/city-cheng/DTTNet.
Modality-Guided Dynamic Graph Fusion and Temporal Diffusion for Self-Supervised RGB-T Tracking
May 06, 2025To reduce the reliance on large-scale annotations, self-supervised RGB-T tracking approaches have garnered significant attention. However, the omission of the object region by erroneous pseudo-label or the introduction of background noise affects the efficiency of modality fusion, while pseudo-label noise triggered by similar object noise can further affect the tracking performance. In this paper, we propose GDSTrack, a novel approach that introduces dynamic graph fusion and temporal diffusion to address the above challenges in self-supervised RGB-T tracking. GDSTrack dynamically fuses the modalities of neighboring frames, treats them as distractor noise, and leverages the denoising capability of a generative model. Specifically, by constructing an adjacency matrix via an Adjacency Matrix Generator (AMG), the proposed Modality-guided Dynamic Graph Fusion (MDGF) module uses a dynamic adjacency matrix to guide graph attention, focusing on and fusing the object's coherent regions. Temporal Graph-Informed Diffusion (TGID) models MDGF features from neighboring frames as interference, and thus improving robustness against similar-object noise. Extensive experiments conducted on four public RGB-T tracking datasets demonstrate that GDSTrack outperforms the existing state-of-the-art methods. The source code is available at https://github.com/LiShenglana/GDSTrack.
SynLlama: Generating Synthesizable Molecules and Their Analogs with Large Language Models
Mar 16, 2025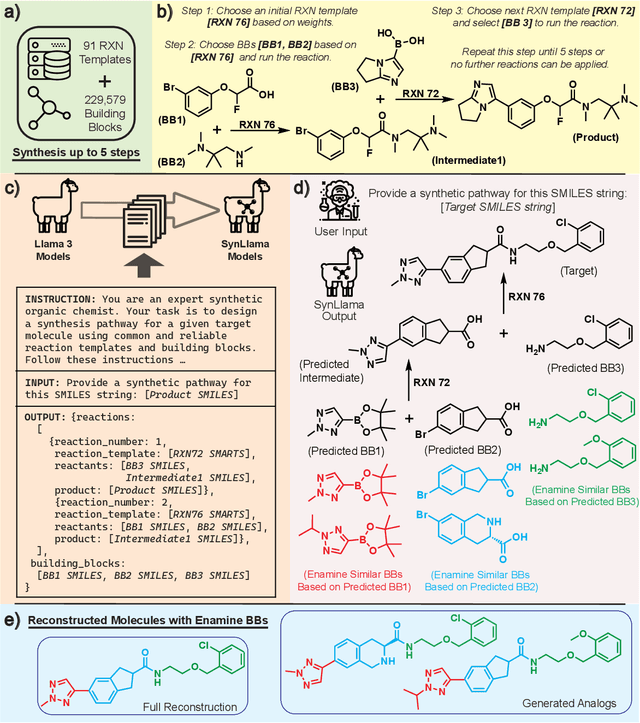
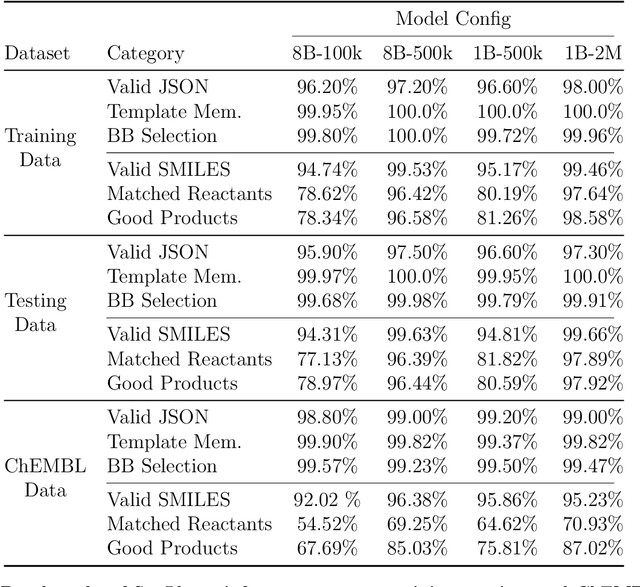
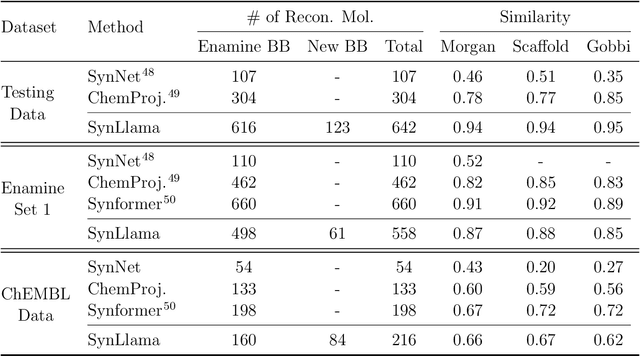
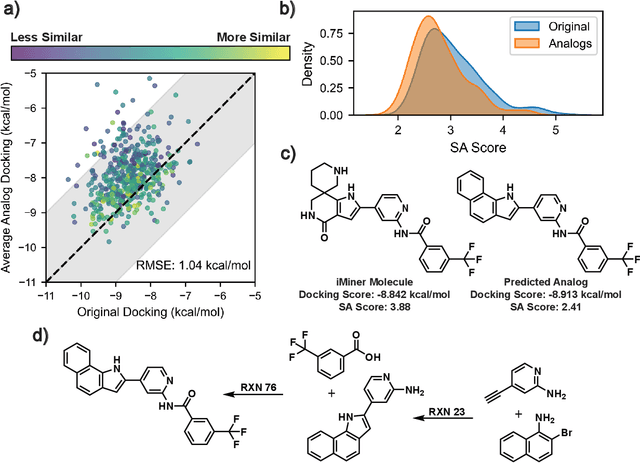
Generative machine learning models for small molecule drug discovery have shown immense promise, but many molecules generated by this approach are too difficult to synthesize to be worth further investigation or further development. We present a novel approach by fine-tuning Meta's Llama3 large language models (LLMs) to create SynLlama, which generates full synthetic pathways made of commonly accessible Enamine building blocks and robust organic reaction templates. SynLlama explores a large synthesizable space using significantly less data compared to other state-of-the-art methods, and offers strong performance in bottom-up synthesis, synthesizable analog generation, and hit expansion, offering medicinal chemists a valuable tool for drug discovery developments. We find that SynLlama can effectively generalize to unseen yet purchasable building blocks, meaning that its reconstruction capabilities extend to a broader synthesizable chemical space than the training data.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
SmileyLlama: Modifying Large Language Models for Directed Chemical Space Exploration
Sep 03, 2024



Here we show that a Large Language Model (LLM) can serve as a foundation model for a Chemical Language Model (CLM) which performs at or above the level of CLMs trained solely on chemical SMILES string data. Using supervised fine-tuning (SFT) and direct preference optimization (DPO) on the open-source Llama LLM, we demonstrate that we can train an LLM to respond to prompts such as generating molecules with properties of interest to drug development. This overall framework allows an LLM to not just be a chatbot client for chemistry and materials tasks, but can be adapted to speak more directly as a CLM which can generate molecules with user-specified properties.