 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Imitation Game for Educational AI
Paper and Code
Feb 21, 2025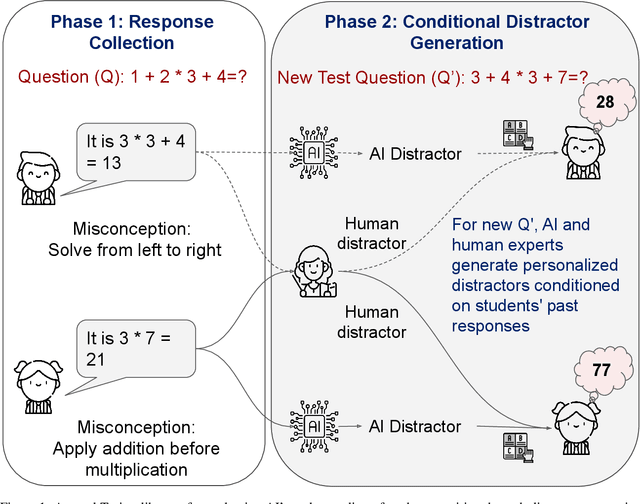
As artificial intelligence systems become increasingly prevalent in education, a fundamental challenge emerges: how can we verify if an AI truly understands how students think and reason? Traditional evaluation methods like measuring learning gains require lengthy studies confounded by numerous variables. We present a novel evaluation framework based on a two-phase Turing-like test. In Phase 1, students provide open-ended responses to questions, revealing natural misconceptions. In Phase 2, both AI and human experts, conditioned on each student's specific mistakes, generate distractors for new related questions. By analyzing whether students select AI-generated distractors at rates similar to human expert-generated ones, we can validate if the AI models student cognition. We prove this evaluation must be conditioned on individual responses - unconditioned approaches merely target common misconceptions. Through rigorous statistical sampling theory, we establish precise requirements for high-confidence validation. Our research positions conditioned distractor generation as a probe into an AI system's fundamental ability to model student thinking - a capability that enables adapting tutoring, feedback, and assessments to each student's specific needs.