 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Discrimination and Consistency for Exemplar-Free Class Incremental Learning
Jan 26, 2025



Exemplar-free class incremental learning (EF-CIL) is a nontrivial task that requires continuously enriching model capability with new classes while maintaining previously learned knowledge without storing and replaying any old class exemplars. An emerging theory-guided framework for CIL trains task-specific models for a shared network, shifting the pressure of forgetting to task-id prediction. In EF-CIL, task-id prediction is more challenging due to the lack of inter-task interaction (e.g., replays of exemplars). To address this issue, we conduct a theoretical analysis of the importance and feasibility of preserving a discriminative and consistent feature space, upon which we propose a novel method termed DCNet. Concretely, it progressively maps class representations into a hyperspherical space, in which different classes are orthogonally distributed to achieve ample inter-class separation. Meanwhile, it also introduces compensatory training to adaptively adjust supervision intensity, thereby aligning the degree of intra-class aggregation. Extensive experiments and theoretical analysis verified the superiority of the proposed DCNet.
Harnessing Neural Unit Dynamics for Effective and Scalable Class-Incremental Learning
Jun 04, 2024Class-incremental learning (CIL) aims to train a model to learn new classes from non-stationary data streams without forgetting old ones. In this paper, we propose a new kind of connectionist model by tailoring neural unit dynamics that adapt the behavior of neural networks for CIL. In each training session, it introduces a supervisory mechanism to guide network expansion whose growth size is compactly commensurate with the intrinsic complexity of a newly arriving task. This constructs a near-minimal network while allowing the model to expand its capacity when cannot sufficiently hold new classes. At inference time, it automatically reactivates the required neural units to retrieve knowledge and leaves the remaining inactivated to prevent interference. We name our model AutoActivator, which is effective and scalable. To gain insights into the neural unit dynamics, we theoretically analyze the model's convergence property via a universal approximation theorem on learning sequential mappings, which is under-explored in the CIL community. Experiments show that our method achieves strong CIL performance in rehearsal-free and minimal-expansion settings with different backbones.
Towards Continual Learning Desiderata via HSIC-Bottleneck Orthogonalization and Equiangular Embedding
Jan 17, 2024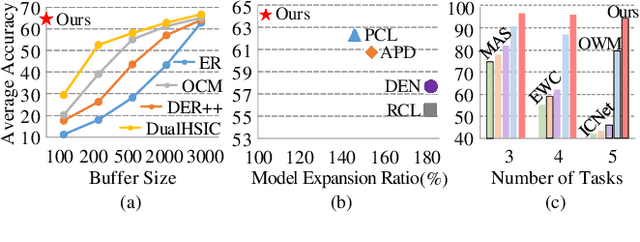
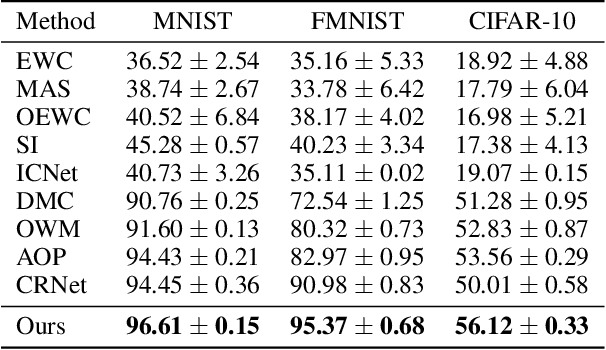
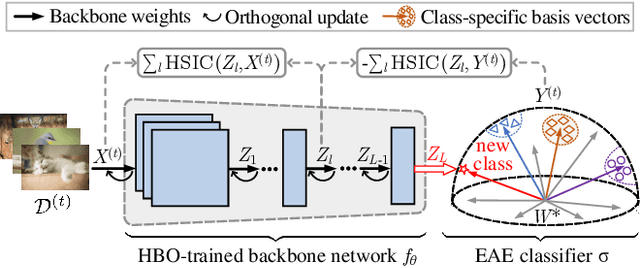

Deep neural networks are susceptible to catastrophic forgetting when trained on sequential tasks. Various continual learning (CL) methods often rely on exemplar buffers or/and network expansion for balancing model stability and plasticity, which, however, compromises their practical value due to privacy and memory concerns. Instead, this paper considers a strict yet realistic setting, where the training data from previous tasks is unavailable and the model size remains relatively constant during sequential training. To achieve such desiderata, we propose a conceptually simple yet effective method that attributes forgetting to layer-wise parameter overwriting and the resulting decision boundary distortion. This is achieved by the synergy between two key components: HSIC-Bottleneck Orthogonalization (HBO) implements non-overwritten parameter updates mediated by Hilbert-Schmidt independence criterion in an orthogonal space and EquiAngular Embedding (EAE) enhances decision boundary adaptation between old and new tasks with predefined basis vectors. Extensive experiments demonstrate that our method achieves competitive accuracy performance, even with absolute superiority of zero exemplar buffer and 1.02x the base model.
Complementary Learning Subnetworks for Parameter-Efficient Class-Incremental Learning
Jun 21, 2023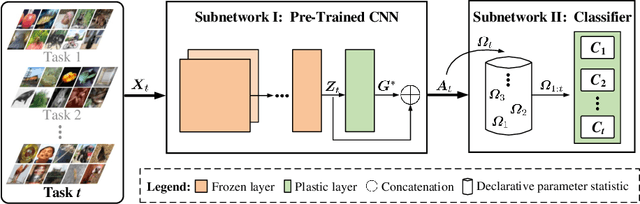
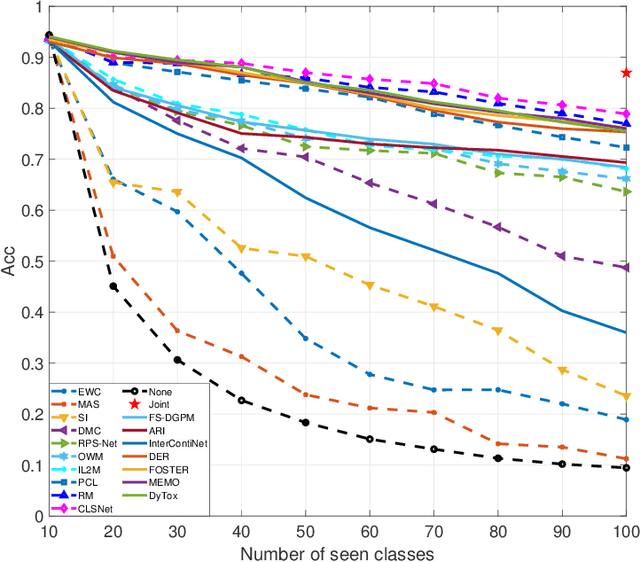

In the scenario of class-incremental learning (CIL), deep neural networks have to adapt their model parameters to non-stationary data distributions, e.g., the emergence of new classes over time. However, CIL models are challenged by the well-known catastrophic forgetting phenomenon. Typical methods such as rehearsal-based ones rely on storing exemplars of old classes to mitigate catastrophic forgetting, which limits real-world applications considering memory resources and privacy issues. In this paper, we propose a novel rehearsal-free CIL approach that learns continually via the synergy between two Complementary Learning Subnetworks. Our approach involves jointly optimizing a plastic CNN feature extractor and an analytical feed-forward classifier. The inaccessibility of historical data is tackled by holistically controlling the parameters of a well-trained model, ensuring that the decision boundary learned fits new classes while retaining recognition of previously learned classes. Specifically, the trainable CNN feature extractor provides task-dependent knowledge separately without interference; and the final classifier integrates task-specific knowledge incrementally for decision-making without forgetting. In each CIL session, it accommodates new tasks by attaching a tiny set of declarative parameters to its backbone, in which only one matrix per task or one vector per class is kept for knowledge retention. Extensive experiments on a variety of task sequences show that our method achieves competitive results against state-of-the-art methods, especially in accuracy gain, memory cost, training efficiency, and task-order robustness. Furthermore, to make the non-growing backbone (i.e., a model with limited network capacity) suffice to train on more incoming tasks, a graceful forgetting implementation on previously learned trivial tasks is empirically investigated.
IF2Net: Innately Forgetting-Free Networks for Continual Learning
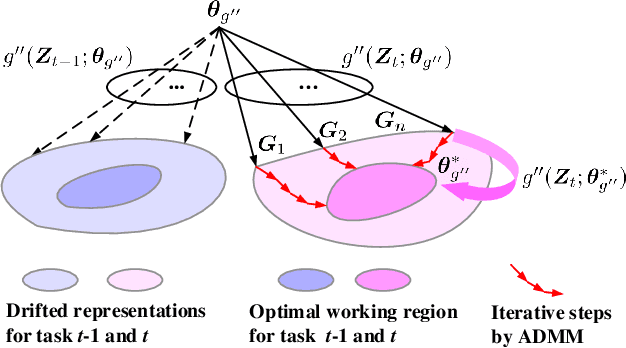
Jun 18, 2023Continual learning can incrementally absorb new concepts without interfering with previously learned knowledge. Motivated by the characteristics of neural networks, in which information is stored in weights on connections, we investigated how to design an Innately Forgetting-Free Network (IF2Net) for continual learning context. This study proposed a straightforward yet effective learning paradigm by ingeniously keeping the weights relative to each seen task untouched before and after learning a new task. We first presented the novel representation-level learning on task sequences with random weights. This technique refers to tweaking the drifted representations caused by randomization back to their separate task-optimal working states, but the involved weights are frozen and reused (opposite to well-known layer-wise updates of weights). Then, sequential decision-making without forgetting can be achieved by projecting the output weight updates into the parsimonious orthogonal space, making the adaptations not disturb old knowledge while maintaining model plasticity. IF2Net allows a single network to inherently learn unlimited mapping rules without telling task identities at test time by integrating the respective strengths of randomization and orthogonalization. We validated the effectiveness of our approach in the extensive theoretical analysis and empirical study.
Multi-View Class Incremental Learning
Jun 16, 2023



Multi-view learning (MVL) has gained great success in integrating information from multiple perspectives of a dataset to improve downstream task performance. To make MVL methods more practical in an open-ended environment, this paper investigates a novel paradigm called multi-view class incremental learning (MVCIL), where a single model incrementally classifies new classes from a continual stream of views, requiring no access to earlier views of data. However, MVCIL is challenged by the catastrophic forgetting of old information and the interference with learning new concepts. To address this, we first develop a randomization-based representation learning technique serving for feature extraction to guarantee their separate view-optimal working states, during which multiple views belonging to a class are presented sequentially; Then, we integrate them one by one in the orthogonality fusion subspace spanned by the extracted features; Finally, we introduce selective weight consolidation for learning-without-forgetting decision-making while encountering new classes. Extensive experiments on synthetic and real-world datasets validate the effectiveness of our approach.