 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalruleLib: Large-Scale Executable Misconception Reasoning with Step Traces for Modeling Student Thinking in Mathematics
Jan 06, 2026Student mistakes in mathematics are often systematic: a learner applies a coherent but wrong procedure and repeats it across contexts. We introduce MalruleLib, a learning-science-grounded framework that translates documented misconceptions into executable procedures, drawing on 67 learning-science and mathematics education sources, and generates step-by-step traces of malrule-consistent student work. We formalize a core student-modeling problem as Malrule Reasoning Accuracy (MRA): infer a misconception from one worked mistake and predict the student's next answer under cross-template rephrasing. Across nine language models (4B-120B), accuracy drops from 66% on direct problem solving to 40% on cross-template misconception prediction. MalruleLib encodes 101 malrules over 498 parameterized problem templates and produces paired dual-path traces for both correct reasoning and malrule-consistent student reasoning. Because malrules are executable and templates are parameterizable, MalruleLib can generate over one million instances, enabling scalable supervision and controlled evaluation. Using MalruleLib, we observe cross-template degradations of 10-21%, while providing student step traces improves prediction by 3-15%. We release MalruleLib as infrastructure for educational AI that models student procedures across contexts, enabling diagnosis and feedback that targets the underlying misconception.
Training LLM-based Tutors to Improve Student Learning Outcomes in Dialogues
Mar 09, 2025



Generative artificial intelligence (AI) has the potential to scale up personalized tutoring through large language models (LLMs). Recent AI tutors are adapted for the tutoring task by training or prompting LLMs to follow effective pedagogical principles, though they are not trained to maximize student learning throughout the course of a dialogue. Therefore, they may engage with students in a suboptimal way. We address this limitation by introducing an approach to train LLMs to generate tutor utterances that maximize the likelihood of student correctness, while still encouraging the model to follow good pedagogical practice. Specifically, we generate a set of candidate tutor utterances and score them using (1) an LLM-based student model to predict the chance of correct student responses and (2) a pedagogical rubric evaluated by GPT-4o. We then use the resulting data to train an open-source LLM, Llama 3.1 8B, using direct preference optimization. We show that tutor utterances generated by our model lead to significantly higher chances of correct student responses while maintaining the pedagogical quality of GPT-4o. We also conduct qualitative analyses and a human evaluation to demonstrate that our model generates high quality tutor utterances.
The Imitation Game for Educational AI
Feb 21, 2025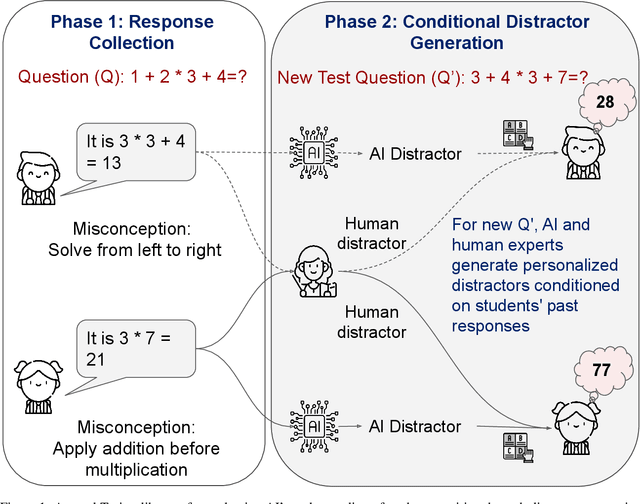
As artificial intelligence systems become increasingly prevalent in education, a fundamental challenge emerges: how can we verify if an AI truly understands how students think and reason? Traditional evaluation methods like measuring learning gains require lengthy studies confounded by numerous variables. We present a novel evaluation framework based on a two-phase Turing-like test. In Phase 1, students provide open-ended responses to questions, revealing natural misconceptions. In Phase 2, both AI and human experts, conditioned on each student's specific mistakes, generate distractors for new related questions. By analyzing whether students select AI-generated distractors at rates similar to human expert-generated ones, we can validate if the AI models student cognition. We prove this evaluation must be conditioned on individual responses - unconditioned approaches merely target common misconceptions. Through rigorous statistical sampling theory, we establish precise requirements for high-confidence validation. Our research positions conditioned distractor generation as a probe into an AI system's fundamental ability to model student thinking - a capability that enables adapting tutoring, feedback, and assessments to each student's specific needs.
Do LLMs Make Mistakes Like Students? Exploring Natural Alignment between Language Models and Human Error Patterns
Feb 21, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various educational tasks, yet their alignment with human learning patterns, particularly in predicting which incorrect options students are most likely to select in multiple-choice questions (MCQs), remains underexplored. Our work investigates the relationship between LLM generation likelihood and student response distributions in MCQs with a specific focus on distractor selections. We collect a comprehensive dataset of MCQs with real-world student response distributions to explore two fundamental research questions: (1). RQ1 - Do the distractors that students more frequently select correspond to those that LLMs assign higher generation likelihood to? (2). RQ2 - When an LLM selects a incorrect choice, does it choose the same distractor that most students pick? Our experiments reveals moderate correlations between LLM-assigned probabilities and student selection patterns for distractors in MCQs. Additionally, when LLMs make mistakes, they are more likley to select the same incorrect answers that commonly mislead students, which is a pattern consistent across both small and large language models. Our work provides empirical evidence that despite LLMs' strong performance on generating educational content, there remains a gap between LLM's underlying reasoning process and human cognitive processes in identifying confusing distractors. Our findings also have significant implications for educational assessment development. The smaller language models could be efficiently utilized for automated distractor generation as they demonstrate similar patterns in identifying confusing answer choices as larger language models. This observed alignment between LLMs and student misconception patterns opens new opportunities for generating high-quality distractors that complement traditional human-designed distractors.
LLM-based Cognitive Models of Students with Misconceptions
Oct 17, 2024



Accurately modeling student cognition is crucial for developing effective AI-driven educational technologies. A key challenge is creating realistic student models that satisfy two essential properties: (1) accurately replicating specific misconceptions, and (2) correctly solving problems where these misconceptions are not applicable. This dual requirement reflects the complex nature of student understanding, where misconceptions coexist with correct knowledge. This paper investigates whether Large Language Models (LLMs) can be instruction-tuned to meet this dual requirement and effectively simulate student thinking in algebra. We introduce MalAlgoPy, a novel Python library that generates datasets reflecting authentic student solution patterns through a graph-based representation of algebraic problem-solving. Utilizing MalAlgoPy, we define and examine Cognitive Student Models (CSMs) - LLMs instruction tuned to faithfully emulate realistic student behavior. Our findings reveal that LLMs trained on misconception examples can efficiently learn to replicate errors. However, the training diminishes the model's ability to solve problems correctly, particularly for problem types where the misconceptions are not applicable, thus failing to satisfy second property of CSMs. We demonstrate that by carefully calibrating the ratio of correct to misconception examples in the training data - sometimes as low as 0.25 - it is possible to develop CSMs that satisfy both properties. Our insights enhance our understanding of AI-based student models and pave the way for effective adaptive learning systems.
MalAlgoQA: A Pedagogical Approach for Evaluating Counterfactual Reasoning Abilities
Jul 01, 2024This paper introduces MalAlgoQA, a novel dataset designed to evaluate the counterfactual reasoning capabilities of Large Language Models (LLMs) through a pedagogical approach. The dataset comprises mathematics and reading comprehension questions, each accompanied by four answer choices and their corresponding rationales. We focus on the incorrect answer rationales, termed "malgorithms", which highlights flawed reasoning steps leading to incorrect answers and offers valuable insights into erroneous thought processes. We also propose the Malgorithm Identification task, where LLMs are assessed based on their ability to identify corresponding malgorithm given an incorrect answer choice. To evaluate the model performance, we introduce two metrics: Algorithm Identification Accuracy (AIA) for correct answer rationale identification, and Malgorithm Identification Accuracy (MIA) for incorrect answer rationale identification. The task is challenging since state-of-the-art LLMs exhibit significant drops in MIA as compared to AIA. Moreover, we find that the chain-of-thought prompting technique not only fails to consistently enhance MIA, but can also lead to underperformance compared to simple prompting. These findings hold significant implications for the development of more cognitively-inspired LLMs to improve their counterfactual reasoning abilities, particularly through a pedagogical perspective where understanding and rectifying student misconceptions are crucial.
Synthetic Context Generation for Question Generation
Jun 19, 2024Despite rapid advancements in large language models (LLMs), QG remains a challenging problem due to its complicated process, open-ended nature, and the diverse settings in which question generation occurs. A common approach to address these challenges involves fine-tuning smaller, custom models using datasets containing background context, question, and answer. However, obtaining suitable domain-specific datasets with appropriate context is often more difficult than acquiring question-answer pairs. In this paper, we investigate training QG models using synthetic contexts generated by LLMs from readily available question-answer pairs. We conduct a comprehensive study to answer critical research questions related to the performance of models trained on synthetic contexts and their potential impact on QG research and applications. Our empirical results reveal: 1) contexts are essential for QG tasks, even if they are synthetic; 2) fine-tuning smaller language models has the capability of achieving better performances as compared to prompting larger language models; and 3) synthetic context and real context could achieve comparable performances. These findings highlight the effectiveness of synthetic contexts in QG and paves the way for future advancements in the field.
Regressive Side Effects of Training Language Models to Mimic Student Misconceptions
Apr 23, 2024This paper presents a novel exploration into the regressive side effects of training Large Language Models (LLMs) to mimic student misconceptions for personalized education. We highlight the problem that as LLMs are trained to more accurately mimic student misconceptions, there is a compromise in the factual integrity and reasoning ability of the models. Our work involved training an LLM on a student-tutor dialogue dataset to predict student responses. The results demonstrated a decrease in the model's performance across multiple benchmark datasets, including the ARC reasoning challenge and TruthfulQA, which evaluates the truthfulness of model's generated responses. Furthermore, the HaluEval Dial dataset, used for hallucination detection, and MemoTrap, a memory-based task dataset, also reported a decline in the model accuracy. To combat these side effects, we introduced a "hallucination token" technique. This token, appended at the beginning of each student response during training, instructs the model to switch between mimicking student misconceptions and providing factually accurate responses. Despite the significant improvement across all datasets, the technique does not completely restore the LLM's baseline performance, indicating the need for further research in this area. This paper contributes to the ongoing discussion on the use of LLMs for student modeling, emphasizing the need for a balance between personalized education and factual accuracy.
Marking: Visual Grading with Highlighting Errors and Annotating Missing Bits
Apr 22, 2024
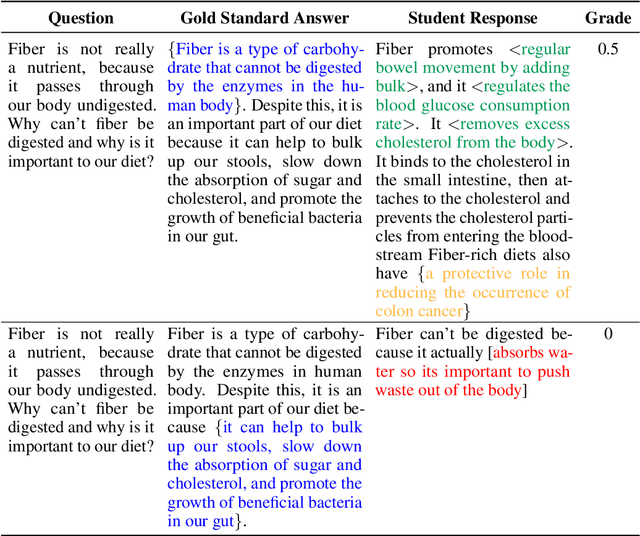
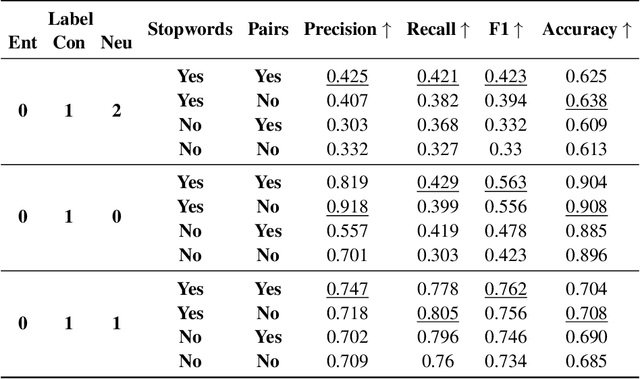
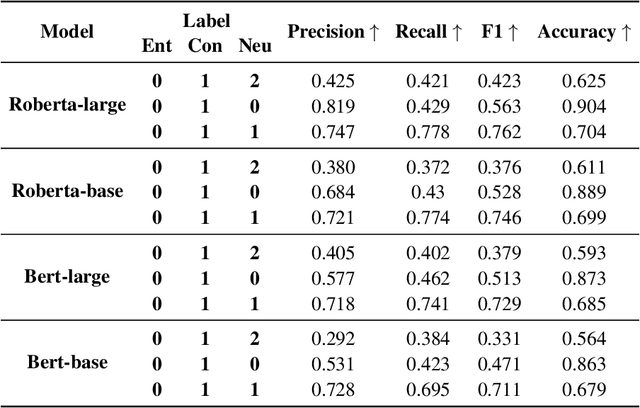
In this paper, we introduce "Marking", a novel grading task that enhances automated grading systems by performing an in-depth analysis of student responses and providing students with visual highlights. Unlike traditional systems that provide binary scores, "marking" identifies and categorizes segments of the student response as correct, incorrect, or irrelevant and detects omissions from gold answers. We introduce a new dataset meticulously curated by Subject Matter Experts specifically for this task. We frame "Marking" as an extension of the Natural Language Inference (NLI) task, which is extensively explored in the field of Natural Language Processing. The gold answer and the student response play the roles of premise and hypothesis in NLI, respectively. We subsequently train language models to identify entailment, contradiction, and neutrality from student response, akin to NLI, and with the added dimension of identifying omissions from gold answers. Our experimental setup involves the use of transformer models, specifically BERT and RoBERTa, and an intelligent training step using the e-SNLI dataset. We present extensive baseline results highlighting the complexity of the "Marking" task, which sets a clear trajectory for the upcoming study. Our work not only opens up new avenues for research in AI-powered educational assessment tools, but also provides a valuable benchmark for the AI in education community to engage with and improve upon in the future. The code and dataset can be found at https://github.com/luffycodes/marking.
Novice Learner and Expert Tutor: Evaluating Math Reasoning Abilities of Large Language Models with Misconceptions
Oct 03, 2023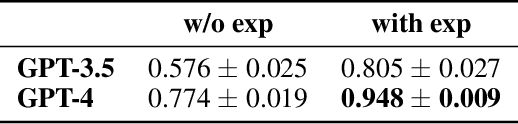

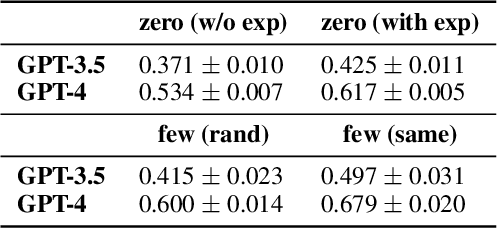
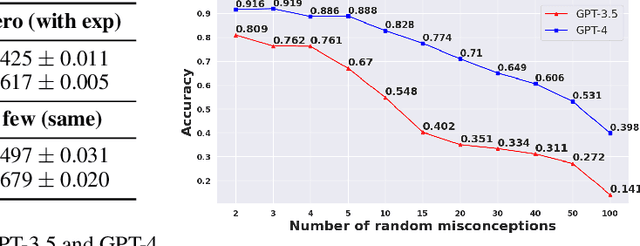
We propose novel evaluations for mathematical reasoning capabilities of Large Language Models (LLMs) based on mathematical misconceptions. Our primary approach is to simulate LLMs as a novice learner and an expert tutor, aiming to identify the incorrect answer to math question resulted from a specific misconception and to recognize the misconception(s) behind an incorrect answer, respectively. Contrary to traditional LLMs-based mathematical evaluations that focus on answering math questions correctly, our approach takes inspirations from principles in educational learning sciences. We explicitly ask LLMs to mimic a novice learner by answering questions in a specific incorrect manner based on incomplete knowledge; and to mimic an expert tutor by identifying misconception(s) corresponding to an incorrect answer to a question. Using simple grade-school math problems, our experiments reveal that, while LLMs can easily answer these questions correctly, they struggle to identify 1) the incorrect answer corresponding to specific incomplete knowledge (misconceptions); 2) the misconceptions that explain particular incorrect answers. Our study indicates new opportunities for enhancing LLMs' math reasoning capabilities, especially on developing robust student simulation and expert tutoring models in the educational applications such as intelligent tutoring systems.