 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarking: Visual Grading with Highlighting Errors and Annotating Missing Bits
Paper and Code

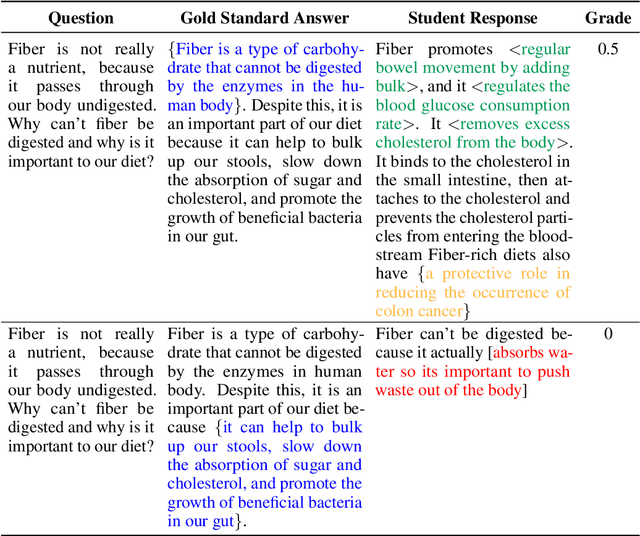
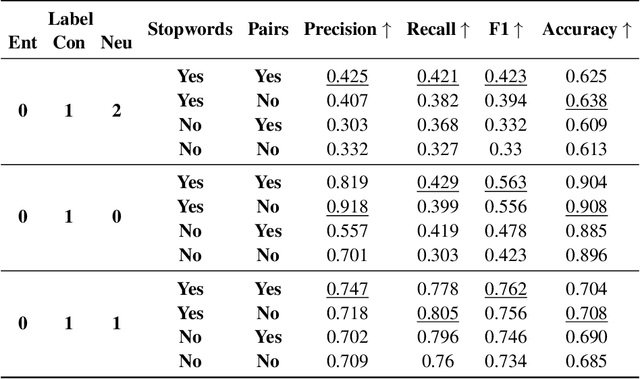
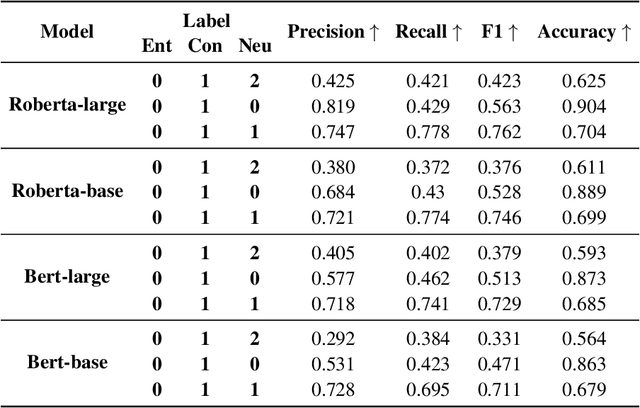
In this paper, we introduce "Marking", a novel grading task that enhances automated grading systems by performing an in-depth analysis of student responses and providing students with visual highlights. Unlike traditional systems that provide binary scores, "marking" identifies and categorizes segments of the student response as correct, incorrect, or irrelevant and detects omissions from gold answers. We introduce a new dataset meticulously curated by Subject Matter Experts specifically for this task. We frame "Marking" as an extension of the Natural Language Inference (NLI) task, which is extensively explored in the field of Natural Language Processing. The gold answer and the student response play the roles of premise and hypothesis in NLI, respectively. We subsequently train language models to identify entailment, contradiction, and neutrality from student response, akin to NLI, and with the added dimension of identifying omissions from gold answers. Our experimental setup involves the use of transformer models, specifically BERT and RoBERTa, and an intelligent training step using the e-SNLI dataset. We present extensive baseline results highlighting the complexity of the "Marking" task, which sets a clear trajectory for the upcoming study. Our work not only opens up new avenues for research in AI-powered educational assessment tools, but also provides a valuable benchmark for the AI in education community to engage with and improve upon in the future. The code and dataset can be found at https://github.com/luffycodes/marking.