 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeDMRA: Federated Incremental Learning with Dynamic Memory Replay Allocation
Mar 30, 2026In federated healthcare systems, Federated Class-Incremental Learning (FCIL) has emerged as a key paradigm, enabling continuous adaptive model learning among distributed clients while safeguarding data privacy. However, in practical applications, data across agent nodes within the distributed framework often exhibits non-independent and identically distributed (non-IID) characteristics, rendering traditional continual learning methods inapplicable. To address these challenges, this paper covers more comprehensive incremental task scenarios and proposes a dynamic memory allocation strategy for exemplar storage based on the data replay mechanism. This strategy fully taps into the inherent potential of data heterogeneity, while taking into account the performance fairness of all participating clients, thereby establishing a balanced and adaptive solution to mitigate catastrophic forgetting. Unlike the fixed allocation of client exemplar memory, the proposed scheme emphasizes the rational allocation of limited storage resources among clients to improve model performance. Furthermore, extensive experiments are conducted on three medical image datasets, and the results demonstrate significant performance improvements compared to existing baseline models.
OpenHAIV: A Framework Towards Practical Open-World Learning
Aug 10, 2025Substantial progress has been made in various techniques for open-world recognition. Out-of-distribution (OOD) detection methods can effectively distinguish between known and unknown classes in the data, while incremental learning enables continuous model knowledge updates. However, in open-world scenarios, these approaches still face limitations. Relying solely on OOD detection does not facilitate knowledge updates in the model, and incremental fine-tuning typically requires supervised conditions, which significantly deviate from open-world settings. To address these challenges, this paper proposes OpenHAIV, a novel framework that integrates OOD detection, new class discovery, and incremental continual fine-tuning into a unified pipeline. This framework allows models to autonomously acquire and update knowledge in open-world environments. The proposed framework is available at https://haiv-lab.github.io/openhaiv .
OpenEarthSensing: Large-Scale Fine-Grained Benchmark for Open-World Remote Sensing
Feb 28, 2025
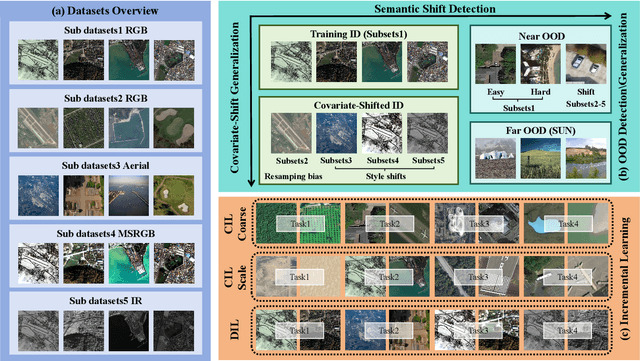

In open-world remote sensing, deployed models must continuously adapt to a steady influx of new data, which often exhibits various shifts compared to what the model encountered during the training phase. To effectively handle the new data, models are required to detect semantic shifts, adapt to covariate shifts, and continuously update themselves. These challenges give rise to a variety of open-world tasks. However, existing open-world remote sensing studies typically train and test within a single dataset to simulate open-world conditions. Currently, there is a lack of large-scale benchmarks capable of evaluating multiple open-world tasks. In this paper, we introduce OpenEarthSensing, a large-scale fine-grained benchmark for open-world remote sensing. OpenEarthSensing includes 189 scene and objects categories, covering the vast majority of potential semantic shifts that may occur in the real world. Additionally, OpenEarthSensing encompasses five data domains with significant covariate shifts, including two RGB satellite domians, one RGB aerial domian, one MS RGB domian, and one infrared domian. The various domains provide a more comprehensive testbed for evaluating the generalization performance of open-world models. We conduct the baseline evaluation of current mainstream open-world tasks and methods on OpenEarthSensing, demonstrating that it serves as a challenging benchmark for open-world remote sensing.
Facial Action Unit Detection by Adaptively Constraining Self-Attention and Causally Deconfounding Sample
Oct 02, 2024Facial action unit (AU) detection remains a challenging task, due to the subtlety, dynamics, and diversity of AUs. Recently, the prevailing techniques of self-attention and causal inference have been introduced to AU detection. However, most existing methods directly learn self-attention guided by AU detection, or employ common patterns for all AUs during causal intervention. The former often captures irrelevant information in a global range, and the latter ignores the specific causal characteristic of each AU. In this paper, we propose a novel AU detection framework called AC2D by adaptively constraining self-attention weight distribution and causally deconfounding the sample confounder. Specifically, we explore the mechanism of self-attention weight distribution, in which the self-attention weight distribution of each AU is regarded as spatial distribution and is adaptively learned under the constraint of location-predefined attention and the guidance of AU detection. Moreover, we propose a causal intervention module for each AU, in which the bias caused by training samples and the interference from irrelevant AUs are both suppressed. Extensive experiments show that our method achieves competitive performance compared to state-of-the-art AU detection approaches on challenging benchmarks, including BP4D, DISFA, GFT, and BP4D+ in constrained scenarios and Aff-Wild2 in unconstrained scenarios. The code is available at https://github.com/ZhiwenShao/AC2D.
AI WALKUP: A Computer-Vision Approach to Quantifying MDS-UPDRS in Parkinson's Disease
Apr 02, 2024
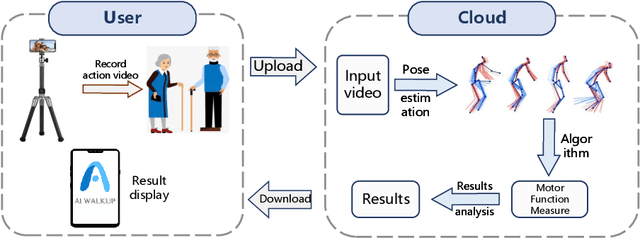
Parkinson's Disease (PD) is the second most common neurodegenerative disorder. The existing assessment method for PD is usually the Movement Disorder Society - Unified Parkinson's Disease Rating Scale (MDS-UPDRS) to assess the severity of various types of motor symptoms and disease progression. However, manual assessment suffers from high subjectivity, lack of consistency, and high cost and low efficiency of manual communication. We want to use a computer vision based solution to capture human pose images based on a camera, reconstruct and perform motion analysis using algorithms, and extract the features of the amount of motion through feature engineering. The proposed approach can be deployed on different smartphones, and the video recording and artificial intelligence analysis can be done quickly and easily through our APP.
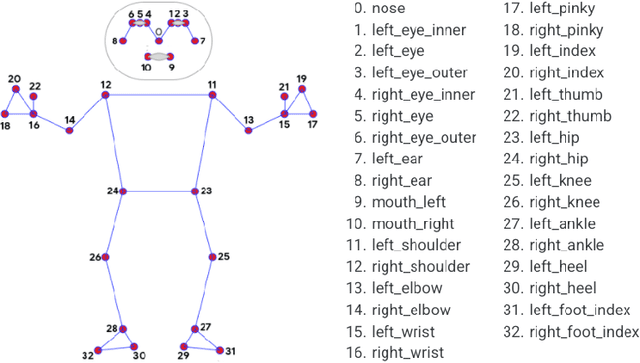
YOLOOC: YOLO-based Open-Class Incremental Object Detection with Novel Class Discovery
Mar 30, 2024
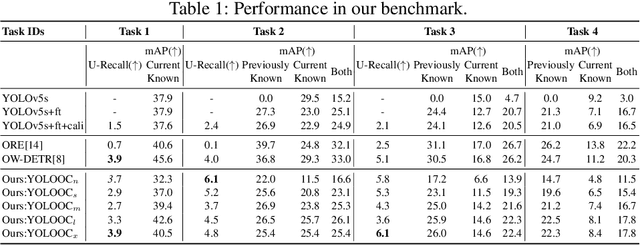
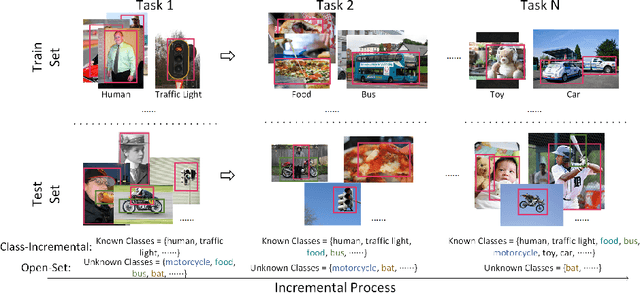
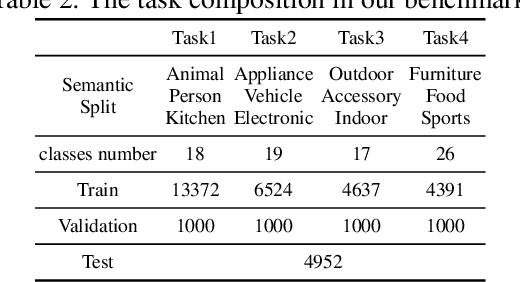
Because of its use in practice, open-world object detection (OWOD) has gotten a lot of attention recently. The challenge is how can a model detect novel classes and then incrementally learn them without forgetting previously known classes. Previous approaches hinge on strongly-supervised or weakly-supervised novel-class data for novel-class detection, which may not apply to real applications. We construct a new benchmark that novel classes are only encountered at the inference stage. And we propose a new OWOD detector YOLOOC, based on the YOLO architecture yet for the Open-Class setup. We introduce label smoothing to prevent the detector from over-confidently mapping novel classes to known classes and to discover novel classes. Extensive experiments conducted on our more realistic setup demonstrate the effectiveness of our method for discovering novel classes in our new benchmark.
Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer
Mar 29, 2024
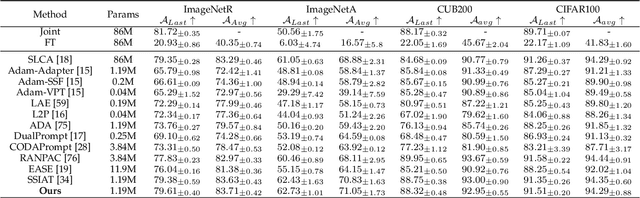
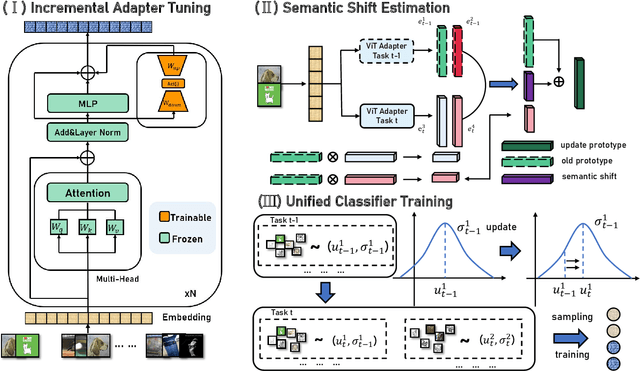
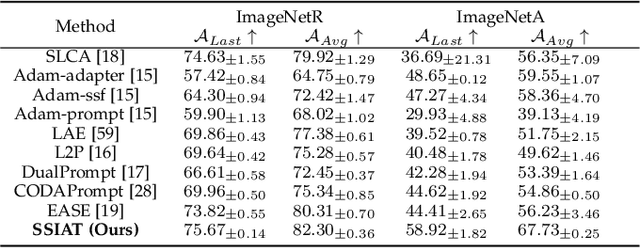
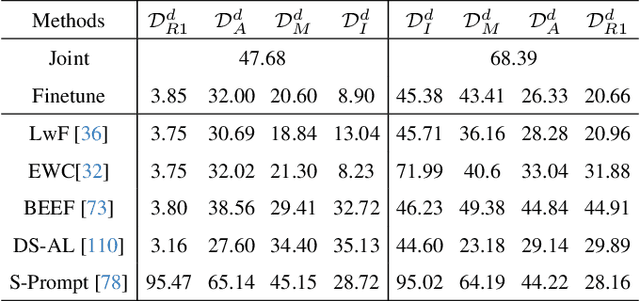
Class-incremental learning (CIL) aims to enable models to continuously learn new classes while overcoming catastrophic forgetting. The introduction of pre-trained models has brought new tuning paradigms to CIL. In this paper, we revisit different parameter-efficient tuning (PET) methods within the context of continual learning. We observe that adapter tuning demonstrates superiority over prompt-based methods, even without parameter expansion in each learning session. Motivated by this, we propose incrementally tuning the shared adapter without imposing parameter update constraints, enhancing the learning capacity of the backbone. Additionally, we employ feature sampling from stored prototypes to retrain a unified classifier, further improving its performance. We estimate the semantic shift of old prototypes without access to past samples and update stored prototypes session by session. Our proposed method eliminates model expansion and avoids retaining any image samples. It surpasses previous pre-trained model-based CIL methods and demonstrates remarkable continual learning capabilities. Experimental results on five CIL benchmarks validate the effectiveness of our approach, achieving state-of-the-art (SOTA) performance.
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Mar 29, 2024



Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
A Pilot Study of Relating MYCN-Gene Amplification with Neuroblastoma-Patient CT Scans
May 21, 2022
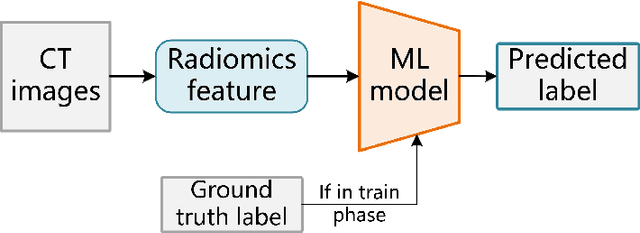
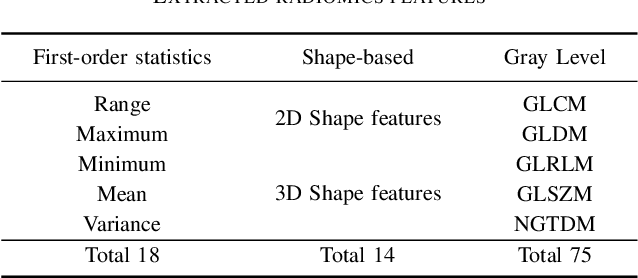
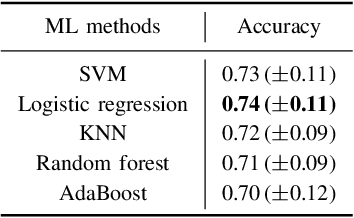
Neuroblastoma is one of the most common cancers in infants, and the initial diagnosis of this disease is difficult. At present, the MYCN gene amplification (MNA) status is detected by invasive pathological examination of tumor samples. This is time-consuming and may have a hidden impact on children. To handle this problem, we adopt multiple machine learning (ML) algorithms to predict the presence or absence of MYCN gene amplification. The dataset is composed of retrospective CT images of 23 neuroblastoma patients. Different from previous work, we develop the algorithm without manually-segmented primary tumors which is time-consuming and not practical. Instead, we only need the coordinate of the center point and the number of tumor slices given by a subspecialty-trained pediatric radiologist. Specifically, CNN-based method uses pre-trained convolutional neural network, and radiomics-based method extracts radiomics features. Our results show that CNN-based method outperforms the radiomics-based method.
Lightweight Human Pose Estimation Using Heatmap-Weighting Loss
May 21, 2022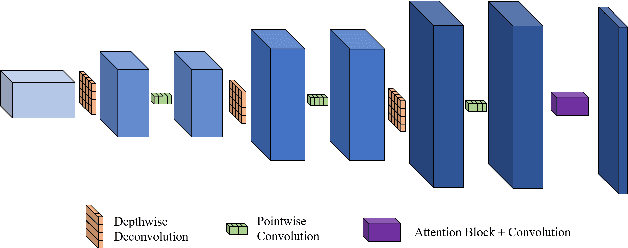
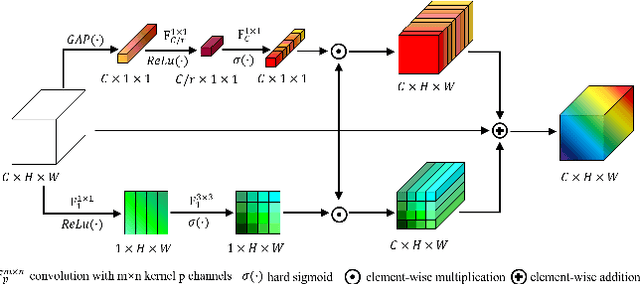
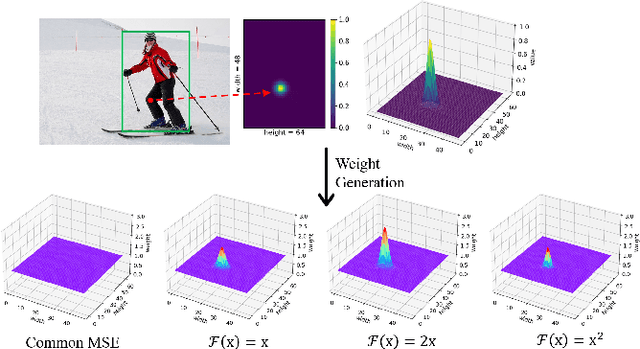
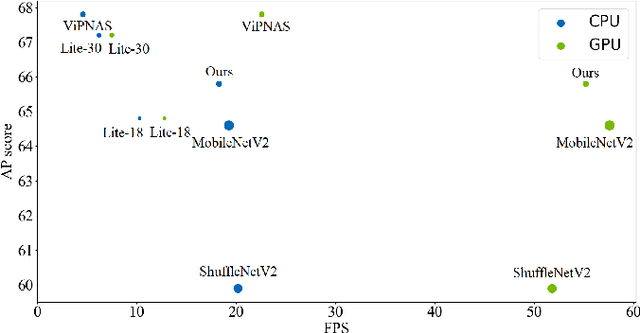
Recent research on human pose estimation exploits complex structures to improve performance on benchmark datasets, ignoring the resource overhead and inference speed when the model is actually deployed. In this paper, we lighten the computation cost and parameters of the deconvolution head network in SimpleBaseline and introduce an attention mechanism that utilizes original, inter-level, and intra-level information to intensify the accuracy. Additionally, we propose a novel loss function called heatmap weighting loss, which generates weights for each pixel on the heatmap that makes the model more focused on keypoints. Experiments demonstrate our method achieves a balance between performance, resource volume, and inference speed. Specifically, our method can achieve 65.3 AP score on COCO test-dev, while the inference speed is 55 FPS and 18 FPS on the mobile GPU and CPU, respectively.