 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
Jan 30, 2026We investigate the functional role of emergent outliers in large language models, specifically attention sinks (a few tokens that consistently receive large attention logits) and residual sinks (a few fixed dimensions with persistently large activations across most tokens). We hypothesize that these outliers, in conjunction with the corresponding normalizations (\textit{e.g.}, softmax attention and RMSNorm), effectively rescale other non-outlier components. We term this phenomenon \textit{outlier-driven rescaling} and validate this hypothesis across different model architectures and training token counts. This view unifies the origin and mitigation of both sink types. Our main conclusions and observations include: (1) Outliers function jointly with normalization: removing normalization eliminates the corresponding outliers but degrades training stability and performance; directly clipping outliers while retaining normalization leads to degradation, indicating that outlier-driven rescaling contributes to training stability. (2) Outliers serve more as rescale factors rather than contributors, as the final contributions of attention and residual sinks are significantly smaller than those of non-outliers. (3) Outliers can be absorbed into learnable parameters or mitigated via explicit gated rescaling, leading to improved training performance (average gain of 2 points) and enhanced quantization robustness (1.2 points degradation under W4A4 quantization).
Task Generalization With AutoRegressive Compositional Structure: Can Learning From $\d$ Tasks Generalize to $\d^{T}$ Tasks?
Feb 13, 2025Large language models (LLMs) exhibit remarkable task generalization, solving tasks they were never explicitly trained on with only a few demonstrations. This raises a fundamental question: When can learning from a small set of tasks generalize to a large task family? In this paper, we investigate task generalization through the lens of AutoRegressive Compositional (ARC) structure, where each task is a composition of $T$ operations, and each operation is among a finite family of $\d$ subtasks. This yields a total class of size~\( \d^\TT \). We first show that generalization to all \( \d^\TT \) tasks is theoretically achievable by training on only \( \tilde{O}(\d) \) tasks. Empirically, we demonstrate that Transformers achieve such exponential task generalization on sparse parity functions via in-context learning (ICL) and Chain-of-Thought (CoT) reasoning. We further demonstrate this generalization in arithmetic and language translation, extending beyond parity functions.
From Sparse Dependence to Sparse Attention: Unveiling How Chain-of-Thought Enhances Transformer Sample Efficiency
Oct 07, 2024



Chain-of-thought (CoT) significantly enhances the reasoning performance of large language models (LLM). While current theoretical studies often attribute this improvement to increased expressiveness and computational capacity, we argue that expressiveness is not the primary limitation in the LLM regime, as current large models will fail on simple tasks. Using a parity-learning setup, we demonstrate that CoT can substantially improve sample efficiency even when the representation power is sufficient. Specifically, with CoT, a transformer can learn the function within polynomial samples, whereas without CoT, the required sample size is exponential. Additionally, we show that CoT simplifies the learning process by introducing sparse sequential dependencies among input tokens, and leads to a sparse and interpretable attention. We validate our theoretical analysis with both synthetic and real-world experiments, confirming that sparsity in attention layers is a key factor of the improvement induced by CoT.
Functionally Constrained Algorithm Solves Convex Simple Bilevel Problems
Sep 10, 2024This paper studies simple bilevel problems, where a convex upper-level function is minimized over the optimal solutions of a convex lower-level problem. We first show the fundamental difficulty of simple bilevel problems, that the approximate optimal value of such problems is not obtainable by first-order zero-respecting algorithms. Then we follow recent works to pursue the weak approximate solutions. For this goal, we propose novel near-optimal methods for smooth and nonsmooth problems by reformulating them into functionally constrained problems.
Compiler-Level Matrix Multiplication Optimization for Deep Learning
Sep 23, 2019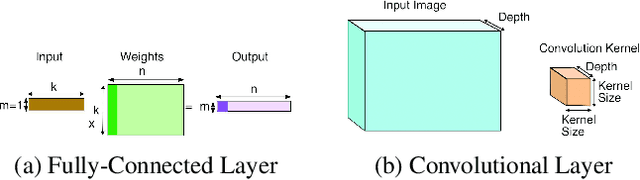
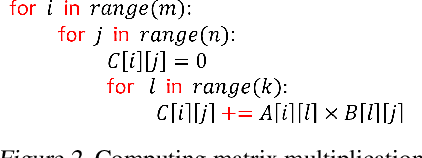
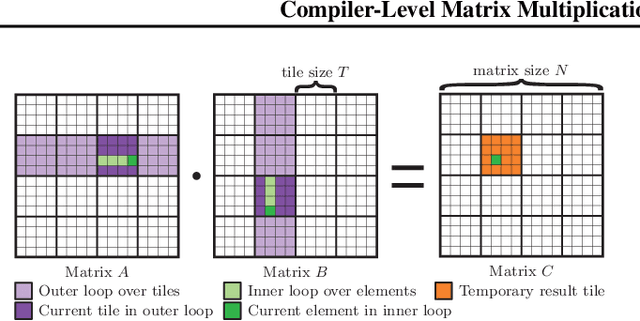

An important linear algebra routine, GEneral Matrix Multiplication (GEMM), is a fundamental operator in deep learning. Compilers need to translate these routines into low-level code optimized for specific hardware. Compiler-level optimization of GEMM has significant performance impact on training and executing deep learning models. However, most deep learning frameworks rely on hardware-specific operator libraries in which GEMM optimization has been mostly achieved by manual tuning, which restricts the performance on different target hardware. In this paper, we propose two novel algorithms for GEMM optimization based on the TVM framework, a lightweight Greedy Best First Search (G-BFS) method based on heuristic search, and a Neighborhood Actor Advantage Critic (N-A2C) method based on reinforcement learning. Experimental results show significant performance improvement of the proposed methods, in both the optimality of the solution and the cost of search in terms of time and fraction of the search space explored. Specifically, the proposed methods achieve 24% and 40% savings in GEMM computation time over state-of-the-art XGBoost and RNN methods, respectively, while exploring only 0.1% of the search space. The proposed approaches have potential to be applied to other operator-level optimizations.
Gradient-Coherent Strong Regularization for Deep Neural Networks
Nov 20, 2018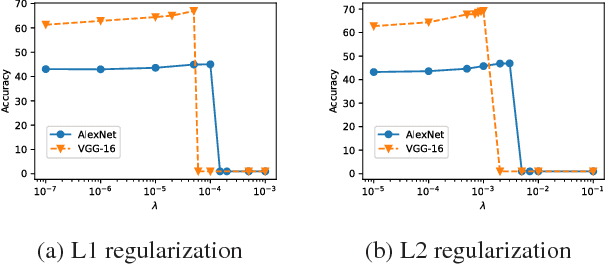
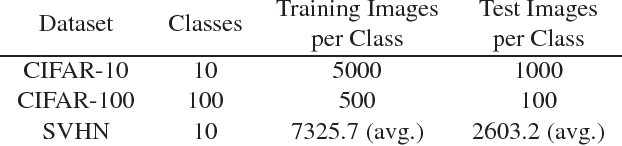
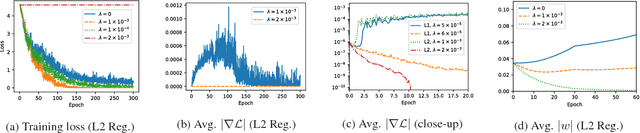

Deep neural networks are often prone to over-fitting with their numerous parameters, so regularization plays an important role in generalization. L1 and L2 regularizers are common regularization tools in machine learning with their simplicity and effectiveness. However, we observe that imposing strong L1 or L2 regularization on deep neural networks with stochastic gradient descent easily fails, which limits the generalization ability of the underlying neural networks. To understand this phenomenon, we first investigate how and why learning fails when strong regularization is imposed on deep neural networks. We then propose a novel method, gradient-coherent strong regularization, which imposes regularization only when the gradients are kept coherent in the presence of strong regularization. Experiments are performed with multiple deep architectures on three benchmark data sets for image recognition. Experimental results show that our proposed approach indeed endures strong regularization and significantly improves both accuracy and compression, which could not be achieved otherwise.