 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovering Human Action Space for Computer Use: Data Synthesis and Benchmark
May 12, 2026Computer-use agents (CUAs) automate on-screen work, as illustrated by GPT-5.4 and Claude. Yet their reliability on complex, low-frequency interactions is still poor, limiting user trust. Our analysis of failure cases from advanced models suggests a long-tail pattern in GUI operations, where a relatively small fraction of complex and diverse interactions accounts for a disproportionate share of task failures. We hypothesize that this issue largely stems from the scarcity of data for complex interactions. To address this problem, we propose a new benchmark CUActSpot for evaluating models' capabilities on complex interactions across five modalities: GUI, text, table, canvas, and natural image, as well as a variety of actions (click, drag, draw, etc.), covering a broader range of interaction types than prior click-centric benchmarks that focus mainly on GUI widgets. We also design a renderer-based data-synthesis pipeline: scenes are automatically generated for each modality, screenshots and element coordinates are recorded, and an LLM produces matching instructions and action traces. After training on this corpus, our Phi-Ground-Any-4B outperforms open-source models with fewer than 32B parameters. We will release our benchmark, data, code, and models at https://github.com/microsoft/Phi-Ground.git
EMoE: Eigenbasis-Guided Routing for Mixture-of-Experts
Jan 17, 2026The relentless scaling of deep learning models has led to unsustainable computational demands, positioning Mixture-of-Experts (MoE) architectures as a promising path towards greater efficiency. However, MoE models are plagued by two fundamental challenges: 1) a load imbalance problem known as the``rich get richer" phenomenon, where a few experts are over-utilized, and 2) an expert homogeneity problem, where experts learn redundant representations, negating their purpose. Current solutions typically employ an auxiliary load-balancing loss that, while mitigating imbalance, often exacerbates homogeneity by enforcing uniform routing at the expense of specialization. To resolve this, we introduce the Eigen-Mixture-of-Experts (EMoE), a novel architecture that leverages a routing mechanism based on a learned orthonormal eigenbasis. EMoE projects input tokens onto this shared eigenbasis and routes them based on their alignment with the principal components of the feature space. This principled, geometric partitioning of data intrinsically promotes both balanced expert utilization and the development of diverse, specialized experts, all without the need for a conflicting auxiliary loss function. Our code is publicly available at https://github.com/Belis0811/EMoE.
ERMoE: Eigen-Reparameterized Mixture-of-Experts for Stable Routing and Interpretable Specialization
Nov 14, 2025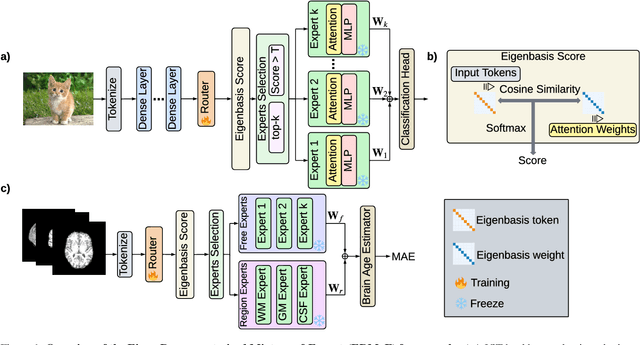
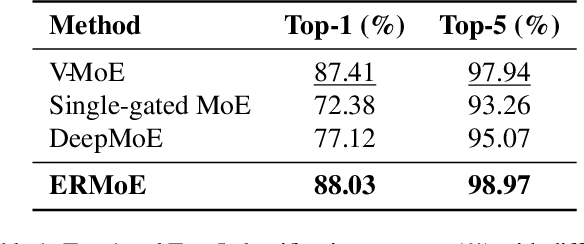
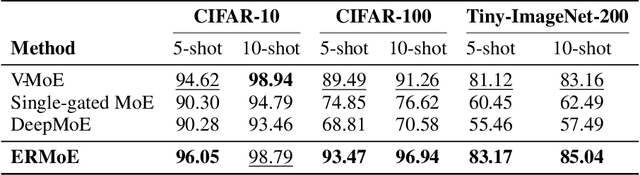
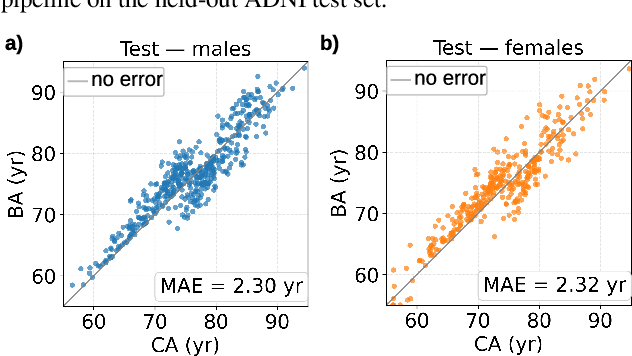
Mixture-of-Experts (MoE) architectures expand model capacity by sparsely activating experts but face two core challenges: misalignment between router logits and each expert's internal structure leads to unstable routing and expert underutilization, and load imbalances create straggler bottlenecks. Standard solutions, such as auxiliary load-balancing losses, can reduce load disparities but often weaken expert specialization and hurt downstream performance. To address these issues, we propose ERMoE, a sparse MoE transformer that reparameterizes each expert in a learned orthonormal eigenbasis and replaces learned gating logits with an "Eigenbasis Score", defined as the cosine similarity between input features and an expert's basis. This content-aware routing ties token assignments directly to experts' representation spaces, stabilizing utilization and promoting interpretable specialization without sacrificing sparsity. Crucially, ERMoE removes the need for explicit balancing losses and avoids the interfering gradients they introduce. We show that ERMoE achieves state-of-the-art accuracy on ImageNet classification and cross-modal image-text retrieval benchmarks (e.g., COCO, Flickr30K), while naturally producing flatter expert load distributions. Moreover, a 3D MRI variant (ERMoE-ba) improves brain age prediction accuracy by more than 7\% and yields anatomically interpretable expert specializations. ERMoE thus introduces a new architectural principle for sparse expert models that directly addresses routing instabilities and enables improved performance with scalable, interpretable specialization.
Unlocking Deep Learning: A BP-Free Approach for Parallel Block-Wise Training of Neural Networks
Dec 20, 2023



Backpropagation (BP) has been a successful optimization technique for deep learning models. However, its limitations, such as backward- and update-locking, and its biological implausibility, hinder the concurrent updating of layers and do not mimic the local learning processes observed in the human brain. To address these issues, recent research has suggested using local error signals to asynchronously train network blocks. However, this approach often involves extensive trial-and-error iterations to determine the best configuration for local training. This includes decisions on how to decouple network blocks and which auxiliary networks to use for each block. In our work, we introduce a novel BP-free approach: a block-wise BP-free (BWBPF) neural network that leverages local error signals to optimize distinct sub-neural networks separately, where the global loss is only responsible for updating the output layer. The local error signals used in the BP-free model can be computed in parallel, enabling a potential speed-up in the weight update process through parallel implementation. Our experimental results consistently show that this approach can identify transferable decoupled architectures for VGG and ResNet variations, outperforming models trained with end-to-end backpropagation and other state-of-the-art block-wise learning techniques on datasets such as CIFAR-10 and Tiny-ImageNet. The code is released at https://github.com/Belis0811/BWBPF.
Discovering Malicious Signatures in Software from Structural Interactions
Dec 19, 2023
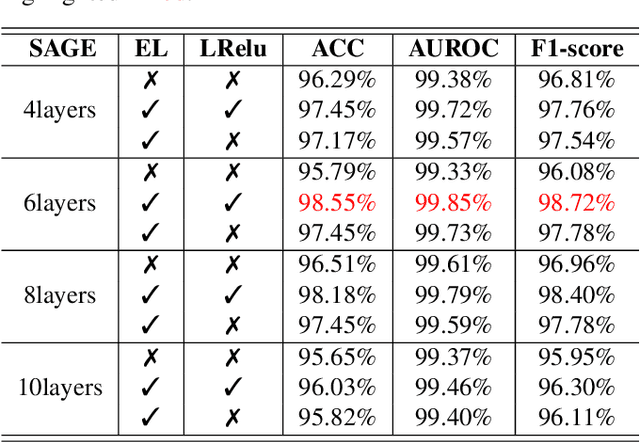
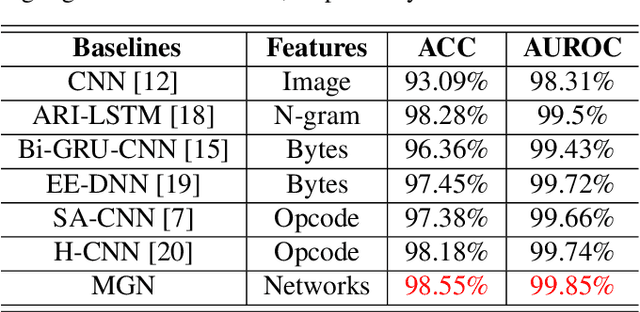
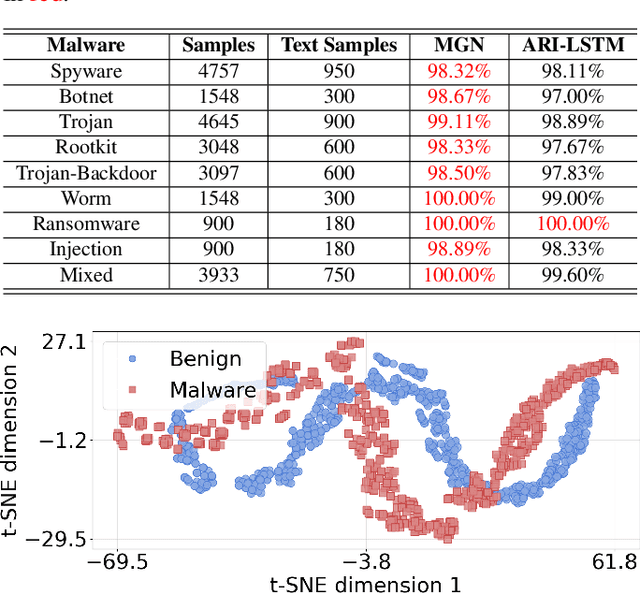
Malware represents a significant security concern in today's digital landscape, as it can destroy or disable operating systems, steal sensitive user information, and occupy valuable disk space. However, current malware detection methods, such as static-based and dynamic-based approaches, struggle to identify newly developed (``zero-day") malware and are limited by customized virtual machine (VM) environments. To overcome these limitations, we propose a novel malware detection approach that leverages deep learning, mathematical techniques, and network science. Our approach focuses on static and dynamic analysis and utilizes the Low-Level Virtual Machine (LLVM) to profile applications within a complex network. The generated network topologies are input into the GraphSAGE architecture to efficiently distinguish between benign and malicious software applications, with the operation names denoted as node features. Importantly, the GraphSAGE models analyze the network's topological geometry to make predictions, enabling them to detect state-of-the-art malware and prevent potential damage during execution in a VM. To evaluate our approach, we conduct a study on a dataset comprising source code from 24,376 applications, specifically written in C/C++, sourced directly from widely-recognized malware and various types of benign software. The results show a high detection performance with an Area Under the Receiver Operating Characteristic Curve (AUROC) of 99.85%. Our approach marks a substantial improvement in malware detection, providing a notably more accurate and efficient solution when compared to current state-of-the-art malware detection methods.
Leader-Follower Neural Networks with Local Error Signals Inspired by Complex Collectives
Oct 11, 2023
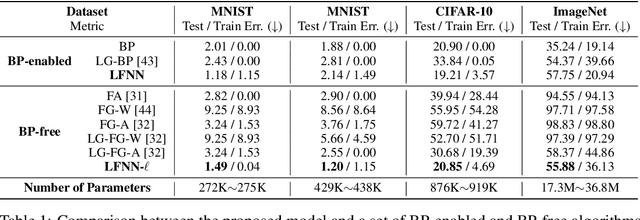


The collective behavior of a network with heterogeneous, resource-limited information processing units (e.g., group of fish, flock of birds, or network of neurons) demonstrates high self-organization and complexity. These emergent properties arise from simple interaction rules where certain individuals can exhibit leadership-like behavior and influence the collective activity of the group. Motivated by the intricacy of these collectives, we propose a neural network (NN) architecture inspired by the rules observed in nature's collective ensembles. This NN structure contains workers that encompass one or more information processing units (e.g., neurons, filters, layers, or blocks of layers). Workers are either leaders or followers, and we train a leader-follower neural network (LFNN) by leveraging local error signals and optionally incorporating backpropagation (BP) and global loss. We investigate worker behavior and evaluate LFNNs through extensive experimentation. Our LFNNs trained with local error signals achieve significantly lower error rates than previous BP-free algorithms on MNIST and CIFAR-10 and even surpass BP-enabled baselines. In the case of ImageNet, our LFNN-l demonstrates superior scalability and outperforms previous BP-free algorithms by a significant margin.
Fractional dynamics foster deep learning of COPD stage prediction
Mar 13, 2023Chronic obstructive pulmonary disease (COPD) is one of the leading causes of death worldwide. Current COPD diagnosis (i.e., spirometry) could be unreliable because the test depends on an adequate effort from the tester and testee. Moreover, the early diagnosis of COPD is challenging. We address COPD detection by constructing two novel physiological signals datasets (4432 records from 54 patients in the WestRo COPD dataset and 13824 medical records from 534 patients in the WestRo Porti COPD dataset). The authors demonstrate their complex coupled fractal dynamical characteristics and perform a fractional-order dynamics deep learning analysis to diagnose COPD. The authors found that the fractional-order dynamical modeling can extract distinguishing signatures from the physiological signals across patients with all COPD stages from stage 0 (healthy) to stage 4 (very severe). They use the fractional signatures to develop and train a deep neural network that predicts COPD stages based on the input features (such as thorax breathing effort, respiratory rate, or oxygen saturation). The authors show that the fractional dynamic deep learning model (FDDLM) achieves a COPD prediction accuracy of 98.66% and can serve as a robust alternative to spirometry. The FDDLM also has high accuracy when validated on a dataset with different physiological signals.
Raising The Limit Of Image Rescaling Using Auxiliary Encoding
Mar 12, 2023Normalizing flow models using invertible neural networks (INN) have been widely investigated for successful generative image super-resolution (SR) by learning the transformation between the normal distribution of latent variable $z$ and the conditional distribution of high-resolution (HR) images gave a low-resolution (LR) input. Recently, image rescaling models like IRN utilize the bidirectional nature of INN to push the performance limit of image upscaling by optimizing the downscaling and upscaling steps jointly. While the random sampling of latent variable $z$ is useful in generating diverse photo-realistic images, it is not desirable for image rescaling when accurate restoration of the HR image is more important. Hence, in places of random sampling of $z$, we propose auxiliary encoding modules to further push the limit of image rescaling performance. Two options to store the encoded latent variables in downscaled LR images, both readily supported in existing image file format, are proposed. One is saved as the alpha-channel, the other is saved as meta-data in the image header, and the corresponding modules are denoted as suffixes -A and -M respectively. Optimal network architectural changes are investigated for both options to demonstrate their effectiveness in raising the rescaling performance limit on different baseline models including IRN and DLV-IRN.
Coupled Multiwavelet Neural Operator Learning for Coupled Partial Differential Equations
Mar 04, 2023



Coupled partial differential equations (PDEs) are key tasks in modeling the complex dynamics of many physical processes. Recently, neural operators have shown the ability to solve PDEs by learning the integral kernel directly in Fourier/Wavelet space, so the difficulty for solving the coupled PDEs depends on dealing with the coupled mappings between the functions. Towards this end, we propose a \textit{coupled multiwavelets neural operator} (CMWNO) learning scheme by decoupling the coupled integral kernels during the multiwavelet decomposition and reconstruction procedures in the Wavelet space. The proposed model achieves significantly higher accuracy compared to previous learning-based solvers in solving the coupled PDEs including Gray-Scott (GS) equations and the non-local mean field game (MFG) problem. According to our experimental results, the proposed model exhibits a $2\times \sim 4\times$ improvement relative $L$2 error compared to the best results from the state-of-the-art models.
* Accepted to ICLR 2023
Non-Markovian Reinforcement Learning using Fractional Dynamics
Jul 29, 2021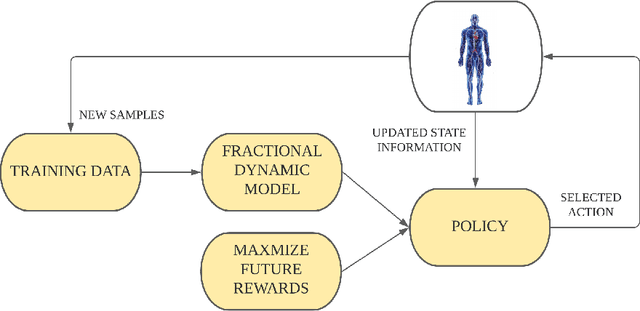
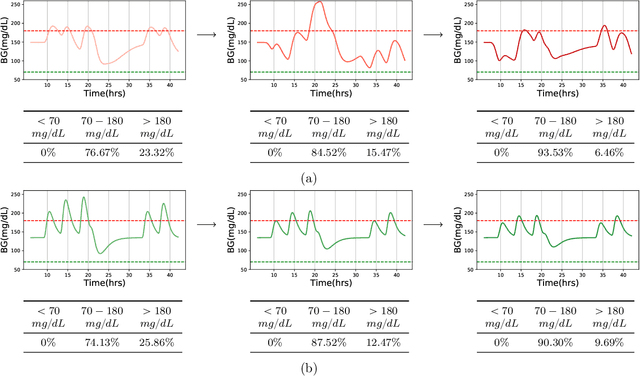
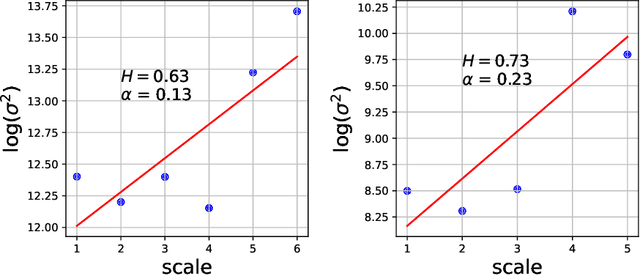
Reinforcement learning (RL) is a technique to learn the control policy for an agent that interacts with a stochastic environment. In any given state, the agent takes some action, and the environment determines the probability distribution over the next state as well as gives the agent some reward. Most RL algorithms typically assume that the environment satisfies Markov assumptions (i.e. the probability distribution over the next state depends only on the current state). In this paper, we propose a model-based RL technique for a system that has non-Markovian dynamics. Such environments are common in many real-world applications such as in human physiology, biological systems, material science, and population dynamics. Model-based RL (MBRL) techniques typically try to simultaneously learn a model of the environment from the data, as well as try to identify an optimal policy for the learned model. We propose a technique where the non-Markovianity of the system is modeled through a fractional dynamical system. We show that we can quantify the difference in the performance of an MBRL algorithm that uses bounded horizon model predictive control from the optimal policy. Finally, we demonstrate our proposed framework on a pharmacokinetic model of human blood glucose dynamics and show that our fractional models can capture distant correlations on real-world datasets.