 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokAlign: Geometric Characterisation and Acceleration of Grokking
Jun 14, 2025

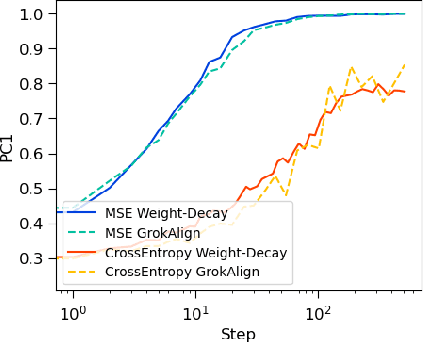
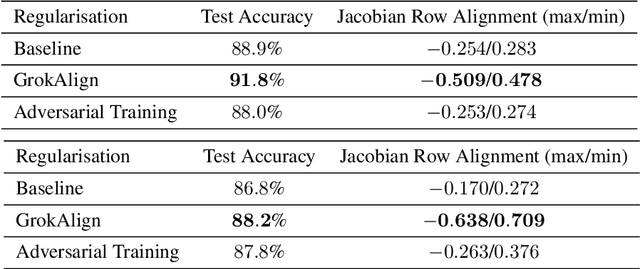
A key challenge for the machine learning community is to understand and accelerate the training dynamics of deep networks that lead to delayed generalisation and emergent robustness to input perturbations, also known as grokking. Prior work has associated phenomena like delayed generalisation with the transition of a deep network from a linear to a feature learning regime, and emergent robustness with changes to the network's functional geometry, in particular the arrangement of the so-called linear regions in deep networks employing continuous piecewise affine nonlinearities. Here, we explain how grokking is realised in the Jacobian of a deep network and demonstrate that aligning a network's Jacobians with the training data (in the sense of cosine similarity) ensures grokking under a low-rank Jacobian assumption. Our results provide a strong theoretical motivation for the use of Jacobian regularisation in optimizing deep networks -- a method we introduce as GrokAlign -- which we show empirically to induce grokking much sooner than more conventional regularizers like weight decay. Moreover, we introduce centroid alignment as a tractable and interpretable simplification of Jacobian alignment that effectively identifies and tracks the stages of deep network training dynamics. Accompanying \href{https://thomaswalker1.github.io/blog/grokalign.html}{webpage} and \href{https://github.com/ThomasWalker1/grokalign}{code}.
Training LLM-based Tutors to Improve Student Learning Outcomes in Dialogues
Mar 09, 2025



Generative artificial intelligence (AI) has the potential to scale up personalized tutoring through large language models (LLMs). Recent AI tutors are adapted for the tutoring task by training or prompting LLMs to follow effective pedagogical principles, though they are not trained to maximize student learning throughout the course of a dialogue. Therefore, they may engage with students in a suboptimal way. We address this limitation by introducing an approach to train LLMs to generate tutor utterances that maximize the likelihood of student correctness, while still encouraging the model to follow good pedagogical practice. Specifically, we generate a set of candidate tutor utterances and score them using (1) an LLM-based student model to predict the chance of correct student responses and (2) a pedagogical rubric evaluated by GPT-4o. We then use the resulting data to train an open-source LLM, Llama 3.1 8B, using direct preference optimization. We show that tutor utterances generated by our model lead to significantly higher chances of correct student responses while maintaining the pedagogical quality of GPT-4o. We also conduct qualitative analyses and a human evaluation to demonstrate that our model generates high quality tutor utterances.
Self-Improving Diffusion Models with Synthetic Data
Aug 29, 2024
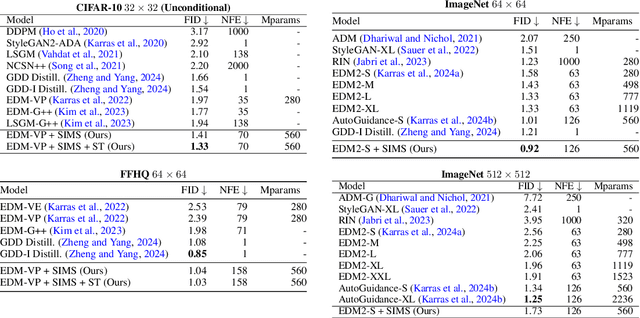
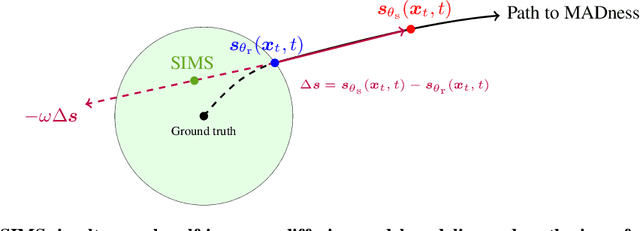
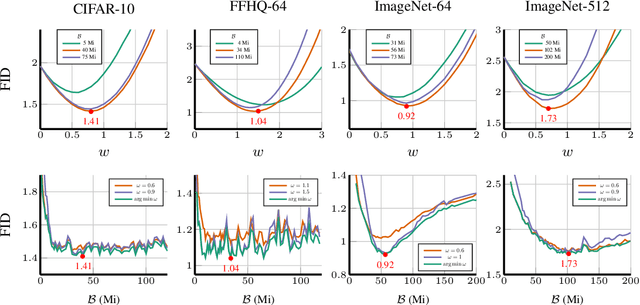
The artificial intelligence (AI) world is running out of real data for training increasingly large generative models, resulting in accelerating pressure to train on synthetic data. Unfortunately, training new generative models with synthetic data from current or past generation models creates an autophagous (self-consuming) loop that degrades the quality and/or diversity of the synthetic data in what has been termed model autophagy disorder (MAD) and model collapse. Current thinking around model autophagy recommends that synthetic data is to be avoided for model training lest the system deteriorate into MADness. In this paper, we take a different tack that treats synthetic data differently from real data. Self-IMproving diffusion models with Synthetic data (SIMS) is a new training concept for diffusion models that uses self-synthesized data to provide negative guidance during the generation process to steer a model's generative process away from the non-ideal synthetic data manifold and towards the real data distribution. We demonstrate that SIMS is capable of self-improvement; it establishes new records based on the Fr\'echet inception distance (FID) metric for CIFAR-10 and ImageNet-64 generation and achieves competitive results on FFHQ-64 and ImageNet-512. Moreover, SIMS is, to the best of our knowledge, the first prophylactic generative AI algorithm that can be iteratively trained on self-generated synthetic data without going MAD. As a bonus, SIMS can adjust a diffusion model's synthetic data distribution to match any desired in-domain target distribution to help mitigate biases and ensure fairness.
On the Geometry of Deep Learning
Aug 09, 2024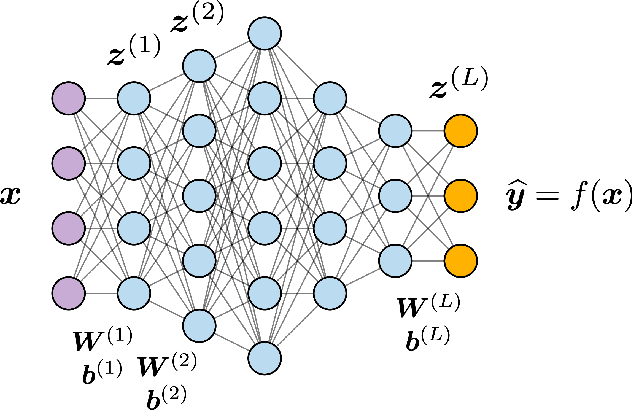
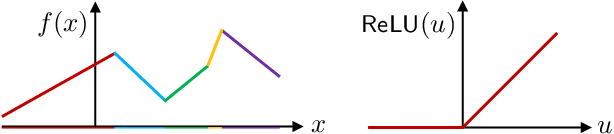
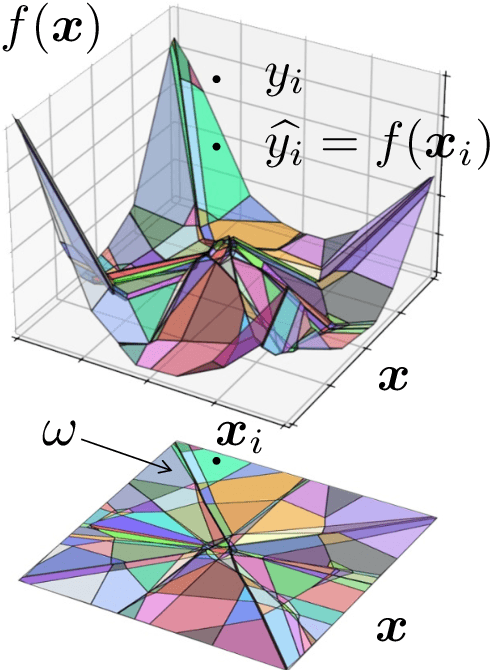
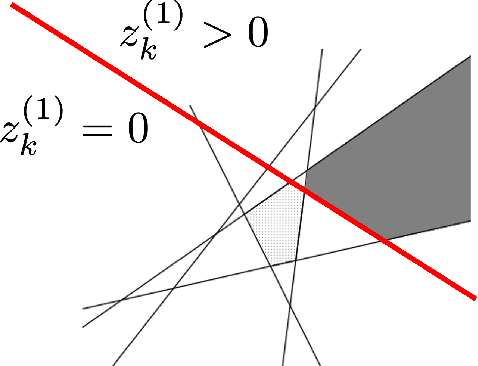
In this paper, we overview one promising avenue of progress at the mathematical foundation of deep learning: the connection between deep networks and function approximation by affine splines (continuous piecewise linear functions in multiple dimensions). In particular, we will overview work over the past decade on understanding certain geometrical properties of a deep network's affine spline mapping, in particular how it tessellates its input space. As we will see, the affine spline connection and geometrical viewpoint provide a powerful portal through which to view, analyze, and improve the inner workings of a deep network.
MalAlgoQA: A Pedagogical Approach for Evaluating Counterfactual Reasoning Abilities
Jul 01, 2024This paper introduces MalAlgoQA, a novel dataset designed to evaluate the counterfactual reasoning capabilities of Large Language Models (LLMs) through a pedagogical approach. The dataset comprises mathematics and reading comprehension questions, each accompanied by four answer choices and their corresponding rationales. We focus on the incorrect answer rationales, termed "malgorithms", which highlights flawed reasoning steps leading to incorrect answers and offers valuable insights into erroneous thought processes. We also propose the Malgorithm Identification task, where LLMs are assessed based on their ability to identify corresponding malgorithm given an incorrect answer choice. To evaluate the model performance, we introduce two metrics: Algorithm Identification Accuracy (AIA) for correct answer rationale identification, and Malgorithm Identification Accuracy (MIA) for incorrect answer rationale identification. The task is challenging since state-of-the-art LLMs exhibit significant drops in MIA as compared to AIA. Moreover, we find that the chain-of-thought prompting technique not only fails to consistently enhance MIA, but can also lead to underperformance compared to simple prompting. These findings hold significant implications for the development of more cognitively-inspired LLMs to improve their counterfactual reasoning abilities, particularly through a pedagogical perspective where understanding and rectifying student misconceptions are crucial.
Synthetic Context Generation for Question Generation
Jun 19, 2024Despite rapid advancements in large language models (LLMs), QG remains a challenging problem due to its complicated process, open-ended nature, and the diverse settings in which question generation occurs. A common approach to address these challenges involves fine-tuning smaller, custom models using datasets containing background context, question, and answer. However, obtaining suitable domain-specific datasets with appropriate context is often more difficult than acquiring question-answer pairs. In this paper, we investigate training QG models using synthetic contexts generated by LLMs from readily available question-answer pairs. We conduct a comprehensive study to answer critical research questions related to the performance of models trained on synthetic contexts and their potential impact on QG research and applications. Our empirical results reveal: 1) contexts are essential for QG tasks, even if they are synthetic; 2) fine-tuning smaller language models has the capability of achieving better performances as compared to prompting larger language models; and 3) synthetic context and real context could achieve comparable performances. These findings highlight the effectiveness of synthetic contexts in QG and paves the way for future advancements in the field.
ScaLES: Scalable Latent Exploration Score for Pre-Trained Generative Networks
Jun 14, 2024



We develop Scalable Latent Exploration Score (ScaLES) to mitigate over-exploration in Latent Space Optimization (LSO), a popular method for solving black-box discrete optimization problems. LSO utilizes continuous optimization within the latent space of a Variational Autoencoder (VAE) and is known to be susceptible to over-exploration, which manifests in unrealistic solutions that reduce its practicality. ScaLES is an exact and theoretically motivated method leveraging the trained decoder's approximation of the data distribution. ScaLES can be calculated with any existing decoder, e.g. from a VAE, without additional training, architectural changes, or access to the training data. Our evaluation across five LSO benchmark tasks and three VAE architectures demonstrates that ScaLES enhances the quality of the solutions while maintaining high objective values, leading to improvements over existing solutions. We believe that new avenues to LSO will be opened by ScaLES ability to identify out of distribution areas, differentiability, and computational tractability. Open source code for ScaLES is available at https://github.com/OmerRonen/scales.
Deep Networks Always Grok and Here is Why
Feb 23, 2024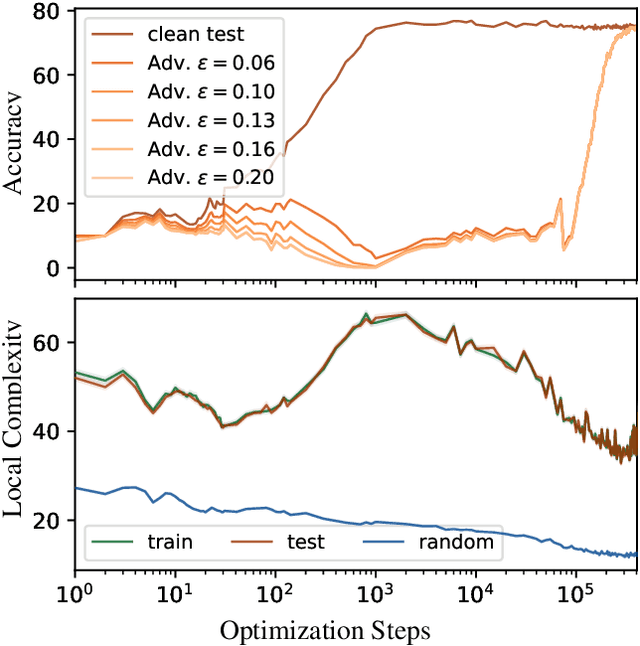

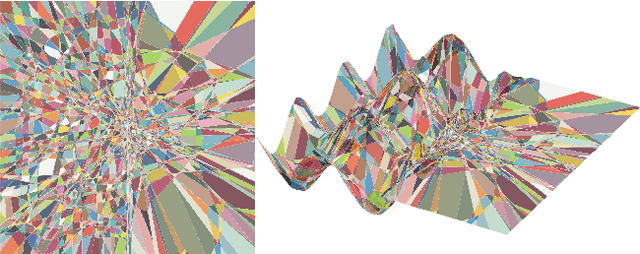
Grokking, or delayed generalization, is a phenomenon where generalization in a deep neural network (DNN) occurs long after achieving near zero training error. Previous studies have reported the occurrence of grokking in specific controlled settings, such as DNNs initialized with large-norm parameters or transformers trained on algorithmic datasets. We demonstrate that grokking is actually much more widespread and materializes in a wide range of practical settings, such as training of a convolutional neural network (CNN) on CIFAR10 or a Resnet on Imagenette. We introduce the new concept of delayed robustness, whereby a DNN groks adversarial examples and becomes robust, long after interpolation and/or generalization. We develop an analytical explanation for the emergence of both delayed generalization and delayed robustness based on a new measure of the local complexity of a DNN's input-output mapping. Our local complexity measures the density of the so-called 'linear regions' (aka, spline partition regions) that tile the DNN input space, and serves as a utile progress measure for training. We provide the first evidence that for classification problems, the linear regions undergo a phase transition during training whereafter they migrate away from the training samples (making the DNN mapping smoother there) and towards the decision boundary (making the DNN mapping less smooth there). Grokking occurs post phase transition as a robust partition of the input space emerges thanks to the linearization of the DNN mapping around the training points. Website: https://bit.ly/grok-adversarial
Perspectives on the State and Future of Deep Learning - 2023
Dec 19, 2023The goal of this series is to chronicle opinions and issues in the field of machine learning as they stand today and as they change over time. The plan is to host this survey periodically until the AI singularity paperclip-frenzy-driven doomsday, keeping an updated list of topical questions and interviewing new community members for each edition. In this issue, we probed people's opinions on interpretable AI, the value of benchmarking in modern NLP, the state of progress towards understanding deep learning, and the future of academia.
Training Dynamics of Deep Network Linear Regions
Oct 19, 2023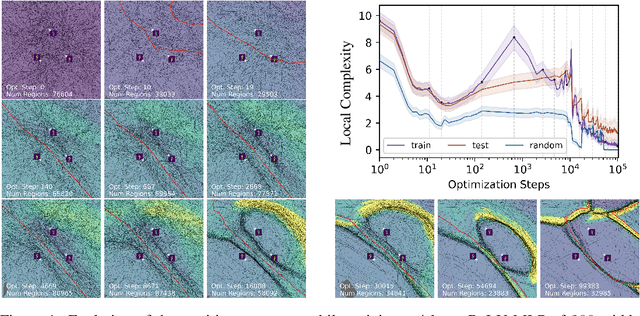



The study of Deep Network (DN) training dynamics has largely focused on the evolution of the loss function, evaluated on or around train and test set data points. In fact, many DN phenomenon were first introduced in literature with that respect, e.g., double descent, grokking. In this study, we look at the training dynamics of the input space partition or linear regions formed by continuous piecewise affine DNs, e.g., networks with (leaky)ReLU nonlinearities. First, we present a novel statistic that encompasses the local complexity (LC) of the DN based on the concentration of linear regions inside arbitrary dimensional neighborhoods around data points. We observe that during training, the LC around data points undergoes a number of phases, starting with a decreasing trend after initialization, followed by an ascent and ending with a final descending trend. Using exact visualization methods, we come across the perplexing observation that during the final LC descent phase of training, linear regions migrate away from training and test samples towards the decision boundary, making the DN input-output nearly linear everywhere else. We also observe that the different LC phases are closely related to the memorization and generalization performance of the DN, especially during grokking.