 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Policy Distillation of Language Models for Autonomous Vehicle Motion Planning
Apr 09, 2026Large language models (LLMs) have recently demonstrated strong potential for autonomous vehicle motion planning by reformulating trajectory prediction as a language generation problem. However, deploying capable LLMs in resource-constrained onboard systems remains a fundamental challenge. In this paper, we study how to effectively transfer motion planning knowledge from a large teacher LLM to a smaller, more deployable student model. We build on the GPT-Driver framework, which represents driving scenes as language prompts and generates waypoint trajectories with chain-of-thought reasoning, and investigate two student training paradigms: (i) on-policy generalized knowledge distillation (GKD), which trains the student on its own self-generated outputs using dense token-level feedback from the teacher, and (ii) a dense-feedback reinforcement learning (RL) baseline that uses the teacher's log-probabilities as per-token reward signals in a policy gradient framework. Experiments on the nuScenes benchmark show that GKD substantially outperforms the RL baseline and closely approaches teacher-level performance despite a 5$\times$ reduction in model size. These results highlight the practical value of on-policy distillation as a principled and effective approach to deploying LLM-based planners in autonomous driving systems.
Task Generalization With AutoRegressive Compositional Structure: Can Learning From $\d$ Tasks Generalize to $\d^{T}$ Tasks?
Feb 13, 2025Large language models (LLMs) exhibit remarkable task generalization, solving tasks they were never explicitly trained on with only a few demonstrations. This raises a fundamental question: When can learning from a small set of tasks generalize to a large task family? In this paper, we investigate task generalization through the lens of AutoRegressive Compositional (ARC) structure, where each task is a composition of $T$ operations, and each operation is among a finite family of $\d$ subtasks. This yields a total class of size~\( \d^\TT \). We first show that generalization to all \( \d^\TT \) tasks is theoretically achievable by training on only \( \tilde{O}(\d) \) tasks. Empirically, we demonstrate that Transformers achieve such exponential task generalization on sparse parity functions via in-context learning (ICL) and Chain-of-Thought (CoT) reasoning. We further demonstrate this generalization in arithmetic and language translation, extending beyond parity functions.
Fast training of large kernel models with delayed projections
Nov 25, 2024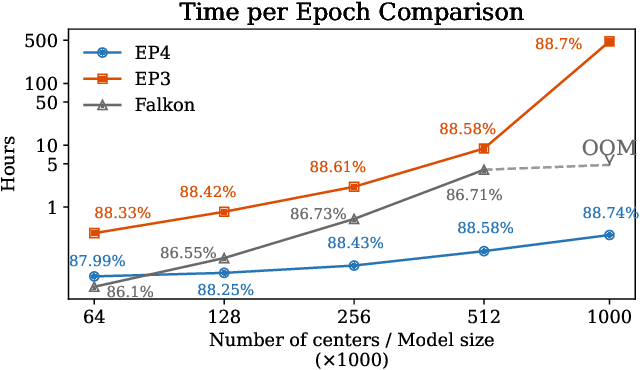

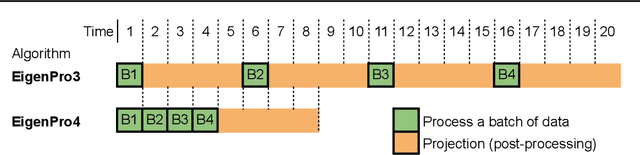

Classical kernel machines have historically faced significant challenges in scaling to large datasets and model sizes--a key ingredient that has driven the success of neural networks. In this paper, we present a new methodology for building kernel machines that can scale efficiently with both data size and model size. Our algorithm introduces delayed projections to Preconditioned Stochastic Gradient Descent (PSGD) allowing the training of much larger models than was previously feasible, pushing the practical limits of kernel-based learning. We validate our algorithm, EigenPro4, across multiple datasets, demonstrating drastic training speed up over the existing methods while maintaining comparable or better classification accuracy.
Context-Scaling versus Task-Scaling in In-Context Learning
Oct 16, 2024



Transformers exhibit In-Context Learning (ICL), where these models solve new tasks by using examples in the prompt without additional training. In our work, we identify and analyze two key components of ICL: (1) context-scaling, where model performance improves as the number of in-context examples increases and (2) task-scaling, where model performance improves as the number of pre-training tasks increases. While transformers are capable of both context-scaling and task-scaling, we empirically show that standard Multi-Layer Perceptrons (MLPs) with vectorized input are only capable of task-scaling. To understand how transformers are capable of context-scaling, we first propose a significantly simplified transformer architecture without key, query, value weights. We show that it performs ICL comparably to the original GPT-2 model in various statistical learning tasks including linear regression, teacher-student settings. Furthermore, a single block of our simplified transformer can be viewed as data dependent feature map followed by an MLP. This feature map on its own is a powerful predictor that is capable of context-scaling but is not capable of task-scaling. We show empirically that concatenating the output of this feature map with vectorized data as an input to MLPs enables both context-scaling and task-scaling. This finding provides a simple setting to study context and task-scaling for ICL.
On the Nystrom Approximation for Preconditioning in Kernel Machines
Dec 06, 2023Kernel methods are a popular class of nonlinear predictive models in machine learning. Scalable algorithms for learning kernel models need to be iterative in nature, but convergence can be slow due to poor conditioning. Spectral preconditioning is an important tool to speed-up the convergence of such iterative algorithms for training kernel models. However computing and storing a spectral preconditioner can be expensive which can lead to large computational and storage overheads, precluding the application of kernel methods to problems with large datasets. A Nystrom approximation of the spectral preconditioner is often cheaper to compute and store, and has demonstrated success in practical applications. In this paper we analyze the trade-offs of using such an approximated preconditioner. Specifically, we show that a sample of logarithmic size (as a function of the size of the dataset) enables the Nystrom-based approximated preconditioner to accelerate gradient descent nearly as well as the exact preconditioner, while also reducing the computational and storage overheads.
On Emergence of Clean-Priority Learning in Early Stopped Neural Networks
Jun 05, 2023



When random label noise is added to a training dataset, the prediction error of a neural network on a label-noise-free test dataset initially improves during early training but eventually deteriorates, following a U-shaped dependence on training time. This behaviour is believed to be a result of neural networks learning the pattern of clean data first and fitting the noise later in the training, a phenomenon that we refer to as clean-priority learning. In this study, we aim to explore the learning dynamics underlying this phenomenon. We theoretically demonstrate that, in the early stage of training, the update direction of gradient descent is determined by the clean subset of training data, leaving the noisy subset has minimal to no impact, resulting in a prioritization of clean learning. Moreover, we show both theoretically and experimentally, as the clean-priority learning goes on, the dominance of the gradients of clean samples over those of noisy samples diminishes, and finally results in a termination of the clean-priority learning and fitting of the noisy samples.
Toward Large Kernel Models
Feb 06, 2023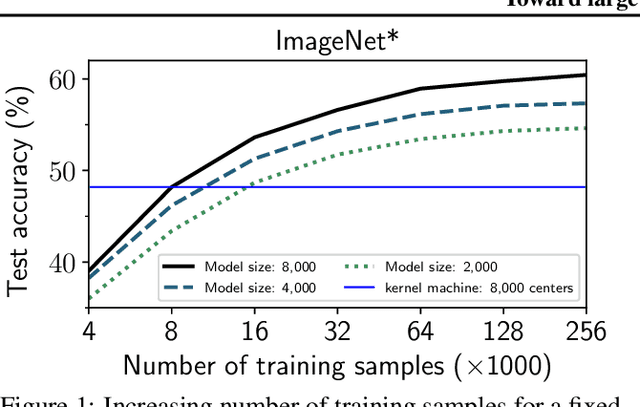
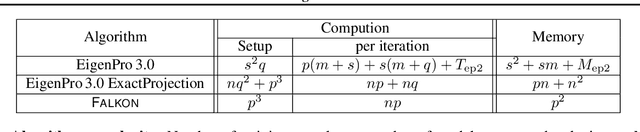
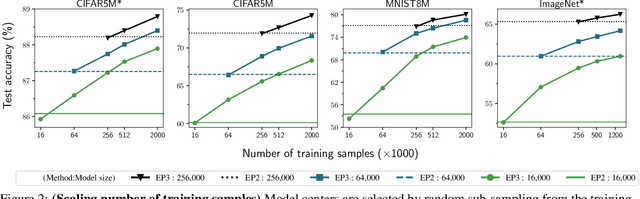

Recent studies indicate that kernel machines can often perform similarly or better than deep neural networks (DNNs) on small datasets. The interest in kernel machines has been additionally bolstered by the discovery of their equivalence to wide neural networks in certain regimes. However, a key feature of DNNs is their ability to scale the model size and training data size independently, whereas in traditional kernel machines model size is tied to data size. Because of this coupling, scaling kernel machines to large data has been computationally challenging. In this paper, we provide a way forward for constructing large-scale general kernel models, which are a generalization of kernel machines that decouples the model and data, allowing training on large datasets. Specifically, we introduce EigenPro 3.0, an algorithm based on projected dual preconditioned SGD and show scaling to model and data sizes which have not been possible with existing kernel methods.
Benign, Tempered, or Catastrophic: A Taxonomy of Overfitting
Jul 14, 2022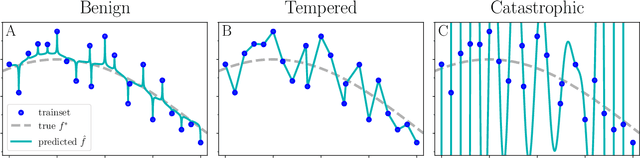

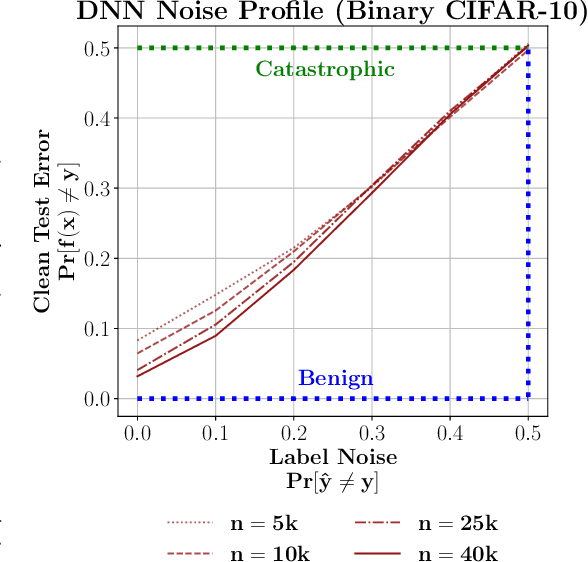

The practical success of overparameterized neural networks has motivated the recent scientific study of interpolating methods, which perfectly fit their training data. Certain interpolating methods, including neural networks, can fit noisy training data without catastrophically bad test performance, in defiance of standard intuitions from statistical learning theory. Aiming to explain this, a body of recent work has studied $\textit{benign overfitting}$, a phenomenon where some interpolating methods approach Bayes optimality, even in the presence of noise. In this work we argue that while benign overfitting has been instructive and fruitful to study, many real interpolating methods like neural networks $\textit{do not fit benignly}$: modest noise in the training set causes nonzero (but non-infinite) excess risk at test time, implying these models are neither benign nor catastrophic but rather fall in an intermediate regime. We call this intermediate regime $\textit{tempered overfitting}$, and we initiate its systematic study. We first explore this phenomenon in the context of kernel (ridge) regression (KR) by obtaining conditions on the ridge parameter and kernel eigenspectrum under which KR exhibits each of the three behaviors. We find that kernels with powerlaw spectra, including Laplace kernels and ReLU neural tangent kernels, exhibit tempered overfitting. We then empirically study deep neural networks through the lens of our taxonomy, and find that those trained to interpolation are tempered, while those stopped early are benign. We hope our work leads to a more refined understanding of overfitting in modern learning.