 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRunning the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
Jun 12, 2026As agentic systems continue to evolve and are widely deployed in real-world scenarios, there is a growing demand to faithfully evaluate their capabilities. However, current benchmarks are typically built on popular applications with relatively simple tasks and focus on a narrow set of capabilities while overlooking broader dimensions, resulting in saturated performance on modern agents and failing to probe their limitations. To this end, we introduce GauntletBench, a web-based benchmark for evaluating agent generalisation in challenging scenarios, focusing on three underexplored capabilities (temporal perception, graphical understanding, and 3D reasoning), across five less-covered professional applications (Video Editor, Workflow Builder, 3D Modeller, Flight Analyser, and Circuit Designer), each with 20 vision-intensive tasks (100 in total). Our benchmark provides a modular pipeline that comprises an environment compatible with both open- and closed-source agent frameworks, a controlled web-based application, a well-structured task suite, and an automated evaluation engine with diverse metrics. Contrary to widespread expectations, our empirical results reveal that frontier agentic systems remain far from achieving human-level performance. Even the state-of-the-art agent achieves only a 19.1% success rate on our GauntletBench, highlighting the limitations in these overlooked capabilities and generalisation. By comparison, non-expert human annotators achieve over 80% success on our challenging yet feasible tasks, revealing the substantial gap between current agent capabilities and those required for complex real-world scenarios.
Grounding Text Embeddings in Stakeholder Associations
May 26, 2026Text embeddings are widely used to analyse large corpora of complex texts. However, it is unclear whether the embeddings capture the same semantic distances as the human experts using them. Ensuring alignment between embedding representations and human intentions is essential for valid analyses. We present the Stakeholder Grounding Exercise, a method for making expert associations explicit and grounding embedding model results in human understanding. In our primary case study on Danish policy issues, we find that neural text embeddings are substantially less reliable than human experts (19-26 pp gap), and that this misalignment propagates to downstream clustering performance (Spearman $ρ=0.9$ between exercise ranking and cluster quality). A secondary study on US Federal AI use cases replicates the gap (16pp) in English, using a digital protocol and a different community of experts -- demonstrating that the gap is not an artefact of a single instrument or domain. The Stakeholder Grounding Exercise offers a practical method for assessing whether embedding models capture the semantic distinctions that matter most to domain experts.
Flexi-LoRA with Input-Adaptive Ranks: Efficient Finetuning for Speech and Reasoning Tasks
May 03, 2026Parameter-efficient fine-tuning methods like Low-Rank Adaptation (LoRA) have become essential for deploying large language models, yet their static parameter allocation remains suboptimal for inputs of varying complexity. We present Flexi-LoRA, a novel framework that dynamically adjusts LoRA ranks based on input complexity during both training and inference. Through empirical analysis across question answering, mathematical reasoning, and speech tasks, we demonstrate that maintaining consistency between training and inference dynamics is important for effective adaptation, particularly for sequential reasoning tasks. Our findings reveal that input-dependent parameter allocation achieves higher performance with fewer parameters by optimally matching rank configurations to question complexity. Furthermore, task-specific dependency on rank dynamics varies, with mathematical reasoning tasks exhibiting higher dependency than QA tasks. Successful adaptation manifests not only in correctness but also in reasoning quality and instruction adherence. Flexi-LoRA consistently outperforms static LoRA while using fewer parameters, with performance gains more pronounced on tasks requiring strict reasoning chains. Our approach realizes key benefits of mixture-of-experts frameworks through a more streamlined implementation, reducing parameter redundancy while improving model capabilities. We provide comprehensive empirical studies across diverse tasks, establishing a basis for future work in input-adaptive and efficient fine-tuning approaches.
Evaluating the Ability of Explanations to Disambiguate Models in a Rashomon Set
Jan 13, 2026Explainable artificial intelligence (XAI) is concerned with producing explanations indicating the inner workings of models. For a Rashomon set of similarly performing models, explanations provide a way of disambiguating the behavior of individual models, helping select models for deployment. However explanations themselves can vary depending on the explainer used, and need to be evaluated. In the paper "Evaluating Model Explanations without Ground Truth", we proposed three principles of explanation evaluation and a new method "AXE" to evaluate the quality of feature-importance explanations. We go on to illustrate how evaluation metrics that rely on comparing model explanations against ideal ground truth explanations obscure behavioral differences within a Rashomon set. Explanation evaluation aligned with our proposed principles would highlight these differences instead, helping select models from the Rashomon set. The selection of alternate models from the Rashomon set can maintain identical predictions but mislead explainers into generating false explanations, and mislead evaluation methods into considering the false explanations to be of high quality. AXE, our proposed explanation evaluation method, can detect this adversarial fairwashing of explanations with a 100% success rate. Unlike prior explanation evaluation strategies such as those based on model sensitivity or ground truth comparison, AXE can determine when protected attributes are used to make predictions.
SCALPEL: Selective Capability Ablation via Low-rank Parameter Editing for Large Language Model Interpretability Analysis
Jan 12, 2026Large language models excel across diverse domains, yet their deployment in healthcare, legal systems, and autonomous decision-making remains limited by incomplete understanding of their internal mechanisms. As these models integrate into high-stakes systems, understanding how they encode capabilities has become fundamental to interpretability research. Traditional approaches identify important modules through gradient attribution or activation analysis, assuming specific capabilities map to specific components. However, this oversimplifies neural computation: modules may contribute to multiple capabilities simultaneously, while single capabilities may distribute across multiple modules. These coarse-grained analyses fail to capture fine-grained, distributed capability encoding. We present SCALPEL (Selective Capability Ablation via Low-rank Parameter Editing for Large language models), a framework representing capabilities as low-rank parameter subspaces rather than discrete modules. Our key insight is that capabilities can be characterized by low-rank modifications distributed across layers and modules, enabling precise capability removal without affecting others. By training LoRA adapters to reduce distinguishing correct from incorrect answers while preserving general language modeling quality, SCALPEL identifies low-rank representations responsible for particular capabilities while remaining disentangled from others. Experiments across diverse capability and linguistic tasks from BLiMP demonstrate that SCALPEL successfully removes target capabilities while preserving general capabilities, providing fine-grained insights into capability distribution across parameter space. Results reveal that capabilities exhibit low-rank structure and can be selectively ablated through targeted parameter-space interventions, offering nuanced understanding of capability encoding in LLMs.
OxEnsemble: Fair Ensembles for Low-Data Classification
Dec 10, 2025We address the problem of fair classification in settings where data is scarce and unbalanced across demographic groups. Such low-data regimes are common in domains like medical imaging, where false negatives can have fatal consequences. We propose a novel approach \emph{OxEnsemble} for efficiently training ensembles and enforcing fairness in these low-data regimes. Unlike other approaches, we aggregate predictions across ensemble members, each trained to satisfy fairness constraints. By construction, \emph{OxEnsemble} is both data-efficient, carefully reusing held-out data to enforce fairness reliably, and compute-efficient, requiring little more compute than used to fine-tune or evaluate an existing model. We validate this approach with new theoretical guarantees. Experimentally, our approach yields more consistent outcomes and stronger fairness-accuracy trade-offs than existing methods across multiple challenging medical imaging classification datasets.
CAST: Compositional Analysis via Spectral Tracking for Understanding Transformer Layer Functions
Oct 16, 2025Large language models have achieved remarkable success but remain largely black boxes with poorly understood internal mechanisms. To address this limitation, many researchers have proposed various interpretability methods including mechanistic analysis, probing classifiers, and activation visualization, each providing valuable insights from different perspectives. Building upon this rich landscape of complementary approaches, we introduce CAST (Compositional Analysis via Spectral Tracking), a probe-free framework that contributes a novel perspective by analyzing transformer layer functions through direct transformation matrix estimation and comprehensive spectral analysis. CAST offers complementary insights to existing methods by estimating the realized transformation matrices for each layer using Moore-Penrose pseudoinverse and applying spectral analysis with six interpretable metrics characterizing layer behavior. Our analysis reveals distinct behaviors between encoder-only and decoder-only models, with decoder models exhibiting compression-expansion cycles while encoder models maintain consistent high-rank processing. Kernel analysis further demonstrates functional relationship patterns between layers, with CKA similarity matrices clearly partitioning layers into three phases: feature extraction, compression, and specialization.
Evaluating Model Explanations without Ground Truth
May 15, 2025There can be many competing and contradictory explanations for a single model prediction, making it difficult to select which one to use. Current explanation evaluation frameworks measure quality by comparing against ideal "ground-truth" explanations, or by verifying model sensitivity to important inputs. We outline the limitations of these approaches, and propose three desirable principles to ground the future development of explanation evaluation strategies for local feature importance explanations. We propose a ground-truth Agnostic eXplanation Evaluation framework (AXE) for evaluating and comparing model explanations that satisfies these principles. Unlike prior approaches, AXE does not require access to ideal ground-truth explanations for comparison, or rely on model sensitivity - providing an independent measure of explanation quality. We verify AXE by comparing with baselines, and show how it can be used to detect explanation fairwashing. Our code is available at https://github.com/KaiRawal/Evaluating-Model-Explanations-without-Ground-Truth.
CLIP-SENet: CLIP-based Semantic Enhancement Network for Vehicle Re-identification
Feb 24, 2025Vehicle re-identification (Re-ID) is a crucial task in intelligent transportation systems (ITS), aimed at retrieving and matching the same vehicle across different surveillance cameras. Numerous studies have explored methods to enhance vehicle Re-ID by focusing on semantic enhancement. However, these methods often rely on additional annotated information to enable models to extract effective semantic features, which brings many limitations. In this work, we propose a CLIP-based Semantic Enhancement Network (CLIP-SENet), an end-to-end framework designed to autonomously extract and refine vehicle semantic attributes, facilitating the generation of more robust semantic feature representations. Inspired by zero-shot solutions for downstream tasks presented by large-scale vision-language models, we leverage the powerful cross-modal descriptive capabilities of the CLIP image encoder to initially extract general semantic information. Instead of using a text encoder for semantic alignment, we design an adaptive fine-grained enhancement module (AFEM) to adaptively enhance this general semantic information at a fine-grained level to obtain robust semantic feature representations. These features are then fused with common Re-ID appearance features to further refine the distinctions between vehicles. Our comprehensive evaluation on three benchmark datasets demonstrates the effectiveness of CLIP-SENet. Our approach achieves new state-of-the-art performance, with 92.9% mAP and 98.7% Rank-1 on VeRi-776 dataset, 90.4% Rank-1 and 98.7% Rank-5 on VehicleID dataset, and 89.1% mAP and 97.9% Rank-1 on the more challenging VeRi-Wild dataset.
Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective
Oct 16, 2023
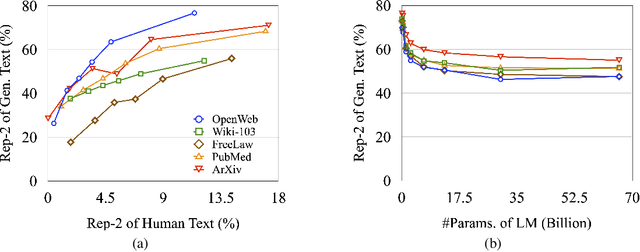
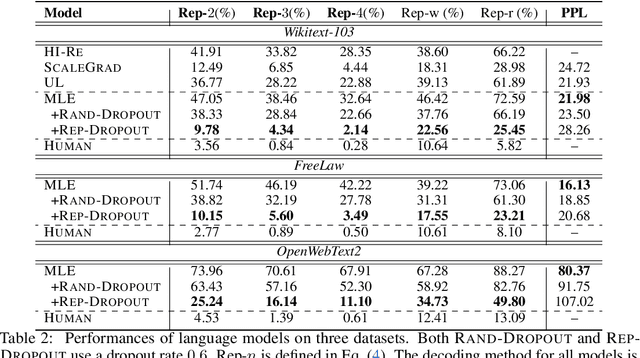
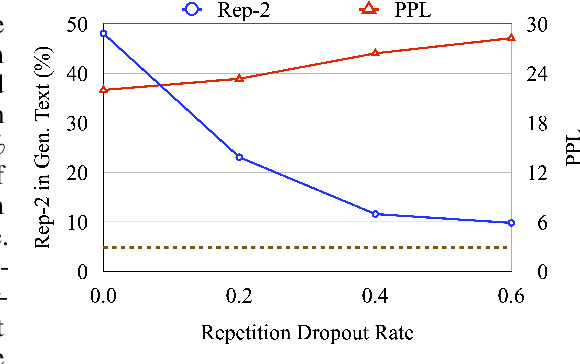
There are a number of diverging hypotheses about the neural text degeneration problem, i.e., generating repetitive and dull loops, which makes this problem both interesting and confusing. In this work, we aim to advance our understanding by presenting a straightforward and fundamental explanation from the data perspective. Our preliminary investigation reveals a strong correlation between the degeneration issue and the presence of repetitions in training data. Subsequent experiments also demonstrate that by selectively dropping out the attention to repetitive words in training data, degeneration can be significantly minimized. Furthermore, our empirical analysis illustrates that prior works addressing the degeneration issue from various standpoints, such as the high-inflow words, the likelihood objective, and the self-reinforcement phenomenon, can be interpreted by one simple explanation. That is, penalizing the repetitions in training data is a common and fundamental factor for their effectiveness. Moreover, our experiments reveal that penalizing the repetitions in training data remains critical even when considering larger model sizes and instruction tuning.