 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalruleLib: Large-Scale Executable Misconception Reasoning with Step Traces for Modeling Student Thinking in Mathematics
Jan 06, 2026Student mistakes in mathematics are often systematic: a learner applies a coherent but wrong procedure and repeats it across contexts. We introduce MalruleLib, a learning-science-grounded framework that translates documented misconceptions into executable procedures, drawing on 67 learning-science and mathematics education sources, and generates step-by-step traces of malrule-consistent student work. We formalize a core student-modeling problem as Malrule Reasoning Accuracy (MRA): infer a misconception from one worked mistake and predict the student's next answer under cross-template rephrasing. Across nine language models (4B-120B), accuracy drops from 66% on direct problem solving to 40% on cross-template misconception prediction. MalruleLib encodes 101 malrules over 498 parameterized problem templates and produces paired dual-path traces for both correct reasoning and malrule-consistent student reasoning. Because malrules are executable and templates are parameterizable, MalruleLib can generate over one million instances, enabling scalable supervision and controlled evaluation. Using MalruleLib, we observe cross-template degradations of 10-21%, while providing student step traces improves prediction by 3-15%. We release MalruleLib as infrastructure for educational AI that models student procedures across contexts, enabling diagnosis and feedback that targets the underlying misconception.
The Imitation Game for Educational AI
Feb 21, 2025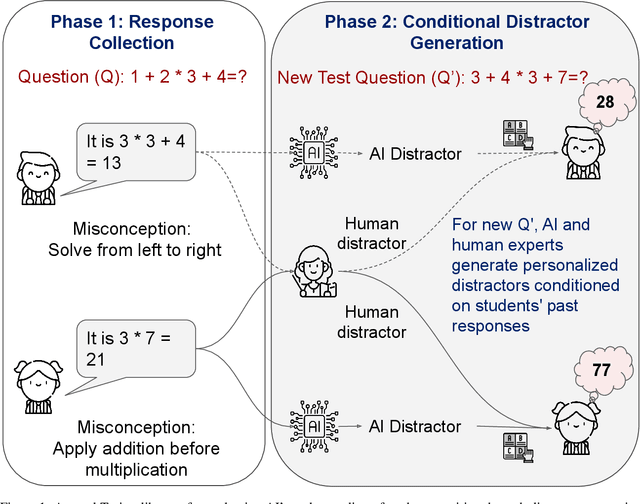
As artificial intelligence systems become increasingly prevalent in education, a fundamental challenge emerges: how can we verify if an AI truly understands how students think and reason? Traditional evaluation methods like measuring learning gains require lengthy studies confounded by numerous variables. We present a novel evaluation framework based on a two-phase Turing-like test. In Phase 1, students provide open-ended responses to questions, revealing natural misconceptions. In Phase 2, both AI and human experts, conditioned on each student's specific mistakes, generate distractors for new related questions. By analyzing whether students select AI-generated distractors at rates similar to human expert-generated ones, we can validate if the AI models student cognition. We prove this evaluation must be conditioned on individual responses - unconditioned approaches merely target common misconceptions. Through rigorous statistical sampling theory, we establish precise requirements for high-confidence validation. Our research positions conditioned distractor generation as a probe into an AI system's fundamental ability to model student thinking - a capability that enables adapting tutoring, feedback, and assessments to each student's specific needs.
LLM-based Cognitive Models of Students with Misconceptions
Oct 17, 2024



Accurately modeling student cognition is crucial for developing effective AI-driven educational technologies. A key challenge is creating realistic student models that satisfy two essential properties: (1) accurately replicating specific misconceptions, and (2) correctly solving problems where these misconceptions are not applicable. This dual requirement reflects the complex nature of student understanding, where misconceptions coexist with correct knowledge. This paper investigates whether Large Language Models (LLMs) can be instruction-tuned to meet this dual requirement and effectively simulate student thinking in algebra. We introduce MalAlgoPy, a novel Python library that generates datasets reflecting authentic student solution patterns through a graph-based representation of algebraic problem-solving. Utilizing MalAlgoPy, we define and examine Cognitive Student Models (CSMs) - LLMs instruction tuned to faithfully emulate realistic student behavior. Our findings reveal that LLMs trained on misconception examples can efficiently learn to replicate errors. However, the training diminishes the model's ability to solve problems correctly, particularly for problem types where the misconceptions are not applicable, thus failing to satisfy second property of CSMs. We demonstrate that by carefully calibrating the ratio of correct to misconception examples in the training data - sometimes as low as 0.25 - it is possible to develop CSMs that satisfy both properties. Our insights enhance our understanding of AI-based student models and pave the way for effective adaptive learning systems.
Discovering Malicious Signatures in Software from Structural Interactions
Dec 19, 2023
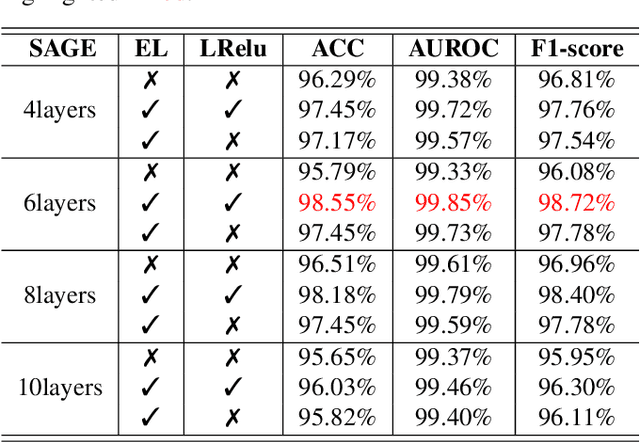
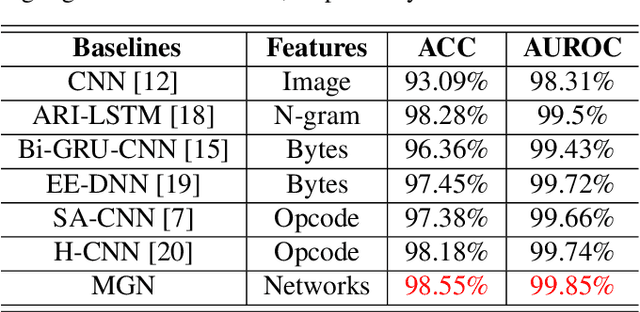
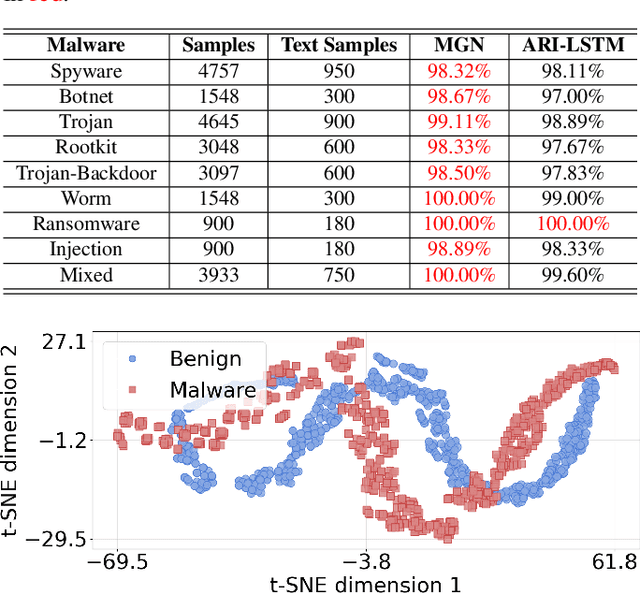
Malware represents a significant security concern in today's digital landscape, as it can destroy or disable operating systems, steal sensitive user information, and occupy valuable disk space. However, current malware detection methods, such as static-based and dynamic-based approaches, struggle to identify newly developed (``zero-day") malware and are limited by customized virtual machine (VM) environments. To overcome these limitations, we propose a novel malware detection approach that leverages deep learning, mathematical techniques, and network science. Our approach focuses on static and dynamic analysis and utilizes the Low-Level Virtual Machine (LLVM) to profile applications within a complex network. The generated network topologies are input into the GraphSAGE architecture to efficiently distinguish between benign and malicious software applications, with the operation names denoted as node features. Importantly, the GraphSAGE models analyze the network's topological geometry to make predictions, enabling them to detect state-of-the-art malware and prevent potential damage during execution in a VM. To evaluate our approach, we conduct a study on a dataset comprising source code from 24,376 applications, specifically written in C/C++, sourced directly from widely-recognized malware and various types of benign software. The results show a high detection performance with an Area Under the Receiver Operating Characteristic Curve (AUROC) of 99.85%. Our approach marks a substantial improvement in malware detection, providing a notably more accurate and efficient solution when compared to current state-of-the-art malware detection methods.
Leader-Follower Neural Networks with Local Error Signals Inspired by Complex Collectives
Oct 11, 2023The collective behavior of a network with heterogeneous, resource-limited information processing units (e.g., group of fish, flock of birds, or network of neurons) demonstrates high self-organization and complexity. These emergent properties arise from simple interaction rules where certain individuals can exhibit leadership-like behavior and influence the collective activity of the group. Motivated by the intricacy of these collectives, we propose a neural network (NN) architecture inspired by the rules observed in nature's collective ensembles. This NN structure contains workers that encompass one or more information processing units (e.g., neurons, filters, layers, or blocks of layers). Workers are either leaders or followers, and we train a leader-follower neural network (LFNN) by leveraging local error signals and optionally incorporating backpropagation (BP) and global loss. We investigate worker behavior and evaluate LFNNs through extensive experimentation. Our LFNNs trained with local error signals achieve significantly lower error rates than previous BP-free algorithms on MNIST and CIFAR-10 and even surpass BP-enabled baselines. In the case of ImageNet, our LFNN-l demonstrates superior scalability and outperforms previous BP-free algorithms by a significant margin.
Code Soliloquies for Accurate Calculations in Large Language Models
Sep 21, 2023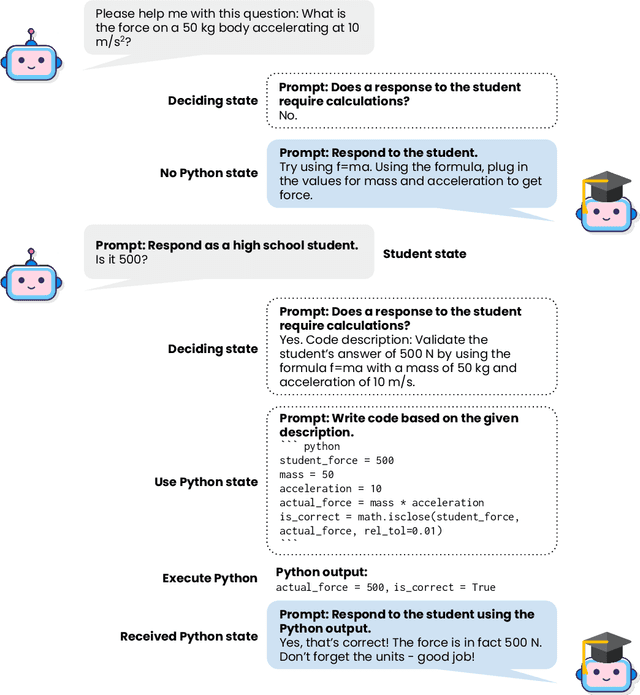
High-quality conversational datasets are integral to the successful development of Intelligent Tutoring Systems (ITS) that employ a Large Language Model (LLM) backend. These datasets, when used to fine-tune the LLM backend, significantly enhance the quality of interactions between students and ITS. A common strategy for developing these datasets involves generating synthetic student-teacher dialogues using advanced GPT-4 models. However, challenges arise when these dialogues demand complex calculations, common in subjects like physics. Despite its advanced capabilities, GPT-4's performance falls short in reliably handling even simple multiplication tasks, marking a significant limitation in its utility for these subjects. To address these challenges, this paper introduces an innovative stateful prompt design. Our approach generates a mock conversation between a student and a tutorbot, both roles simulated by GPT-4. Each student response triggers a soliloquy (an inner monologue) in the GPT-tutorbot, which assesses whether its response would necessitate calculations. If so, it proceeds to script the required code in Python and then uses the resulting output to construct its response to the student. Our approach notably enhances the quality of synthetic conversation datasets, especially for subjects that are calculation-intensive. Our findings show that our Higgs model -- a LLaMA finetuned with datasets generated through our novel stateful prompt design -- proficiently utilizes Python for computations. Consequently, finetuning with our datasets enriched with code soliloquies enhances not just the accuracy but also the computational reliability of Higgs' responses.