 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Soliloquies for Accurate Calculations in Large Language Models
Sep 21, 2023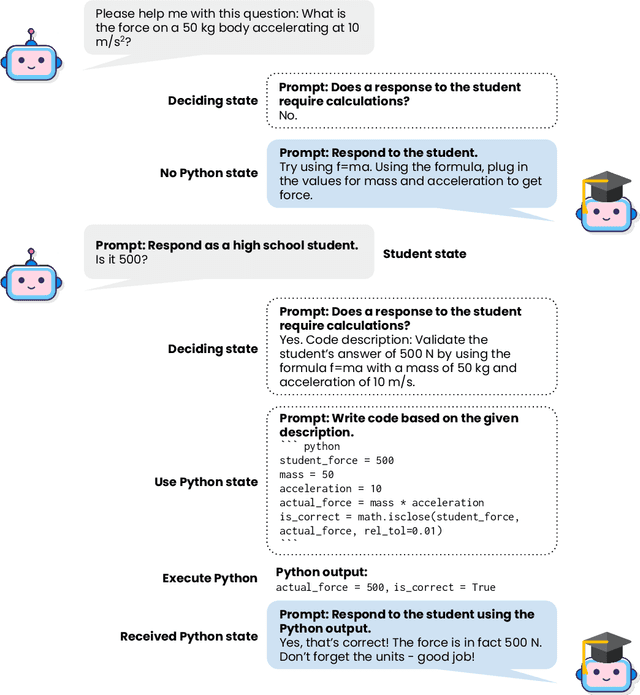
High-quality conversational datasets are integral to the successful development of Intelligent Tutoring Systems (ITS) that employ a Large Language Model (LLM) backend. These datasets, when used to fine-tune the LLM backend, significantly enhance the quality of interactions between students and ITS. A common strategy for developing these datasets involves generating synthetic student-teacher dialogues using advanced GPT-4 models. However, challenges arise when these dialogues demand complex calculations, common in subjects like physics. Despite its advanced capabilities, GPT-4's performance falls short in reliably handling even simple multiplication tasks, marking a significant limitation in its utility for these subjects. To address these challenges, this paper introduces an innovative stateful prompt design. Our approach generates a mock conversation between a student and a tutorbot, both roles simulated by GPT-4. Each student response triggers a soliloquy (an inner monologue) in the GPT-tutorbot, which assesses whether its response would necessitate calculations. If so, it proceeds to script the required code in Python and then uses the resulting output to construct its response to the student. Our approach notably enhances the quality of synthetic conversation datasets, especially for subjects that are calculation-intensive. Our findings show that our Higgs model -- a LLaMA finetuned with datasets generated through our novel stateful prompt design -- proficiently utilizes Python for computations. Consequently, finetuning with our datasets enriched with code soliloquies enhances not just the accuracy but also the computational reliability of Higgs' responses.
CLASS Meet SPOCK: An Education Tutoring Chatbot based on Learning Science Principles
May 22, 2023


We present a design framework called Conversational Learning with Analytical Step-by-Step Strategies (CLASS) for developing high-performance Intelligent Tutoring Systems (ITS). The CLASS framework aims to empower ITS with with two critical capabilities: imparting tutor-like step-by-step guidance and enabling tutor-like conversations in natural language to effectively engage learners. To empower ITS with the aforementioned capabilities, the CLASS framework employs two carefully curated synthetic datasets. The first scaffolding dataset encompasses a variety of elements, including problems, their corresponding subproblems, hints, incorrect solutions, and tailored feedback. This dataset provides ITS with essential problem-solving strategies necessary for guiding students through each step of the conversation. The second conversational dataset contains simulated student-tutor conversations that involve the application of problem-solving strategies learned from the first dataset. In the second dataset, the tutoring system adheres to a pre-defined response template, which helps to maintain consistency and structure in ITS's responses during its interactions. This structured methodology facilitates seamless integration of user feedback and yields valuable insights into ITS's internal decision-making process, allowing for continuous refinement and improvement of the system. We also present a proof-of-concept ITS, referred to as SPOCK, trained using the CLASS framework with a focus on college level introductory biology content. A carefully constructed protocol was developed for SPOCK's preliminary evaluation, examining aspects such as the factual accuracy and relevance of its responses. Experts in the field of biology offered favorable remarks, particularly highlighting SPOCK's capability to break down questions into manageable subproblems and provide step-by-step guidance to students.