 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathMem: Toward Cognition-Aligned Memory Transformation for Pathology MLLMs
Mar 10, 2026Computational pathology demands both visual pattern recognition and dynamic integration of structured domain knowledge, including taxonomy, grading criteria, and clinical evidence. In practice, diagnostic reasoning requires linking morphological evidence with formal diagnostic and grading criteria. Although multimodal large language models (MLLMs) demonstrate strong vision language reasoning capabilities, they lack explicit mechanisms for structured knowledge integration and interpretable memory control. As a result, existing models struggle to consistently incorporate pathology-specific diagnostic standards during reasoning. Inspired by the hierarchical memory process of human pathologists, we propose PathMem, a memory-centric multimodal framework for pathology MLLMs. PathMem organizes structured pathology knowledge as a long-term memory (LTM) and introduces a Memory Transformer that models the dynamic transition from LTM to working memory (WM) through multimodal memory activation and context-aware knowledge grounding, enabling context-aware memory refinement for downstream reasoning. PathMem achieves SOTA performance across benchmarks, improving WSI-Bench report generation (12.8% WSI-Precision, 10.1% WSI-Relevance) and open-ended diagnosis by 9.7% and 8.9% over prior WSI-based models.
SaFeR-ToolKit: Structured Reasoning via Virtual Tool Calling for Multimodal Safety
Mar 03, 2026Vision-language models remain susceptible to multimodal jailbreaks and over-refusal because safety hinges on both visual evidence and user intent, while many alignment pipelines supervise only the final response. To address this, we present SaFeR-ToolKit, which formalizes safety decision-making as a checkable protocol. Concretely, a planner specifies a persona, a Perception $\to$ Reasoning $\to$ Decision tool set, and a constrained transition graph, while a responder outputs a typed key-value tool trace before the final answer. To make the protocol reliably followed in practice, we train a single policy with a three-stage curriculum (SFT $\to$ DPO $\to$ GRPO), where GRPO directly supervises tool usage beyond answer-level feedback. Our contributions are two-fold: I. Dataset. The first tool-based safety reasoning dataset, comprising 31,654 examples (SFT 6k, DPO 18.6k, GRPO 6k) plus 1k held-out evaluation. II. Experiments. On Qwen2.5-VL, SaFeR-ToolKit significantly improves Safety/Helpfulness/Reasoning Rigor on 3B (29.39/45.04/4.98 $\to$ 84.40/71.13/78.87) and 7B (53.21/52.92/19.26 $\to$ 86.34/80.79/85.34), while preserving general capabilities (3B: 58.67 $\to$ 59.21; 7B: 66.39 $\to$ 66.81). Codes are available at https://github.com/Duebassx/SaFeR_ToolKit.
Diagnosing Knowledge Conflict in Multimodal Long-Chain Reasoning
Feb 16, 2026Multimodal large language models (MLLMs) in long chain-of-thought reasoning often fail when different knowledge sources provide conflicting signals. We formalize these failures under a unified notion of knowledge conflict, distinguishing input-level objective conflict from process-level effective conflict. Through probing internal representations, we reveal that: (I) Linear Separability: different conflict types are explicitly encoded as linearly separable features rather than entangled; (II) Depth Localization: conflict signals concentrate in mid-to-late layers, indicating a distinct processing stage for conflict encoding; (III) Hierarchical Consistency: aggregating noisy token-level signals along trajectories robustly recovers input-level conflict types; and (IV) Directional Asymmetry: reinforcing the model's implicit source preference under conflict is far easier than enforcing the opposite source. Our findings provide a mechanism-level view of multimodal reasoning under knowledge conflict and enable principled diagnosis and control of long-CoT failures.
StackingNet: Collective Inference Across Independent AI Foundation Models
Feb 14, 2026Artificial intelligence built on large foundation models has transformed language understanding, vision and reasoning, yet these systems remain isolated and cannot readily share their capabilities. Integrating the complementary strengths of such independent foundation models is essential for building trustworthy intelligent systems. Despite rapid progress in individual model design, there is no established approach for coordinating such black-box heterogeneous models. Here we show that coordination can be achieved through a meta-ensemble framework termed StackingNet, which draws on principles of collective intelligence to combine model predictions during inference. StackingNet improves accuracy, reduces bias, enables reliability ranking, and identifies or prunes models that degrade performance, all operating without access to internal parameters or training data. Across tasks involving language comprehension, visual estimation, and academic paper rating, StackingNet consistently improves accuracy, robustness, and fairness, compared with individual models and classic ensembles. By turning diversity from a source of inconsistency into collaboration, StackingNet establishes a practical foundation for coordinated artificial intelligence, suggesting that progress may emerge from not only larger single models but also principled cooperation among many specialized ones.
CSSBench: Evaluating the Safety of Lightweight LLMs against Chinese-Specific Adversarial Patterns
Jan 05, 2026Large language models (LLMs) are increasingly deployed in cost-sensitive and on-device scenarios, and safety guardrails have advanced mainly in English. However, real-world Chinese malicious queries typically conceal intent via homophones, pinyin, symbol-based splitting, and other Chinese-specific patterns. These Chinese-specific adversarial patterns create the safety evaluation gap that is not well captured by existing benchmarks focused on English. This gap is particularly concerning for lightweight models, which may be more vulnerable to such specific adversarial perturbations. To bridge this gap, we introduce the Chinese-Specific Safety Benchmark (CSSBench) that emphasizes these adversarial patterns and evaluates the safety of lightweight LLMs in Chinese. Our benchmark covers six domains that are common in real Chinese scenarios, including illegal activities and compliance, privacy leakage, health and medical misinformation, fraud and hate, adult content, and public and political safety, and organizes queries into multiple task types. We evaluate a set of popular lightweight LLMs and measure over-refusal behavior to assess safety-induced performance degradation. Our results show that the Chinese-specific adversarial pattern is a critical challenge for lightweight LLMs. This benchmark offers a comprehensive evaluation of LLM safety in Chinese, assisting robust deployments in practice.
HD3C: Efficient Medical Data Classification for Embedded Devices
Sep 18, 2025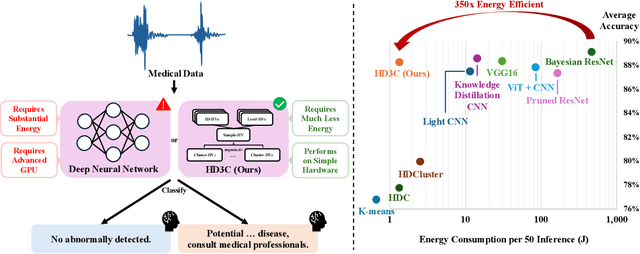
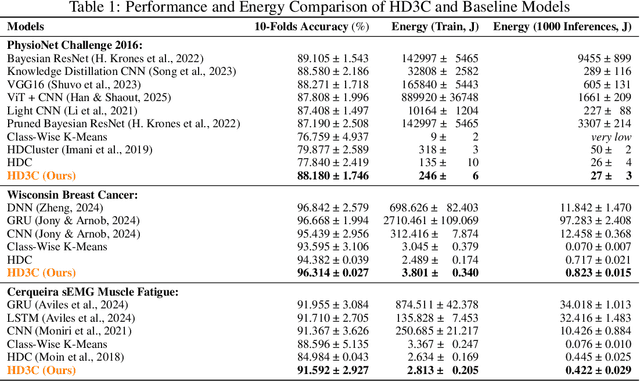
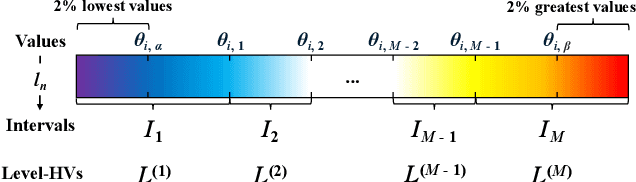
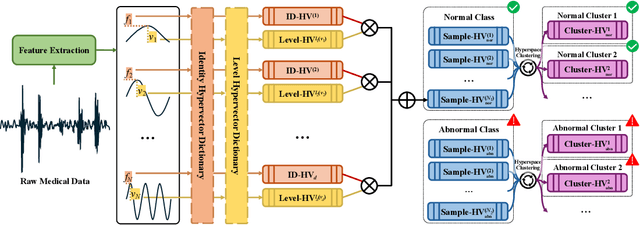
Energy-efficient medical data classification is essential for modern disease screening, particularly in home and field healthcare where embedded devices are prevalent. While deep learning models achieve state-of-the-art accuracy, their substantial energy consumption and reliance on GPUs limit deployment on such platforms. We present Hyperdimensional Computing with Class-Wise Clustering (HD3C), a lightweight classification framework designed for low-power environments. HD3C encodes data into high-dimensional hypervectors, aggregates them into multiple cluster-specific prototypes, and performs classification through similarity search in hyperspace. We evaluate HD3C across three medical classification tasks; on heart sound classification, HD3C is $350\times$ more energy-efficient than Bayesian ResNet with less than 1% accuracy difference. Moreover, HD3C demonstrates exceptional robustness to noise, limited training data, and hardware error, supported by both theoretical analysis and empirical results, highlighting its potential for reliable deployment in real-world settings. Code is available at https://github.com/jianglanwei/HD3C.
Breaking Free from MMI: A New Frontier in Rationalization by Probing Input Utilization
Mar 08, 2025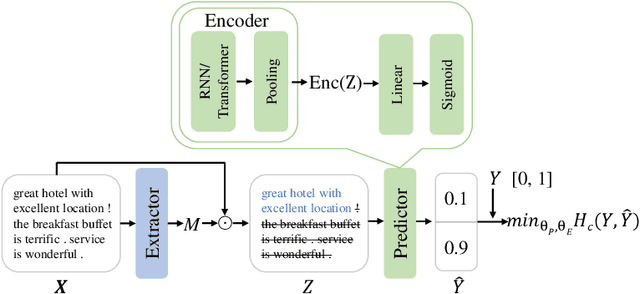

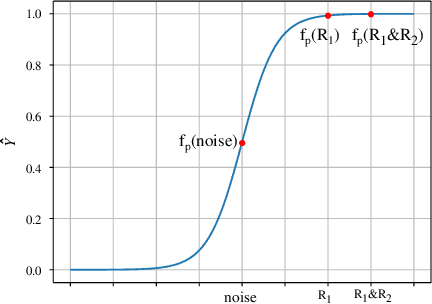

Extracting a small subset of crucial rationales from the full input is a key problem in explainability research. The most widely used fundamental criterion for rationale extraction is the maximum mutual information (MMI) criterion. In this paper, we first demonstrate that MMI suffers from diminishing marginal returns. Once part of the rationale has been identified, finding the remaining portions contributes only marginally to increasing the mutual information, making it difficult to use MMI to locate the rest. In contrast to MMI that aims to reproduce the prediction, we seek to identify the parts of the input that the network can actually utilize. This is achieved by comparing how different rationale candidates match the capability space of the weight matrix. The weight matrix of a neural network is typically low-rank, meaning that the linear combinations of its column vectors can only cover part of the directions in a high-dimensional space (high-dimension: the dimensions of an input vector). If an input is fully utilized by the network, {it generally matches these directions (e.g., a portion of a hypersphere), resulting in a representation with a high norm. Conversely, if an input primarily falls outside (orthogonal to) these directions}, its representation norm will approach zero, behaving like noise that the network cannot effectively utilize. Building on this, we propose using the norms of rationale candidates as an alternative objective to MMI. Through experiments on four text classification datasets and one graph classification dataset using three network architectures (GRUs, BERT, and GCN), we show that our method outperforms MMI and its improved variants in identifying better rationales. We also compare our method with a representative LLM (llama-3.1-8b-instruct) and find that our simple method gets comparable results to it and can sometimes even outperform it.
Tracing Intricate Cues in Dialogue: Joint Graph Structure and Sentiment Dynamics for Multimodal Emotion Recognition
Jul 31, 2024



Multimodal emotion recognition in conversation (MERC) has garnered substantial research attention recently. Existing MERC methods face several challenges: (1) they fail to fully harness direct inter-modal cues, possibly leading to less-than-thorough cross-modal modeling; (2) they concurrently extract information from the same and different modalities at each network layer, potentially triggering conflicts from the fusion of multi-source data; (3) they lack the agility required to detect dynamic sentimental changes, perhaps resulting in inaccurate classification of utterances with abrupt sentiment shifts. To address these issues, a novel approach named GraphSmile is proposed for tracking intricate emotional cues in multimodal dialogues. GraphSmile comprises two key components, i.e., GSF and SDP modules. GSF ingeniously leverages graph structures to alternately assimilate inter-modal and intra-modal emotional dependencies layer by layer, adequately capturing cross-modal cues while effectively circumventing fusion conflicts. SDP is an auxiliary task to explicitly delineate the sentiment dynamics between utterances, promoting the model's ability to distinguish sentimental discrepancies. Furthermore, GraphSmile is effortlessly applied to multimodal sentiment analysis in conversation (MSAC), forging a unified multimodal affective model capable of executing MERC and MSAC tasks. Empirical results on multiple benchmarks demonstrate that GraphSmile can handle complex emotional and sentimental patterns, significantly outperforming baseline models.
Harnessing Neural Unit Dynamics for Effective and Scalable Class-Incremental Learning
Jun 04, 2024Class-incremental learning (CIL) aims to train a model to learn new classes from non-stationary data streams without forgetting old ones. In this paper, we propose a new kind of connectionist model by tailoring neural unit dynamics that adapt the behavior of neural networks for CIL. In each training session, it introduces a supervisory mechanism to guide network expansion whose growth size is compactly commensurate with the intrinsic complexity of a newly arriving task. This constructs a near-minimal network while allowing the model to expand its capacity when cannot sufficiently hold new classes. At inference time, it automatically reactivates the required neural units to retrieve knowledge and leaves the remaining inactivated to prevent interference. We name our model AutoActivator, which is effective and scalable. To gain insights into the neural unit dynamics, we theoretically analyze the model's convergence property via a universal approximation theorem on learning sequential mappings, which is under-explored in the CIL community. Experiments show that our method achieves strong CIL performance in rehearsal-free and minimal-expansion settings with different backbones.
Towards Continual Learning Desiderata via HSIC-Bottleneck Orthogonalization and Equiangular Embedding
Jan 17, 2024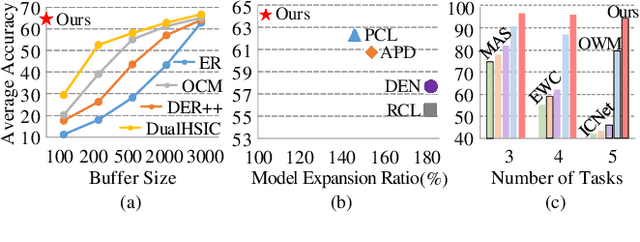
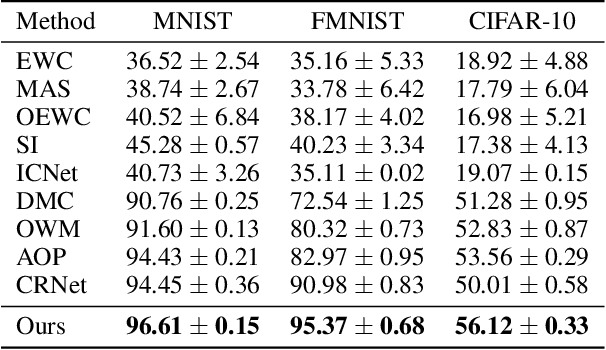
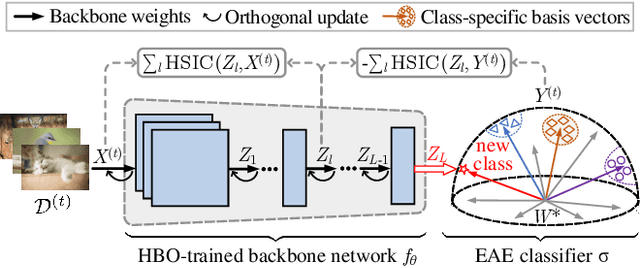

Deep neural networks are susceptible to catastrophic forgetting when trained on sequential tasks. Various continual learning (CL) methods often rely on exemplar buffers or/and network expansion for balancing model stability and plasticity, which, however, compromises their practical value due to privacy and memory concerns. Instead, this paper considers a strict yet realistic setting, where the training data from previous tasks is unavailable and the model size remains relatively constant during sequential training. To achieve such desiderata, we propose a conceptually simple yet effective method that attributes forgetting to layer-wise parameter overwriting and the resulting decision boundary distortion. This is achieved by the synergy between two key components: HSIC-Bottleneck Orthogonalization (HBO) implements non-overwritten parameter updates mediated by Hilbert-Schmidt independence criterion in an orthogonal space and EquiAngular Embedding (EAE) enhances decision boundary adaptation between old and new tasks with predefined basis vectors. Extensive experiments demonstrate that our method achieves competitive accuracy performance, even with absolute superiority of zero exemplar buffer and 1.02x the base model.