 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue of Information: A Framework for Human-Agent Communication
Jan 10, 2026Large Language Model (LLM) agents deployed for real-world tasks face a fundamental dilemma: user requests are underspecified, yet agents must decide whether to act on incomplete information or interrupt users for clarification. Existing approaches either rely on brittle confidence thresholds that require task-specific tuning, or fail to account for the varying stakes of different decisions. We introduce a decision-theoretic framework that resolves this trade-off through the Value of Information (VoI), enabling agents to dynamically weigh the expected utility gain from asking questions against the cognitive cost imposed on users. Our inference-time method requires no hyperparameter tuning and adapts seamlessly across contexts-from casual games to medical diagnosis. Experiments across four diverse domains (20 Questions, medical diagnosis, flight booking, and e-commerce) show that VoI consistently matches or exceeds the best manually-tuned baselines, achieving up to 1.36 utility points higher in high-cost settings. This work provides a parameter-free framework for adaptive agent communication that explicitly balances task risk, query ambiguity, and user effort.
Steer Model beyond Assistant: Controlling System Prompt Strength via Contrastive Decoding
Jan 10, 2026Large language models excel at complex instructions yet struggle to deviate from their helpful assistant persona, as post-training instills strong priors that resist conflicting instructions. We introduce system prompt strength, a training-free method that treats prompt adherence as a continuous control. By contrasting logits from target and default system prompts, we isolate and amplify the behavioral signal unique to the target persona by a scalar factor alpha. Across five diverse benchmarks spanning constraint satisfaction, behavioral control, pluralistic alignment, capability modulation, and stylistic control, our method yields substantial improvements: up to +8.5 strict accuracy on IFEval, +45pp refusal rate on OffTopicEval, and +13% steerability on Prompt-Steering. Our approach enables practitioners to modulate system prompt strength, providing dynamic control over model behavior without retraining.
Confidence Estimation for LLMs in Multi-turn Interactions
Jan 05, 2026While confidence estimation is a promising direction for mitigating hallucinations in Large Language Models (LLMs), current research dominantly focuses on single-turn settings. The dynamics of model confidence in multi-turn conversations, where context accumulates and ambiguity is progressively resolved, remain largely unexplored. Reliable confidence estimation in multi-turn settings is critical for many downstream applications, such as autonomous agents and human-in-the-loop systems. This work presents the first systematic study of confidence estimation in multi-turn interactions, establishing a formal evaluation framework grounded in two key desiderata: per-turn calibration and monotonicity of confidence as more information becomes available. To facilitate this, we introduce novel metrics, including a length-normalized Expected Calibration Error (InfoECE), and a new "Hinter-Guesser" paradigm for generating controlled evaluation datasets. Our experiments reveal that widely-used confidence techniques struggle with calibration and monotonicity in multi-turn dialogues. We propose P(Sufficient), a logit-based probe that achieves comparatively better performance, although the task remains far from solved. Our work provides a foundational methodology for developing more reliable and trustworthy conversational agents.
When Personalization Meets Reality: A Multi-Faceted Analysis of Personalized Preference Learning
Feb 26, 2025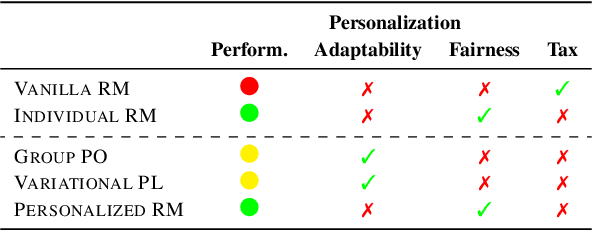
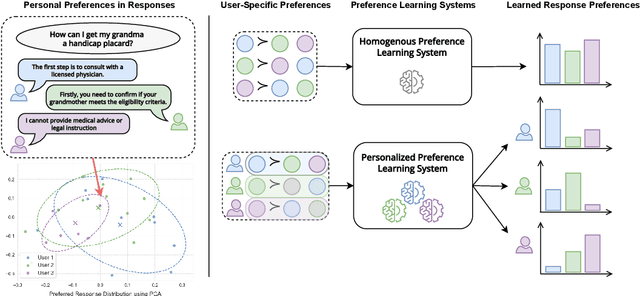

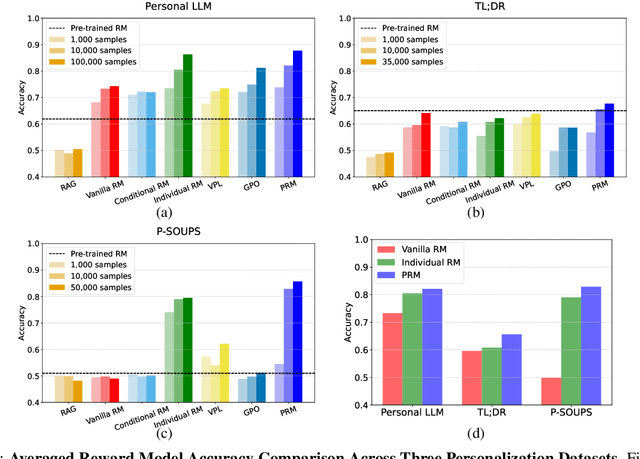
While Reinforcement Learning from Human Feedback (RLHF) is widely used to align Large Language Models (LLMs) with human preferences, it typically assumes homogeneous preferences across users, overlooking diverse human values and minority viewpoints. Although personalized preference learning addresses this by tailoring separate preferences for individual users, the field lacks standardized methods to assess its effectiveness. We present a multi-faceted evaluation framework that measures not only performance but also fairness, unintended effects, and adaptability across varying levels of preference divergence. Through extensive experiments comparing eight personalization methods across three preference datasets, we demonstrate that performance differences between methods could reach 36% when users strongly disagree, and personalization can introduce up to 20% safety misalignment. These findings highlight the critical need for holistic evaluation approaches to advance the development of more effective and inclusive preference learning systems.
Can LLM be a Personalized Judge?
Jun 17, 2024Ensuring that large language models (LLMs) reflect diverse user values and preferences is crucial as their user bases expand globally. It is therefore encouraging to see the growing interest in LLM personalization within the research community. However, current works often rely on the LLM-as-a-Judge approach for evaluation without thoroughly examining its validity. In this paper, we investigate the reliability of LLM-as-a-Personalized-Judge, asking LLMs to judge user preferences based on personas. Our findings suggest that directly applying LLM-as-a-Personalized-Judge is less reliable than previously assumed, showing low and inconsistent agreement with human ground truth. The personas typically used are often overly simplistic, resulting in low predictive power. To address these issues, we introduce verbal uncertainty estimation into the LLM-as-a-Personalized-Judge pipeline, allowing the model to express low confidence on uncertain judgments. This adjustment leads to much higher agreement (above 80%) on high-certainty samples for binary tasks. Through human evaluation, we find that the LLM-as-a-Personalized-Judge achieves comparable performance to third-party humans evaluation and even surpasses human performance on high-certainty samples. Our work indicates that certainty-enhanced LLM-as-a-Personalized-Judge offers a promising direction for developing more reliable and scalable methods for evaluating LLM personalization.
Unmemorization in Large Language Models via Self-Distillation and Deliberate Imagination
Feb 15, 2024



While displaying impressive generation capabilities across many tasks, Large Language Models (LLMs) still struggle with crucial issues of privacy violation and unwanted exposure of sensitive data. This raises an essential question: how should we prevent such undesired behavior of LLMs while maintaining their strong generation and natural language understanding (NLU) capabilities? In this work, we introduce a novel approach termed deliberate imagination in the context of LLM unlearning. Instead of trying to forget memorized data, we employ a self-distillation framework, guiding LLMs to deliberately imagine alternative scenarios. As demonstrated in a wide range of experiments, the proposed method not only effectively unlearns targeted text but also preserves the LLMs' capabilities in open-ended generation tasks as well as in NLU tasks. Our results demonstrate the usefulness of this approach across different models and sizes, and also with parameter-efficient fine-tuning, offering a novel pathway to addressing the challenges with private and sensitive data in LLM applications.
CORRPUS: Detecting Story Inconsistencies via Codex-Bootstrapped Neurosymbolic Reasoning
Dec 21, 2022


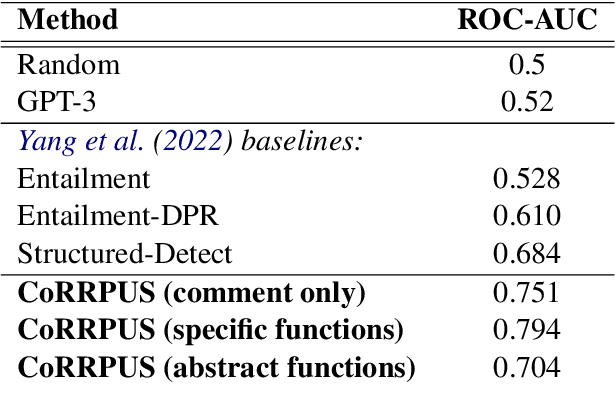
Story generation and understanding -- as with all NLG/NLU tasks -- has seen a surge in neurosymbolic work. Researchers have recognized that, while large language models (LLMs) have tremendous utility, they can be augmented with symbolic means to be even better and to make up for any flaws that the neural networks might have. However, symbolic methods are extremely costly in terms of the amount of time and expertise needed to create them. In this work, we capitalize on state-of-the-art Code-LLMs, such as Codex, to bootstrap the use of symbolic methods for tracking the state of stories and aiding in story understanding. We show that our CoRRPUS system and abstracted prompting procedures can beat current state-of-the-art structured LLM techniques on pre-existing story understanding tasks (bAbI task 2 and Re^3) with minimal hand engineering. We hope that this work can help highlight the importance of symbolic representations and specialized prompting for LLMs as these models require some guidance for performing reasoning tasks properly.
Informative Text Generation from Knowledge Triples
Sep 26, 2022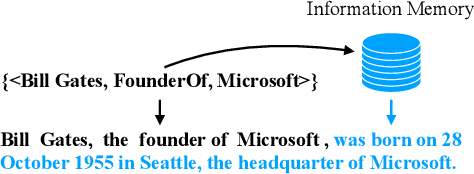

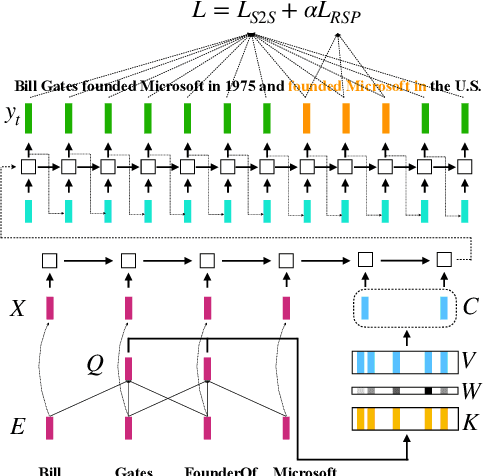
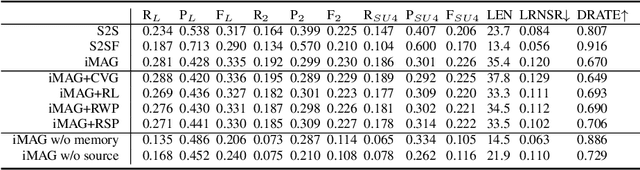
As the development of the encoder-decoder architecture, researchers are able to study the text generation tasks with broader types of data. Among them, KB-to-text aims at converting a set of knowledge triples into human readable sentences. In the original setting, the task assumes that the input triples and the text are exactly aligned in the perspective of the embodied knowledge/information. In this paper, we extend this setting and explore how to facilitate the trained model to generate more informative text, namely, containing more information about the triple entities but not conveyed by the input triples. To solve this problem, we propose a novel memory augmented generator that employs a memory network to memorize the useful knowledge learned during the training and utilizes such information together with the input triples to generate text in the operational or testing phase. We derive a dataset from WebNLG for our new setting and conduct extensive experiments to investigate the effectiveness of our model as well as uncover the intrinsic characteristics of the setting.