Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast training of large kernel models with delayed projections
Paper and Code
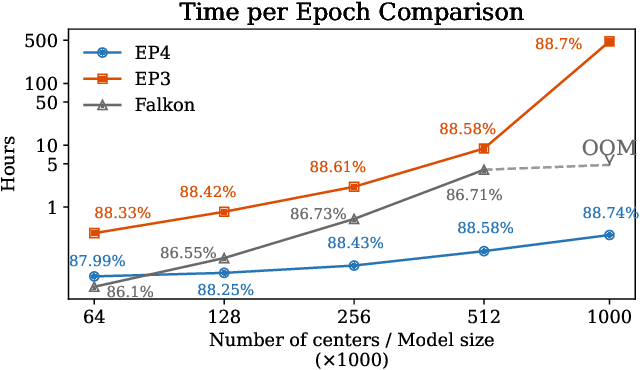

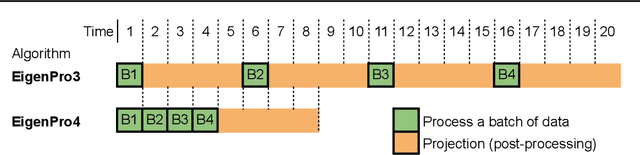

Classical kernel machines have historically faced significant challenges in scaling to large datasets and model sizes--a key ingredient that has driven the success of neural networks. In this paper, we present a new methodology for building kernel machines that can scale efficiently with both data size and model size. Our algorithm introduces delayed projections to Preconditioned Stochastic Gradient Descent (PSGD) allowing the training of much larger models than was previously feasible, pushing the practical limits of kernel-based learning. We validate our algorithm, EigenPro4, across multiple datasets, demonstrating drastic training speed up over the existing methods while maintaining comparable or better classification accuracy.
* arXiv admin note: text overlap with arXiv:2302.02605
View paper on