 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalAI 2.0: Enhancing knowledge graph traversal/retrieval with planning mechanism for Personalized LLM Agents
May 13, 2026We introduce PersonalAI 2.0 (PAI-2), a novel framework, designed to enhance large language model (LLM) based systems through integration of external knowledge graphs (KG). The proposed approach addresses key limitations of existing Graph Retrieval-Augmented Generation (GraphRAG) methods by incorporating a dynamic, multistage query processing pipeline. The central point of PAI-2 design is its ability to perform adaptive, iterative information search, guided by extracted entities, matched graph vertices and generated clue-queries. Conducted evaluation over six benchmarks (Natural Questions, TriviaQA, HotpotQA, 2WikiMultihopQA, MuSiQue and DiaASQ) demonstrates improvement in factual correctness of generating answers compared to analogues methods (LightRAG, RAPTOR, and HippoRAG 2). PAI-2 achieves 4% average gain by LLM-as-a-Judge across four benchmarks, reflecting its effectiveness in reducing hallucination rates and increasing precision. We show that use of graph traversal algorithms (e.g. BeamSearch, WaterCircles) gain superior results compared to standard flatten retriever on average 6%, while enabled search plan enhancement mechanism gain 18% boost compared to disabled one by LLM-as-a-Judge across six datasets. In addition, ablation study reveals that PAI-2 achieves the SOTA result on MINE-1 benchmark, achieving 89% information-retention score, using LLMs from 7-14B tiers. Collectively, these findings underscore the potential of PAI-2 to serve as a foundational model for next-generation personalized AI applications, requiring scalable, context-aware knowledge representation and reasoning capabilities.
Contextual Linear Activation Steering of Language Models
Apr 27, 2026Linear activation steering is a powerful approach for eliciting the capabilities of large language models and specializing their behavior using limited labeled data. While effective, existing methods often apply a fixed steering strength to all tokens, resulting in inconsistent steering quality across diverse input prompts. In this work, we introduce Contextual Linear Activation Steering (CLAS), a method that dynamically adapts linear activation steering to context-dependent steering strengths. Across eleven steering benchmarks and four model families, it consistently outperforms standard linear activation steering and matches or exceeds the performance of ReFT and LoRA in settings with limited labeled data. We therefore propose CLAS as a scalable, interpretable, and accurate method for specializing and steering large language models.
Convergent Evolution: How Different Language Models Learn Similar Number Representations
Apr 22, 2026Language models trained on natural text learn to represent numbers using periodic features with dominant periods at $T=2, 5, 10$. In this paper, we identify a two-tiered hierarchy of these features: while Transformers, Linear RNNs, LSTMs, and classical word embeddings trained in different ways all learn features that have period-$T$ spikes in the Fourier domain, only some learn geometrically separable features that can be used to linearly classify a number mod-$T$. To explain this incongruity, we prove that Fourier domain sparsity is necessary but not sufficient for mod-$T$ geometric separability. Empirically, we investigate when model training yields geometrically separable features, finding that the data, architecture, optimizer, and tokenizer all play key roles. In particular, we identify two different routes through which models can acquire geometrically separable features: they can learn them from complementary co-occurrence signals in general language data, including text-number co-occurrence and cross-number interaction, or from multi-token (but not single-token) addition problems. Overall, our results highlight the phenomenon of convergent evolution in feature learning: A diverse range of models learn similar features from different training signals.
Breaking Data Symmetry is Needed For Generalization in Feature Learning Kernels
Mar 31, 2026Grokking occurs when a model achieves high training accuracy but generalization to unseen test points happens long after that. This phenomenon was initially observed on a class of algebraic problems, such as learning modular arithmetic (Power et al., 2022). We study grokking on algebraic tasks in a class of feature learning kernels via the Recursive Feature Machine (RFM) algorithm (Radhakrishnan et al., 2024), which iteratively updates feature matrices through the Average Gradient Outer Product (AGOP) of an estimator in order to learn task-relevant features. Our main experimental finding is that generalization occurs only when a certain symmetry in the training set is broken. Furthermore, we empirically show that RFM generalizes by recovering the underlying invariance group action inherent in the data. We find that the learned feature matrices encode specific elements of the invariance group, explaining the dependence of generalization on symmetry.
Catching rationalization in the act: detecting motivated reasoning before and after CoT via activation probing
Mar 17, 2026Large language models (LLMs) can produce chains of thought (CoT) that do not accurately reflect the actual factors driving their answers. In multiple-choice settings with an injected hint favoring a particular option, models may shift their final answer toward the hinted option and produce a CoT that rationalizes the response without acknowledging the hint - an instance of motivated reasoning. We study this phenomenon across multiple LLM families and datasets demonstrating that motivated reasoning can be identified by probing internal activations even in cases when it cannot be easily determined from CoT. Using supervised probes trained on the model's residual stream, we show that (i) pre-generation probes, applied before any CoT tokens are generated, predict motivated reasoning as well as a LLM-based CoT monitor that accesses the full CoT trace, and (ii) post-generation probes, applied after CoT generation, outperform the same monitor. Together, these results show that motivated reasoning is detected more reliably from internal representations than from CoT monitoring. Moreover, pre-generation probing can flag motivated behavior early, potentially avoiding unnecessary generation.
General and Efficient Steering of Unconditional Diffusion
Feb 11, 2026Guiding unconditional diffusion models typically requires either retraining with conditional inputs or per-step gradient computations (e.g., classifier-based guidance), both of which incur substantial computational overhead. We present a general recipe for efficiently steering unconditional diffusion {without gradient guidance during inference}, enabling fast controllable generation. Our approach is built on two observations about diffusion model structure: Noise Alignment: even in early, highly corrupted stages, coarse semantic steering is possible using a lightweight, offline-computed guidance signal, avoiding any per-step or per-sample gradients. Transferable concept vectors: a concept direction in activation space once learned transfers across both {timesteps} and {samples}; the same fixed steering vector learned near low noise level remains effective when injected at intermediate noise levels for every generation trajectory, providing refined conditional control with efficiency. Such concept directions can be efficiently and reliably identified via Recursive Feature Machine (RFM), a light-weight backpropagation-free feature learning method. Experiments on CIFAR-10, ImageNet, and CelebA demonstrate improved accuracy/quality over gradient-based guidance, while achieving significant inference speedups.
A Gap Between the Gaussian RKHS and Neural Networks: An Infinite-Center Asymptotic Analysis
Feb 22, 2025
Recent works have characterized the function-space inductive bias of infinite-width bounded-norm single-hidden-layer neural networks as a kind of bounded-variation-type space. This novel neural network Banach space encompasses many classical multivariate function spaces including certain Sobolev spaces and the spectral Barron spaces. Notably, this Banach space also includes functions that exhibit less classical regularity such as those that only vary in a few directions. On bounded domains, it is well-established that the Gaussian reproducing kernel Hilbert space (RKHS) strictly embeds into this Banach space, demonstrating a clear gap between the Gaussian RKHS and the neural network Banach space. It turns out that when investigating these spaces on unbounded domains, e.g., all of $\mathbb{R}^d$, the story is fundamentally different. We establish the following fundamental result: Certain functions that lie in the Gaussian RKHS have infinite norm in the neural network Banach space. This provides a nontrivial gap between kernel methods and neural networks by the exhibition of functions in which kernel methods can do strictly better than neural networks.
Task Generalization With AutoRegressive Compositional Structure: Can Learning From $\d$ Tasks Generalize to $\d^{T}$ Tasks?
Feb 13, 2025Large language models (LLMs) exhibit remarkable task generalization, solving tasks they were never explicitly trained on with only a few demonstrations. This raises a fundamental question: When can learning from a small set of tasks generalize to a large task family? In this paper, we investigate task generalization through the lens of AutoRegressive Compositional (ARC) structure, where each task is a composition of $T$ operations, and each operation is among a finite family of $\d$ subtasks. This yields a total class of size~\( \d^\TT \). We first show that generalization to all \( \d^\TT \) tasks is theoretically achievable by training on only \( \tilde{O}(\d) \) tasks. Empirically, we demonstrate that Transformers achieve such exponential task generalization on sparse parity functions via in-context learning (ICL) and Chain-of-Thought (CoT) reasoning. We further demonstrate this generalization in arithmetic and language translation, extending beyond parity functions.
Aggregate and conquer: detecting and steering LLM concepts by combining nonlinear predictors over multiple layers
Feb 06, 2025



A trained Large Language Model (LLM) contains much of human knowledge. Yet, it is difficult to gauge the extent or accuracy of that knowledge, as LLMs do not always ``know what they know'' and may even be actively misleading. In this work, we give a general method for detecting semantic concepts in the internal activations of LLMs. Furthermore, we show that our methodology can be easily adapted to steer LLMs toward desirable outputs. Our innovations are the following: (1) we use a nonlinear feature learning method to identify important linear directions for predicting concepts from each layer; (2) we aggregate features across layers to build powerful concept detectors and steering mechanisms. We showcase the power of our approach by attaining state-of-the-art results for detecting hallucinations, harmfulness, toxicity, and untruthful content on seven benchmarks. We highlight the generality of our approach by steering LLMs towards new concepts that, to the best of our knowledge, have not been previously considered in the literature, including: semantic disambiguation, human languages, programming languages, hallucinated responses, science subjects, poetic/Shakespearean English, and even multiple concepts simultaneously. Moreover, our method can steer concepts with numerical attributes such as product reviews. We provide our code (including a simple API for our methods) at https://github.com/dmbeaglehole/neural_controllers .
Fast training of large kernel models with delayed projections
Nov 25, 2024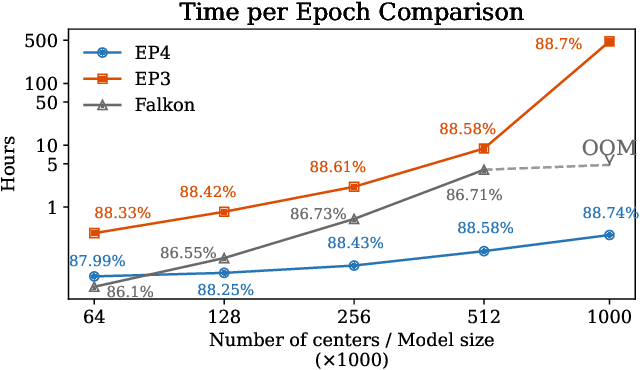

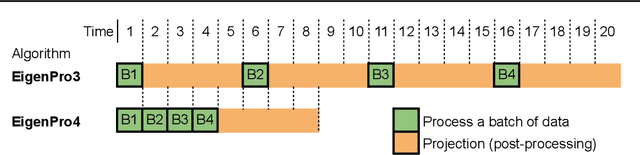

Classical kernel machines have historically faced significant challenges in scaling to large datasets and model sizes--a key ingredient that has driven the success of neural networks. In this paper, we present a new methodology for building kernel machines that can scale efficiently with both data size and model size. Our algorithm introduces delayed projections to Preconditioned Stochastic Gradient Descent (PSGD) allowing the training of much larger models than was previously feasible, pushing the practical limits of kernel-based learning. We validate our algorithm, EigenPro4, across multiple datasets, demonstrating drastic training speed up over the existing methods while maintaining comparable or better classification accuracy.