 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Deep Information Synthesis
Feb 24, 2026Large language model (LLM)-based agents are increasingly used to solve complex tasks involving tool use, such as web browsing, code execution, and data analysis. However, current evaluation benchmarks do not adequately assess their ability to solve real-world tasks that require synthesizing information from multiple sources and inferring insights beyond simple fact retrieval. To address this, we introduce DEEPSYNTH, a novel benchmark designed to evaluate agents on realistic, time-consuming problems that combine information gathering, synthesis, and structured reasoning to produce insights. DEEPSYNTH contains 120 tasks collected across 7 domains and data sources covering 67 countries. DEEPSYNTH is constructed using a multi-stage data collection pipeline that requires annotators to collect official data sources, create hypotheses, perform manual analysis, and design tasks with verifiable answers. When evaluated on DEEPSYNTH, 11 state-of-the-art LLMs and deep research agents achieve a maximum F1 score of 8.97 and 17.5 on the LLM-judge metric, underscoring the difficulty of the benchmark. Our analysis reveals that current agents struggle with hallucinations and reasoning over large information spaces, highlighting DEEPSYNTH as a crucial benchmark for guiding future research.
Failure Modes in Multi-Hop QA: The Weakest Link Law and the Recognition Bottleneck
Jan 18, 2026Despite scaling to massive context windows, Large Language Models (LLMs) struggle with multi-hop reasoning due to inherent position bias, which causes them to overlook information at certain positions. Whether these failures stem from an inability to locate evidence (recognition failure) or integrate it (synthesis failure) is unclear. We introduce Multi-Focus Attention Instruction (MFAI), a semantic probe to disentangle these mechanisms by explicitly steering attention towards selected positions. Across 5 LLMs on two multi-hop QA tasks (MuSiQue and NeoQA), we establish the "Weakest Link Law": multi-hop reasoning performance collapses to the performance level of the least visible evidence. Crucially, this failure is governed by absolute position rather than the linear distance between facts (performance variance $<3%$). We further identify a duality in attention steering: while matched MFAI resolves recognition bottlenecks, improving accuracy by up to 11.5% in low-visibility positions, misleading MFAI triggers confusion in real-world tasks but is successfully filtered in synthetic tasks. Finally, we demonstrate that "thinking" models that utilize System-2 reasoning, effectively locate and integrate the required information, matching gold-only baselines even in noisy, long-context settings.
Breaking Thought Patterns: A Multi-Dimensional Reasoning Framework for LLMs
Jun 16, 2025Large language models (LLMs) are often constrained by rigid reasoning processes, limiting their ability to generate creative and diverse responses. To address this, a novel framework called LADDER is proposed, combining Chain-of-Thought (CoT) reasoning, Mixture of Experts (MoE) models, and multi-dimensional up/down-sampling strategies which breaks the limitations of traditional LLMs. First, CoT reasoning guides the model through multi-step logical reasoning, expanding the semantic space and breaking the rigidity of thought. Next, MoE distributes the reasoning tasks across multiple expert modules, each focusing on specific sub-tasks. Finally, dimensionality reduction maps the reasoning outputs back to a lower-dimensional semantic space, yielding more precise and creative responses. Extensive experiments across multiple tasks demonstrate that LADDER significantly improves task completion, creativity, and fluency, generating innovative and coherent responses that outperform traditional models. Ablation studies reveal the critical roles of CoT and MoE in enhancing reasoning abilities and creative output. This work contributes to the development of more flexible and creative LLMs, capable of addressing complex and novel tasks.
Attention Instruction: Amplifying Attention in the Middle via Prompting
Jun 24, 2024



The context window of large language models has been extended to 128k tokens or more. However, language models still suffer from position bias and have difficulty in accessing and using the middle part of the context due to the lack of attention. We examine the relative position awareness of LLMs and the feasibility of mitigating disproportional attention through prompting. We augment the original task instruction with $\texttt{attention instructions}$ that direct language models to allocate more attention towards a selected segment of the context. We conduct a comprehensive investigation on multi-document question answering task with both position-based and index-based instructions. We find that language models do not have relative position awareness of the context. Nevertheless, they demonstrate the capacity to adapt attention to a specific segment using matching indexes. Our analysis contributes to a deeper understanding of position bias in LLMs and provides a pathway to mitigate this bias by instruction, thus benefiting LLMs in locating and utilizing relevant information from retrieved documents in RAG applications.
BAND: Biomedical Alert News Dataset
May 23, 2023
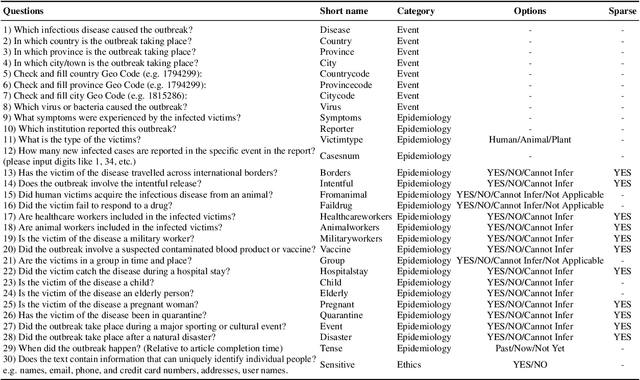
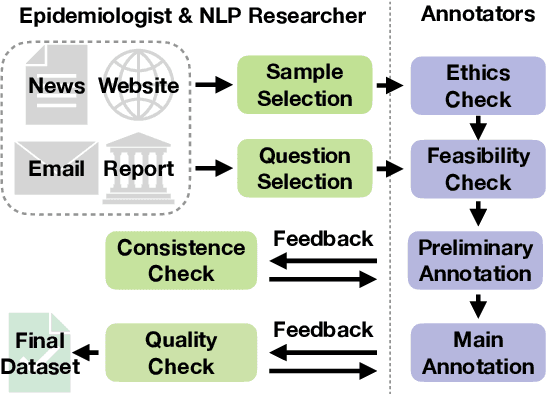
Infectious disease outbreaks continue to pose a significant threat to human health and well-being. To improve disease surveillance and understanding of disease spread, several surveillance systems have been developed to monitor daily news alerts and social media. However, existing systems lack thorough epidemiological analysis in relation to corresponding alerts or news, largely due to the scarcity of well-annotated reports data. To address this gap, we introduce the Biomedical Alert News Dataset (BAND), which includes 1,508 samples from existing reported news articles, open emails, and alerts, as well as 30 epidemiology-related questions. These questions necessitate the model's expert reasoning abilities, thereby offering valuable insights into the outbreak of the disease. The BAND dataset brings new challenges to the NLP world, requiring better disguise capability of the content and the ability to infer important information. We provide several benchmark tasks, including Named Entity Recognition (NER), Question Answering (QA), and Event Extraction (EE), to show how existing models are capable of handling these tasks in the epidemiology domain. To the best of our knowledge, the BAND corpus is the largest corpus of well-annotated biomedical outbreak alert news with elaborately designed questions, making it a valuable resource for epidemiologists and NLP researchers alike.
COFFEE: A Contrastive Oracle-Free Framework for Event Extraction
Mar 25, 2023



Event extraction is a complex information extraction task that involves extracting events from unstructured text. Prior classification-based methods require comprehensive entity annotations for joint training, while newer generation-based methods rely on heuristic templates containing oracle information such as event type, which is often unavailable in real-world scenarios. In this study, we consider a more realistic setting of this task, namely the Oracle-Free Event Extraction (OFEE) task, where only the input context is given without any oracle information, including event type, event ontology and trigger word. To solve this task, we propose a new framework, called COFFEE, which extracts the events solely based on the document context without referring to any oracle information. In particular, a contrastive selection model is introduced in COFFEE to rectify the generated triggers and handle multi-event instances. The proposed COFFEE outperforms state-of-the-art approaches under the oracle-free setting of the event extraction task, as evaluated on a public event extraction benchmark ACE05.
Multi-modal Active Learning From Human Data: A Deep Reinforcement Learning Approach
Jun 07, 2019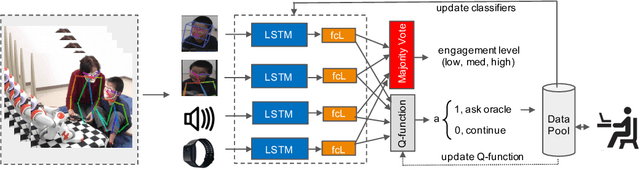


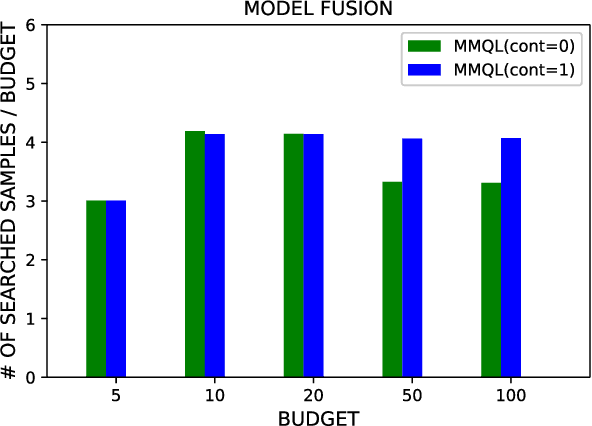
Human behavior expression and experience are inherently multi-modal, and characterized by vast individual and contextual heterogeneity. To achieve meaningful human-computer and human-robot interactions, multi-modal models of the users states (e.g., engagement) are therefore needed. Most of the existing works that try to build classifiers for the users states assume that the data to train the models are fully labeled. Nevertheless, data labeling is costly and tedious, and also prone to subjective interpretations by the human coders. This is even more pronounced when the data are multi-modal (e.g., some users are more expressive with their facial expressions, some with their voice). Thus, building models that can accurately estimate the users states during an interaction is challenging. To tackle this, we propose a novel multi-modal active learning (AL) approach that uses the notion of deep reinforcement learning (RL) to find an optimal policy for active selection of the users data, needed to train the target (modality-specific) models. We investigate different strategies for multi-modal data fusion, and show that the proposed model-level fusion coupled with RL outperforms the feature-level and modality-specific models, and the naive AL strategies such as random sampling, and the standard heuristics such as uncertainty sampling. We show the benefits of this approach on the task of engagement estimation from real-world child-robot interactions during an autism therapy. Importantly, we show that the proposed multi-modal AL approach can be used to efficiently personalize the engagement classifiers to the target user using a small amount of actively selected users data.