 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Emulation for Knowledge Distillation
Paper and Code
May 21, 2022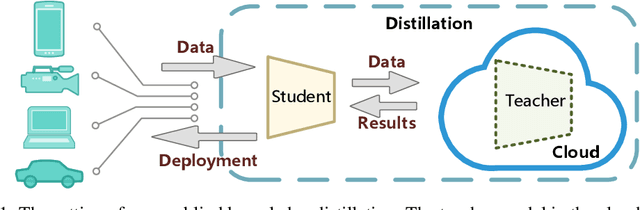
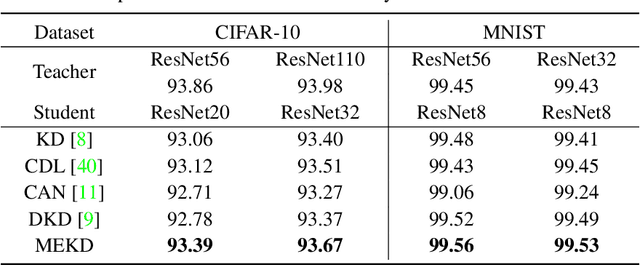
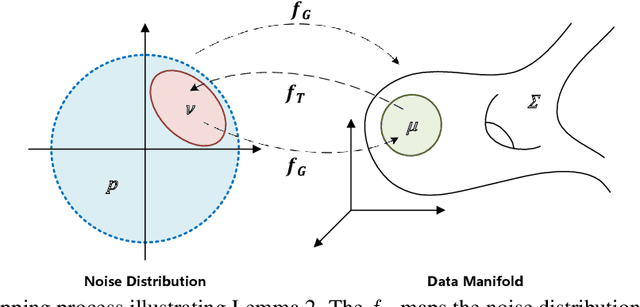
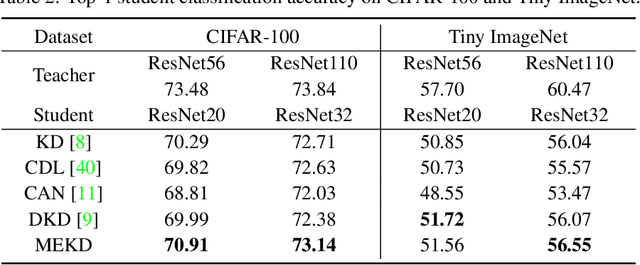
This paper formalizes the source-blind knowledge distillation problem that is essential to federated learning. A new geometric perspective is presented to view such a problem as aligning generated distributions between the teacher and student. With its guidance, a new architecture MEKD is proposed to emulate the inverse mapping through generative adversarial training. Unlike mimicking logits and aligning logit distributions, reconstructing the mapping from classifier-logits has a geometric intuition of decreasing empirical distances, and theoretical guarantees using the universal function approximation and optimal mass transportation theories. A new algorithm is also proposed to train the student model that reaches the teacher's performance source-blindly. On various benchmarks, MEKD outperforms existing source-blind KD methods, explainable with ablation studies and visualized results.