 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Ability of Explanations to Disambiguate Models in a Rashomon Set
Jan 13, 2026Explainable artificial intelligence (XAI) is concerned with producing explanations indicating the inner workings of models. For a Rashomon set of similarly performing models, explanations provide a way of disambiguating the behavior of individual models, helping select models for deployment. However explanations themselves can vary depending on the explainer used, and need to be evaluated. In the paper "Evaluating Model Explanations without Ground Truth", we proposed three principles of explanation evaluation and a new method "AXE" to evaluate the quality of feature-importance explanations. We go on to illustrate how evaluation metrics that rely on comparing model explanations against ideal ground truth explanations obscure behavioral differences within a Rashomon set. Explanation evaluation aligned with our proposed principles would highlight these differences instead, helping select models from the Rashomon set. The selection of alternate models from the Rashomon set can maintain identical predictions but mislead explainers into generating false explanations, and mislead evaluation methods into considering the false explanations to be of high quality. AXE, our proposed explanation evaluation method, can detect this adversarial fairwashing of explanations with a 100% success rate. Unlike prior explanation evaluation strategies such as those based on model sensitivity or ground truth comparison, AXE can determine when protected attributes are used to make predictions.
Evaluating Model Explanations without Ground Truth
May 15, 2025There can be many competing and contradictory explanations for a single model prediction, making it difficult to select which one to use. Current explanation evaluation frameworks measure quality by comparing against ideal "ground-truth" explanations, or by verifying model sensitivity to important inputs. We outline the limitations of these approaches, and propose three desirable principles to ground the future development of explanation evaluation strategies for local feature importance explanations. We propose a ground-truth Agnostic eXplanation Evaluation framework (AXE) for evaluating and comparing model explanations that satisfies these principles. Unlike prior approaches, AXE does not require access to ideal ground-truth explanations for comparison, or rely on model sensitivity - providing an independent measure of explanation quality. We verify AXE by comparing with baselines, and show how it can be used to detect explanation fairwashing. Our code is available at https://github.com/KaiRawal/Evaluating-Model-Explanations-without-Ground-Truth.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Learning Recourse Costs from Pairwise Feature Comparisons
Sep 20, 2024This paper presents a novel technique for incorporating user input when learning and inferring user preferences. When trying to provide users of black-box machine learning models with actionable recourse, we often wish to incorporate their personal preferences about the ease of modifying each individual feature. These recourse finding algorithms usually require an exhaustive set of tuples associating each feature to its cost of modification. Since it is hard to obtain such costs by directly surveying humans, in this paper, we propose the use of the Bradley-Terry model to automatically infer feature-wise costs using non-exhaustive human comparison surveys. We propose that users only provide inputs comparing entire recourses, with all candidate feature modifications, determining which recourses are easier to implement relative to others, without explicit quantification of their costs. We demonstrate the efficient learning of individual feature costs using MAP estimates, and show that these non-exhaustive human surveys, which do not necessarily contain data for each feature pair comparison, are sufficient to learn an exhaustive set of feature costs, where each feature is associated with a modification cost.
Can I Still Trust You?: Understanding the Impact of Distribution Shifts on Algorithmic Recourses
Dec 22, 2020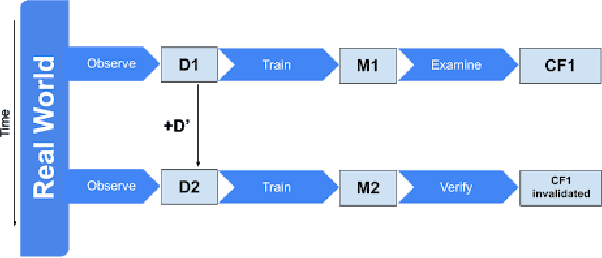
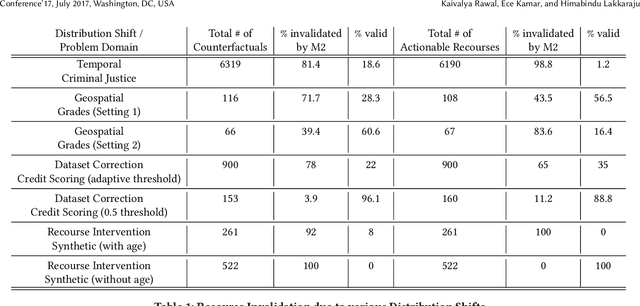
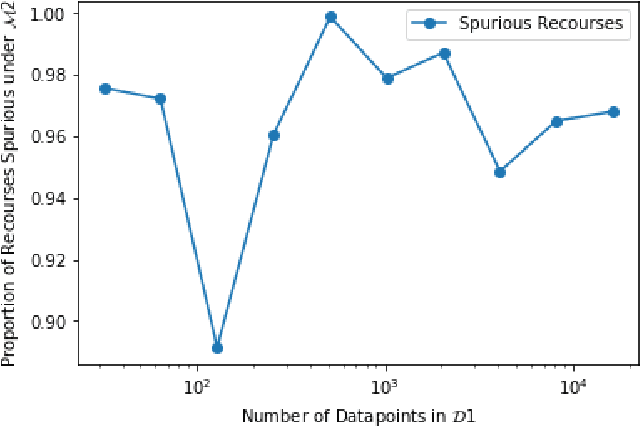
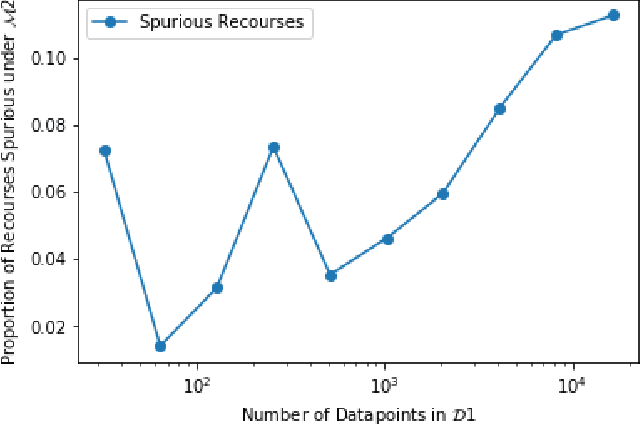
As predictive models are being increasingly deployed to make a variety of consequential decisions ranging from hiring decisions to loan approvals, there is growing emphasis on designing algorithms that can provide reliable recourses to affected individuals. To this end, several recourse generation algorithms have been proposed in recent literature. However, there is little to no work on systematically assessing if these algorithms are actually generating recourses that are reliable. In this work, we assess the reliability of algorithmic recourses through the lens of distribution shifts i.e., we empirically and theoretically study if and what kind of recourses generated by state-of-the-art algorithms are robust to distribution shifts. To the best of our knowledge, this work makes the first attempt at addressing this critical question. We experiment with multiple synthetic and real world datasets capturing different kinds of distribution shifts including temporal shifts, geospatial shifts, and shifts due to data corrections. Our results demonstrate that all the aforementioned distribution shifts could potentially invalidate the recourses generated by state-of-the-art algorithms. In addition, we also find that recourse interventions themselves may cause distribution shifts which in turn invalidate previously prescribed recourses. Our theoretical results establish that the recourses (counterfactuals) that are close to the model decision boundary are more likely to be invalidated upon model updation. However, state-of-the-art algorithms tend to prefer exactly these recourses because their cost functions penalize recourses (counterfactuals) that require large modifications to the original instance. Our findings not only expose fundamental flaws in recourse finding strategies but also pave new way for rethinking the design and development of recourse generation algorithms.
Interpretable and Interactive Summaries of Actionable Recourses
Sep 16, 2020

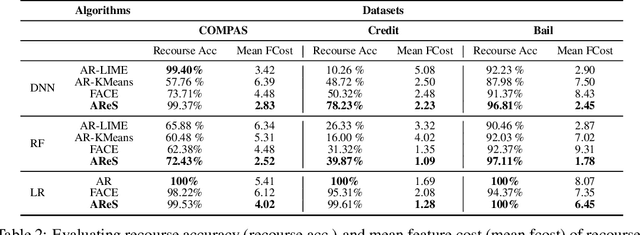
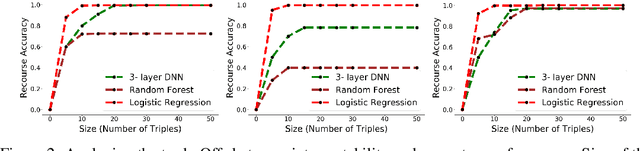
As predictive models are increasingly being deployed in high-stakes decision-making, there has been a lot of interest in developing algorithms which can provide recourses to affected individuals. While developing such tools is important, it is even more critical to analyse and interpret a predictive model, and vet it thoroughly to ensure that the recourses it offers are meaningful and non-discriminatory before it is deployed in the real world. To this end, we propose a novel model agnostic framework called Actionable Recourse Summaries (AReS) to construct global counterfactual explanations which provide an interpretable and accurate summary of recourses for the entire population. We formulate a novel objective which simultaneously optimizes for correctness of the recourses and interpretability of the explanations, while minimizing overall recourse costs across the entire population. More specifically, our objective enables us to learn, with optimality guarantees on recourse correctness, a small number of compact rule sets each of which capture recourses for well defined subpopulations within the data. Our framework is also interactive i.e., it allows users to input specific features of interest which will in turn be used to characterize subpopulations when generating recourse summaries. We also demonstrate theoretically that several of the prior approaches proposed to generate recourses for individuals are special cases of our framework. Experimental evaluation with real world datasets and user studies demonstrate that our framework can provide decision makers with a comprehensive overview of recourses corresponding to any black box model, and consequently help detect undesirable model biases and discrimination.