 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformative Text Generation from Knowledge Triples
Paper and Code
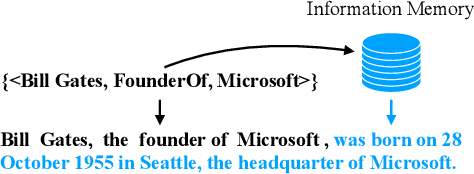

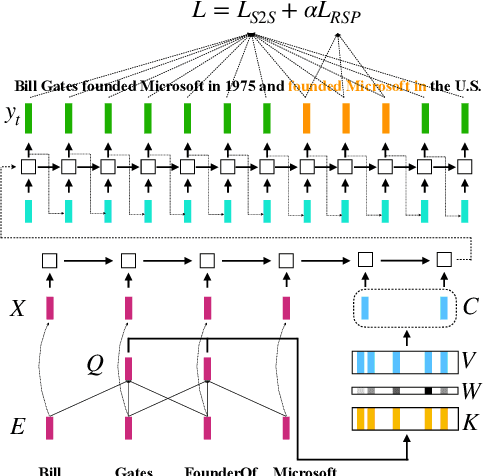
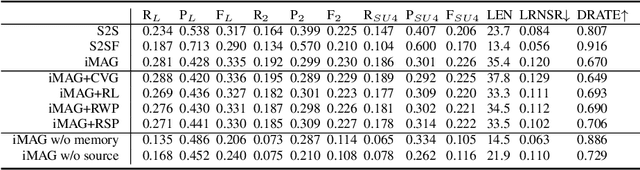
As the development of the encoder-decoder architecture, researchers are able to study the text generation tasks with broader types of data. Among them, KB-to-text aims at converting a set of knowledge triples into human readable sentences. In the original setting, the task assumes that the input triples and the text are exactly aligned in the perspective of the embodied knowledge/information. In this paper, we extend this setting and explore how to facilitate the trained model to generate more informative text, namely, containing more information about the triple entities but not conveyed by the input triples. To solve this problem, we propose a novel memory augmented generator that employs a memory network to memorize the useful knowledge learned during the training and utilizes such information together with the input triples to generate text in the operational or testing phase. We derive a dataset from WebNLG for our new setting and conduct extensive experiments to investigate the effectiveness of our model as well as uncover the intrinsic characteristics of the setting.