 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-SENet: CLIP-based Semantic Enhancement Network for Vehicle Re-identification
Feb 24, 2025Vehicle re-identification (Re-ID) is a crucial task in intelligent transportation systems (ITS), aimed at retrieving and matching the same vehicle across different surveillance cameras. Numerous studies have explored methods to enhance vehicle Re-ID by focusing on semantic enhancement. However, these methods often rely on additional annotated information to enable models to extract effective semantic features, which brings many limitations. In this work, we propose a CLIP-based Semantic Enhancement Network (CLIP-SENet), an end-to-end framework designed to autonomously extract and refine vehicle semantic attributes, facilitating the generation of more robust semantic feature representations. Inspired by zero-shot solutions for downstream tasks presented by large-scale vision-language models, we leverage the powerful cross-modal descriptive capabilities of the CLIP image encoder to initially extract general semantic information. Instead of using a text encoder for semantic alignment, we design an adaptive fine-grained enhancement module (AFEM) to adaptively enhance this general semantic information at a fine-grained level to obtain robust semantic feature representations. These features are then fused with common Re-ID appearance features to further refine the distinctions between vehicles. Our comprehensive evaluation on three benchmark datasets demonstrates the effectiveness of CLIP-SENet. Our approach achieves new state-of-the-art performance, with 92.9% mAP and 98.7% Rank-1 on VeRi-776 dataset, 90.4% Rank-1 and 98.7% Rank-5 on VehicleID dataset, and 89.1% mAP and 97.9% Rank-1 on the more challenging VeRi-Wild dataset.
A Fourier Transform Framework for Domain Adaptation
Mar 21, 2024



By using unsupervised domain adaptation (UDA), knowledge can be transferred from a label-rich source domain to a target domain that contains relevant information but lacks labels. Many existing UDA algorithms suffer from directly using raw images as input, resulting in models that overly focus on redundant information and exhibit poor generalization capability. To address this issue, we attempt to improve the performance of unsupervised domain adaptation by employing the Fourier method (FTF).Specifically, FTF is inspired by the amplitude of Fourier spectra, which primarily preserves low-level statistical information. In FTF, we effectively incorporate low-level information from the target domain into the source domain by fusing the amplitudes of both domains in the Fourier domain. Additionally, we observe that extracting features from batches of images can eliminate redundant information while retaining class-specific features relevant to the task. Building upon this observation, we apply the Fourier Transform at the data stream level for the first time. To further align multiple sources of data, we introduce the concept of correlation alignment. To evaluate the effectiveness of our FTF method, we conducted evaluations on four benchmark datasets for domain adaptation, including Office-31, Office-Home, ImageCLEF-DA, and Office-Caltech. Our results demonstrate superior performance.
IF2Net: Innately Forgetting-Free Networks for Continual Learning
Jun 18, 2023Continual learning can incrementally absorb new concepts without interfering with previously learned knowledge. Motivated by the characteristics of neural networks, in which information is stored in weights on connections, we investigated how to design an Innately Forgetting-Free Network (IF2Net) for continual learning context. This study proposed a straightforward yet effective learning paradigm by ingeniously keeping the weights relative to each seen task untouched before and after learning a new task. We first presented the novel representation-level learning on task sequences with random weights. This technique refers to tweaking the drifted representations caused by randomization back to their separate task-optimal working states, but the involved weights are frozen and reused (opposite to well-known layer-wise updates of weights). Then, sequential decision-making without forgetting can be achieved by projecting the output weight updates into the parsimonious orthogonal space, making the adaptations not disturb old knowledge while maintaining model plasticity. IF2Net allows a single network to inherently learn unlimited mapping rules without telling task identities at test time by integrating the respective strengths of randomization and orthogonalization. We validated the effectiveness of our approach in the extensive theoretical analysis and empirical study.
Towards Fair Knowledge Transfer for Imbalanced Domain Adaptation
Oct 23, 2020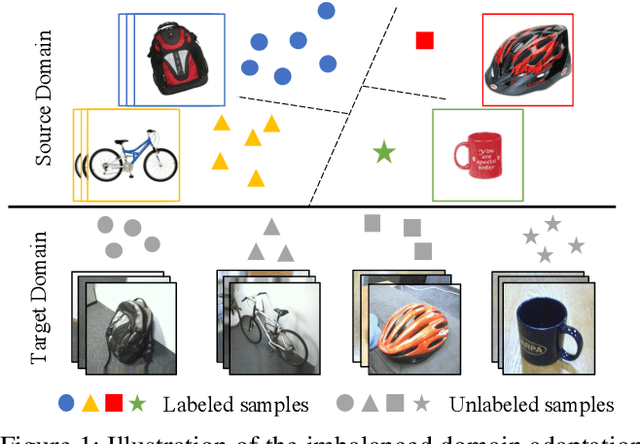


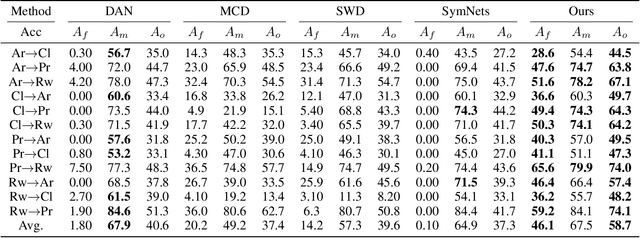
Domain adaptation (DA) becomes an up-and-coming technique to address the insufficient or no annotation issue by exploiting external source knowledge. Existing DA algorithms mainly focus on practical knowledge transfer through domain alignment. Unfortunately, they ignore the fairness issue when the auxiliary source is extremely imbalanced across different categories, which results in severe under-presented knowledge adaptation of minority source set. To this end, we propose a Towards Fair Knowledge Transfer (TFKT) framework to handle the fairness challenge in imbalanced cross-domain learning. Specifically, a novel cross-domain mixup generation is exploited to augment the minority source set with target information to enhance fairness. Moreover, dual distinct classifiers and cross-domain prototype alignment are developed to seek a more robust classifier boundary and mitigate the domain shift. Such three strategies are formulated into a unified framework to address the fairness issue and domain shift challenge. Extensive experiments over two popular benchmarks have verified the effectiveness of our proposed model by comparing to existing state-of-the-art DA models, and especially our model significantly improves over 20% on two benchmarks in terms of the overall accuracy.