 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotations Mitigate Post-Training Mode Collapse
May 11, 2026Post-training (via supervised fine-tuning) improves instruction-following, but often induces semantic mode collapse by biasing models toward low-entropy fine-tuning data at the expense of the high-entropy pretraining distribution. Crucially, we find this trade-off worsens with scale. To close this semantic diversity gap, we propose annotation-anchored training, a principled method that enables models to adopt the preference-following behaviors of post-training without sacrificing the inherent diversity of pretraining. Our approach is simple: we pretrain on documents paired with semantic annotations, inducing a rich annotation distribution that reflects the full breadth of pretraining data, and we preserve this distribution during post-training. This lets us sample diverse annotations at inference time and use them as anchors to guide generation, effectively transferring pretraining's semantic richness into post-trained models. We find that models trained with annotation-anchored training can attain $6 \times$ less diversity collapse than models trained with SFT, and improve with scale.
Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs
Nov 06, 2025Large Language Models (LLMs) often lack meaningful confidence estimates for their outputs. While base LLMs are known to exhibit next-token calibration, it remains unclear whether they can assess confidence in the actual meaning of their responses beyond the token level. We find that, when using a certain sampling-based notion of semantic calibration, base LLMs are remarkably well-calibrated: they can meaningfully assess confidence in open-domain question-answering tasks, despite not being explicitly trained to do so. Our main theoretical contribution establishes a mechanism for why semantic calibration emerges as a byproduct of next-token prediction, leveraging a recent connection between calibration and local loss optimality. The theory relies on a general definition of "B-calibration," which is a notion of calibration parameterized by a choice of equivalence classes (semantic or otherwise). This theoretical mechanism leads to a testable prediction: base LLMs will be semantically calibrated when they can easily predict their own distribution over semantic answer classes before generating a response. We state three implications of this prediction, which we validate through experiments: (1) Base LLMs are semantically calibrated across question-answering tasks, (2) RL instruction-tuning systematically breaks this calibration, and (3) chain-of-thought reasoning breaks calibration. To our knowledge, our work provides the first principled explanation of when and why semantic calibration emerges in LLMs.
Composition and Control with Distilled Energy Diffusion Models and Sequential Monte Carlo
Feb 18, 2025Diffusion models may be formulated as a time-indexed sequence of energy-based models, where the score corresponds to the negative gradient of an energy function. As opposed to learning the score directly, an energy parameterization is attractive as the energy itself can be used to control generation via Monte Carlo samplers. Architectural constraints and training instability in energy parameterized models have so far yielded inferior performance compared to directly approximating the score or denoiser. We address these deficiencies by introducing a novel training regime for the energy function through distillation of pre-trained diffusion models, resembling a Helmholtz decomposition of the score vector field. We further showcase the synergies between energy and score by casting the diffusion sampling procedure as a Feynman Kac model where sampling is controlled using potentials from the learnt energy functions. The Feynman Kac model formalism enables composition and low temperature sampling through sequential Monte Carlo.
Mechanisms of Projective Composition of Diffusion Models
Feb 06, 2025

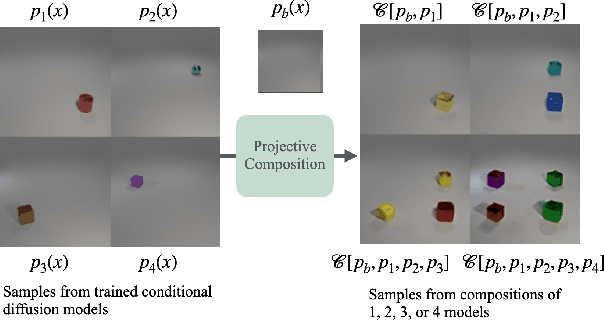
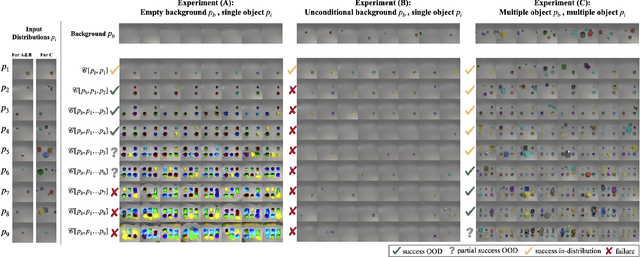
We study the theoretical foundations of composition in diffusion models, with a particular focus on out-of-distribution extrapolation and length-generalization. Prior work has shown that composing distributions via linear score combination can achieve promising results, including length-generalization in some cases (Du et al., 2023; Liu et al., 2022). However, our theoretical understanding of how and why such compositions work remains incomplete. In fact, it is not even entirely clear what it means for composition to "work". This paper starts to address these fundamental gaps. We begin by precisely defining one possible desired result of composition, which we call projective composition. Then, we investigate: (1) when linear score combinations provably achieve projective composition, (2) whether reverse-diffusion sampling can generate the desired composition, and (3) the conditions under which composition fails. Finally, we connect our theoretical analysis to prior empirical observations where composition has either worked or failed, for reasons that were unclear at the time.
Normalizing Flows are Capable Generative Models
Dec 10, 2024Normalizing Flows (NFs) are likelihood-based models for continuous inputs. They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relatively little attention in recent years. In this work, we demonstrate that NFs are more powerful than previously believed. We present TarFlow: a simple and scalable architecture that enables highly performant NF models. TarFlow can be thought of as a Transformer-based variant of Masked Autoregressive Flows (MAFs): it consists of a stack of autoregressive Transformer blocks on image patches, alternating the autoregression direction between layers. TarFlow is straightforward to train end-to-end, and capable of directly modeling and generating pixels. We also propose three key techniques to improve sample quality: Gaussian noise augmentation during training, a post training denoising procedure, and an effective guidance method for both class-conditional and unconditional settings. Putting these together, TarFlow sets new state-of-the-art results on likelihood estimation for images, beating the previous best methods by a large margin, and generates samples with quality and diversity comparable to diffusion models, for the first time with a stand-alone NF model. We make our code available at https://github.com/apple/ml-tarflow.
A Formal Framework for Understanding Length Generalization in Transformers
Oct 03, 2024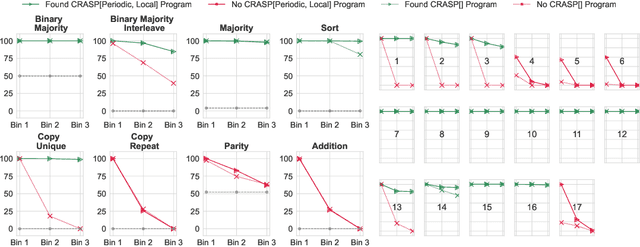

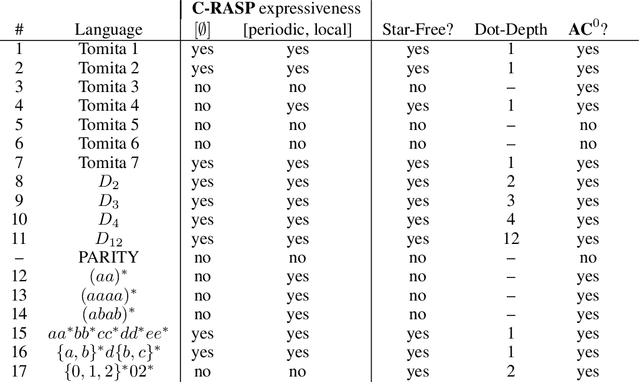
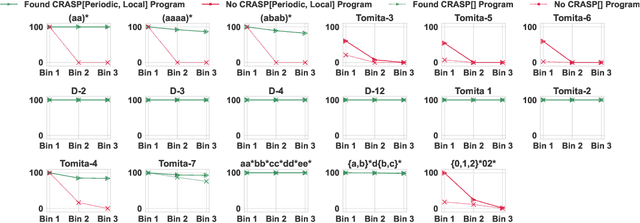
A major challenge for transformers is generalizing to sequences longer than those observed during training. While previous works have empirically shown that transformers can either succeed or fail at length generalization depending on the task, theoretical understanding of this phenomenon remains limited. In this work, we introduce a rigorous theoretical framework to analyze length generalization in causal transformers with learnable absolute positional encodings. In particular, we characterize those functions that are identifiable in the limit from sufficiently long inputs with absolute positional encodings under an idealized inference scheme using a norm-based regularizer. This enables us to prove the possibility of length generalization for a rich family of problems. We experimentally validate the theory as a predictor of success and failure of length generalization across a range of algorithmic and formal language tasks. Our theory not only explains a broad set of empirical observations but also opens the way to provably predicting length generalization capabilities in transformers.
Classifier-Free Guidance is a Predictor-Corrector
Aug 16, 2024We investigate the theoretical foundations of classifier-free guidance (CFG). CFG is the dominant method of conditional sampling for text-to-image diffusion models, yet unlike other aspects of diffusion, it remains on shaky theoretical footing. In this paper, we disprove common misconceptions, by showing that CFG interacts differently with DDPM (Ho et al., 2020) and DDIM (Song et al., 2021), and neither sampler with CFG generates the gamma-powered distribution $p(x|c)^\gamma p(x)^{1-\gamma}$. Then, we clarify the behavior of CFG by showing that it is a kind of predictor-corrector method (Song et al., 2020) that alternates between denoising and sharpening, which we call predictor-corrector guidance (PCG). We prove that in the SDE limit, CFG is actually equivalent to combining a DDIM predictor for the conditional distribution together with a Langevin dynamics corrector for a gamma-powered distribution (with a carefully chosen gamma). Our work thus provides a lens to theoretically understand CFG by embedding it in a broader design space of principled sampling methods.
How JEPA Avoids Noisy Features: The Implicit Bias of Deep Linear Self Distillation Networks
Jul 03, 2024



Two competing paradigms exist for self-supervised learning of data representations. Joint Embedding Predictive Architecture (JEPA) is a class of architectures in which semantically similar inputs are encoded into representations that are predictive of each other. A recent successful approach that falls under the JEPA framework is self-distillation, where an online encoder is trained to predict the output of the target encoder, sometimes using a lightweight predictor network. This is contrasted with the Masked AutoEncoder (MAE) paradigm, where an encoder and decoder are trained to reconstruct missing parts of the input in the data space rather, than its latent representation. A common motivation for using the JEPA approach over MAE is that the JEPA objective prioritizes abstract features over fine-grained pixel information (which can be unpredictable and uninformative). In this work, we seek to understand the mechanism behind this empirical observation by analyzing the training dynamics of deep linear models. We uncover a surprising mechanism: in a simplified linear setting where both approaches learn similar representations, JEPAs are biased to learn high-influence features, i.e., features characterized by having high regression coefficients. Our results point to a distinct implicit bias of predicting in latent space that may shed light on its success in practice.
Step-by-Step Diffusion: An Elementary Tutorial
Jun 13, 2024



We present an accessible first course on diffusion models and flow matching for machine learning, aimed at a technical audience with no diffusion experience. We try to simplify the mathematical details as much as possible (sometimes heuristically), while retaining enough precision to derive correct algorithms.
When is Multicalibration Post-Processing Necessary?
Jun 10, 2024
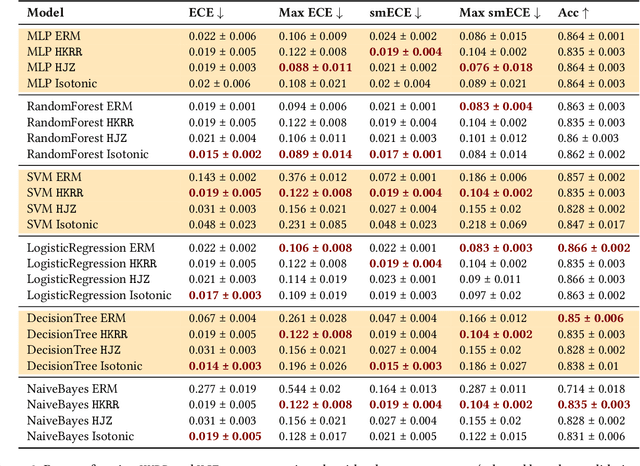


Calibration is a well-studied property of predictors which guarantees meaningful uncertainty estimates. Multicalibration is a related notion -- originating in algorithmic fairness -- which requires predictors to be simultaneously calibrated over a potentially complex and overlapping collection of protected subpopulations (such as groups defined by ethnicity, race, or income). We conduct the first comprehensive study evaluating the usefulness of multicalibration post-processing across a broad set of tabular, image, and language datasets for models spanning from simple decision trees to 90 million parameter fine-tuned LLMs. Our findings can be summarized as follows: (1) models which are calibrated out of the box tend to be relatively multicalibrated without any additional post-processing; (2) multicalibration post-processing can help inherently uncalibrated models; and (3) traditional calibration measures may sometimes provide multicalibration implicitly. More generally, we also distill many independent observations which may be useful for practical and effective applications of multicalibration post-processing in real-world contexts.