 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Students or Sycophantic Problem Solving? On Misconception Faithfulness of LLM Simulators
May 12, 2026Large language models (LLMs) can fluently generate student-like responses, making them attractive as simulated students for training and evaluating AI tutors and human educators. Yet such simulators are typically evaluated by output similarity to real students, not by whether they behave like students with coherent misconceptions during interaction. We introduce a controlled framework for evaluating misconception faithfulness, whether a simulator maintains a misconception-driven belief state and updates selectively when feedback addresses the underlying misconception. Central to our framework is a misconception-contrastive feedback protocol that compares targeted feedback against two controls: misaligned feedback (targeting a different but plausible misconception) and generic feedback (only identifying answer is wrong). We propose Selective Flip Score (SFS), which quantifies how much more often a simulator flips its answer under targeted feedback than under contrastive controls. Across seven LLMs (4B-120B), multiple datasets, and prompting strategies, simulators exhibit near-zero SFS, correcting their answers at similarly high rates regardless of feedback relevance. Further analyses reveal a sycophantic failure mode: models behave less like students with misconceptions but more like problem-solvers who treat any corrective signal as a cue to abandon the simulated belief and re-solve from internal knowledge. To address this, we develop a post-training pipeline spanning supervised fine-tuning (SFT), preference optimization, and reinforcement learning (RL) with an SFS-aligned reward; SFT yields notable gains up to +0.56, and SFS-aligned RL provides more consistent improvements than preference optimization. Our results establish misconception faithfulness as a challenging yet trainable property, motivating a shift from static output matching toward interactive, belief-aware student modeling.
When Can We Trust LLM Graders? Calibrating Confidence for Automated Assessment
Mar 31, 2026Large Language Models (LLMs) show promise for automated grading, but their outputs can be unreliable. Rather than improving grading accuracy directly, we address a complementary problem: \textit{predicting when an LLM grader is likely to be correct}. This enables selective automation where high-confidence predictions are processed automatically while uncertain cases are flagged for human review. We compare three confidence estimation methods (self-reported confidence, self-consistency voting, and token probability) across seven LLMs of varying scale (4B to 120B parameters) on three educational datasets: RiceChem (long-answer chemistry), SciEntsBank, and Beetle (short-answer science). Our experiments reveal that self-reported confidence consistently achieves the best calibration across all conditions (avg ECE 0.166 vs 0.229 for self-consistency). Surprisingly, self-consistency remains 38\% worse despite requiring 5$\times$ the inference cost. Larger models exhibit substantially better calibration though gains vary by dataset and method (e.g., a 28\% ECE reduction for self-reported), with GPT-OSS-120B achieving the best calibration (avg ECE 0.100) and strong discrimination (avg AUC 0.668). We also observe that confidence is strongly top-skewed across methods, creating a ``confidence floor'' that practitioners must account for when setting thresholds. These findings suggest that simply asking LLMs to report their confidence provides a practical approach for identifying reliable grading predictions. Code is available \href{https://github.com/sonkar-lab/llm_grading_calibration}{here}.
Circuit Complexity of Hierarchical Knowledge Tracing and Implications for Log-Precision Transformers
Mar 25, 2026Knowledge tracing models mastery over interconnected concepts, often organized by prerequisites. We analyze hierarchical prerequisite propagation through a circuit-complexity lens to clarify what is provable about transformer-style computation on deep concept hierarchies. Using recent results that log-precision transformers lie in logspace-uniform $\mathsf{TC}^0$, we formalize prerequisite-tree tasks including recursive-majority mastery propagation. Unconditionally, recursive-majority propagation lies in $\mathsf{NC}^1$ via $O(\log n)$-depth bounded-fanin circuits, while separating it from uniform $\mathsf{TC}^0$ would require major progress on open lower bounds. Under a monotonicity restriction, we obtain an unconditional barrier: alternating ALL/ANY prerequisite trees yield a strict depth hierarchy for \emph{monotone} threshold circuits. Empirically, transformer encoders trained on recursive-majority trees converge to permutation-invariant shortcuts; explicit structure alone does not prevent this, but auxiliary supervision on intermediate subtrees elicits structure-dependent computation and achieves near-perfect accuracy at depths 3--4. These findings motivate structure-aware objectives and iterative mechanisms for prerequisite-sensitive knowledge tracing on deep hierarchies.
Can LLMs Model Incorrect Student Reasoning? A Case Study on Distractor Generation
Mar 16, 2026Modeling plausible student misconceptions is critical for AI in education. In this work, we examine how large language models (LLMs) reason about misconceptions when generating multiple-choice distractors, a task that requires modeling incorrect yet plausible answers by coordinating solution knowledge, simulating student misconceptions, and evaluating plausibility. We introduce a taxonomy for analyzing the strategies used by state-of-the-art LLMs, examining their reasoning procedures and comparing them to established best practices in the learning sciences. Our structured analysis reveals a surprising alignment between their processes and best practices: the models typically solve the problem correctly first, then articulate and simulate multiple potential misconceptions, and finally select a set of distractors. An analysis of failure modes reveals that errors arise primarily from failures in recovering the correct solution and selecting among response candidates, rather than simulating errors or structuring the process. Consistent with these results, we find that providing the correct solution in the prompt improves alignment with human-authored distractors by 8%, highlighting the critical role of anchoring to the correct solution when generating plausible incorrect student reasoning. Overall, our analysis offers a structured and interpretable lens into LLMs' ability to model incorrect student reasoning and produce high-quality distractors.
MalruleLib: Large-Scale Executable Misconception Reasoning with Step Traces for Modeling Student Thinking in Mathematics
Jan 06, 2026Student mistakes in mathematics are often systematic: a learner applies a coherent but wrong procedure and repeats it across contexts. We introduce MalruleLib, a learning-science-grounded framework that translates documented misconceptions into executable procedures, drawing on 67 learning-science and mathematics education sources, and generates step-by-step traces of malrule-consistent student work. We formalize a core student-modeling problem as Malrule Reasoning Accuracy (MRA): infer a misconception from one worked mistake and predict the student's next answer under cross-template rephrasing. Across nine language models (4B-120B), accuracy drops from 66% on direct problem solving to 40% on cross-template misconception prediction. MalruleLib encodes 101 malrules over 498 parameterized problem templates and produces paired dual-path traces for both correct reasoning and malrule-consistent student reasoning. Because malrules are executable and templates are parameterizable, MalruleLib can generate over one million instances, enabling scalable supervision and controlled evaluation. Using MalruleLib, we observe cross-template degradations of 10-21%, while providing student step traces improves prediction by 3-15%. We release MalruleLib as infrastructure for educational AI that models student procedures across contexts, enabling diagnosis and feedback that targets the underlying misconception.
Do LLMs Make Mistakes Like Students? Exploring Natural Alignment between Language Models and Human Error Patterns
Feb 21, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various educational tasks, yet their alignment with human learning patterns, particularly in predicting which incorrect options students are most likely to select in multiple-choice questions (MCQs), remains underexplored. Our work investigates the relationship between LLM generation likelihood and student response distributions in MCQs with a specific focus on distractor selections. We collect a comprehensive dataset of MCQs with real-world student response distributions to explore two fundamental research questions: (1). RQ1 - Do the distractors that students more frequently select correspond to those that LLMs assign higher generation likelihood to? (2). RQ2 - When an LLM selects a incorrect choice, does it choose the same distractor that most students pick? Our experiments reveals moderate correlations between LLM-assigned probabilities and student selection patterns for distractors in MCQs. Additionally, when LLMs make mistakes, they are more likley to select the same incorrect answers that commonly mislead students, which is a pattern consistent across both small and large language models. Our work provides empirical evidence that despite LLMs' strong performance on generating educational content, there remains a gap between LLM's underlying reasoning process and human cognitive processes in identifying confusing distractors. Our findings also have significant implications for educational assessment development. The smaller language models could be efficiently utilized for automated distractor generation as they demonstrate similar patterns in identifying confusing answer choices as larger language models. This observed alignment between LLMs and student misconception patterns opens new opportunities for generating high-quality distractors that complement traditional human-designed distractors.
The Imitation Game for Educational AI
Feb 21, 2025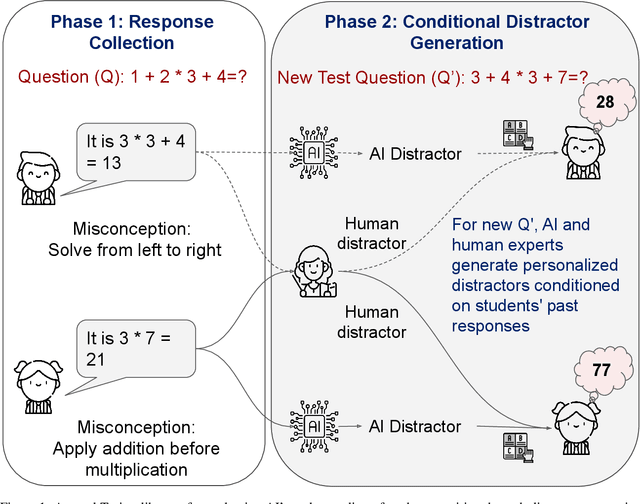
As artificial intelligence systems become increasingly prevalent in education, a fundamental challenge emerges: how can we verify if an AI truly understands how students think and reason? Traditional evaluation methods like measuring learning gains require lengthy studies confounded by numerous variables. We present a novel evaluation framework based on a two-phase Turing-like test. In Phase 1, students provide open-ended responses to questions, revealing natural misconceptions. In Phase 2, both AI and human experts, conditioned on each student's specific mistakes, generate distractors for new related questions. By analyzing whether students select AI-generated distractors at rates similar to human expert-generated ones, we can validate if the AI models student cognition. We prove this evaluation must be conditioned on individual responses - unconditioned approaches merely target common misconceptions. Through rigorous statistical sampling theory, we establish precise requirements for high-confidence validation. Our research positions conditioned distractor generation as a probe into an AI system's fundamental ability to model student thinking - a capability that enables adapting tutoring, feedback, and assessments to each student's specific needs.
LLM-based Cognitive Models of Students with Misconceptions
Oct 17, 2024



Accurately modeling student cognition is crucial for developing effective AI-driven educational technologies. A key challenge is creating realistic student models that satisfy two essential properties: (1) accurately replicating specific misconceptions, and (2) correctly solving problems where these misconceptions are not applicable. This dual requirement reflects the complex nature of student understanding, where misconceptions coexist with correct knowledge. This paper investigates whether Large Language Models (LLMs) can be instruction-tuned to meet this dual requirement and effectively simulate student thinking in algebra. We introduce MalAlgoPy, a novel Python library that generates datasets reflecting authentic student solution patterns through a graph-based representation of algebraic problem-solving. Utilizing MalAlgoPy, we define and examine Cognitive Student Models (CSMs) - LLMs instruction tuned to faithfully emulate realistic student behavior. Our findings reveal that LLMs trained on misconception examples can efficiently learn to replicate errors. However, the training diminishes the model's ability to solve problems correctly, particularly for problem types where the misconceptions are not applicable, thus failing to satisfy second property of CSMs. We demonstrate that by carefully calibrating the ratio of correct to misconception examples in the training data - sometimes as low as 0.25 - it is possible to develop CSMs that satisfy both properties. Our insights enhance our understanding of AI-based student models and pave the way for effective adaptive learning systems.
MalAlgoQA: A Pedagogical Approach for Evaluating Counterfactual Reasoning Abilities
Jul 01, 2024This paper introduces MalAlgoQA, a novel dataset designed to evaluate the counterfactual reasoning capabilities of Large Language Models (LLMs) through a pedagogical approach. The dataset comprises mathematics and reading comprehension questions, each accompanied by four answer choices and their corresponding rationales. We focus on the incorrect answer rationales, termed "malgorithms", which highlights flawed reasoning steps leading to incorrect answers and offers valuable insights into erroneous thought processes. We also propose the Malgorithm Identification task, where LLMs are assessed based on their ability to identify corresponding malgorithm given an incorrect answer choice. To evaluate the model performance, we introduce two metrics: Algorithm Identification Accuracy (AIA) for correct answer rationale identification, and Malgorithm Identification Accuracy (MIA) for incorrect answer rationale identification. The task is challenging since state-of-the-art LLMs exhibit significant drops in MIA as compared to AIA. Moreover, we find that the chain-of-thought prompting technique not only fails to consistently enhance MIA, but can also lead to underperformance compared to simple prompting. These findings hold significant implications for the development of more cognitively-inspired LLMs to improve their counterfactual reasoning abilities, particularly through a pedagogical perspective where understanding and rectifying student misconceptions are crucial.
Many-Shot Regurgitation (MSR) Prompting
May 13, 2024We introduce Many-Shot Regurgitation (MSR) prompting, a new black-box membership inference attack framework for examining verbatim content reproduction in large language models (LLMs). MSR prompting involves dividing the input text into multiple segments and creating a single prompt that includes a series of faux conversation rounds between a user and a language model to elicit verbatim regurgitation. We apply MSR prompting to diverse text sources, including Wikipedia articles and open educational resources (OER) textbooks, which provide high-quality, factual content and are continuously updated over time. For each source, we curate two dataset types: one that LLMs were likely exposed to during training ($D_{\rm pre}$) and another consisting of documents published after the models' training cutoff dates ($D_{\rm post}$). To quantify the occurrence of verbatim matches, we employ the Longest Common Substring algorithm and count the frequency of matches at different length thresholds. We then use statistical measures such as Cliff's delta, Kolmogorov-Smirnov (KS) distance, and Kruskal-Wallis H test to determine whether the distribution of verbatim matches differs significantly between $D_{\rm pre}$ and $D_{\rm post}$. Our findings reveal a striking difference in the distribution of verbatim matches between $D_{\rm pre}$ and $D_{\rm post}$, with the frequency of verbatim reproduction being significantly higher when LLMs (e.g. GPT models and LLaMAs) are prompted with text from datasets they were likely trained on. For instance, when using GPT-3.5 on Wikipedia articles, we observe a substantial effect size (Cliff's delta $= -0.984$) and a large KS distance ($0.875$) between the distributions of $D_{\rm pre}$ and $D_{\rm post}$. Our results provide compelling evidence that LLMs are more prone to reproducing verbatim content when the input text is likely sourced from their training data.