 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Complexity of Brain MRI reveals age-associated patterns
Jan 23, 2026We adapt structural complexity analysis to three-dimensional signals, with an emphasis on brain magnetic resonance imaging (MRI). This framework captures the multiscale organization of volumetric data by coarse-graining the signal at progressively larger spatial scales and quantifying the information lost between successive resolutions. While the traditional block-based approach can become unstable at coarse resolutions due to limited sampling, we introduce a sliding-window coarse-graining scheme that provides smoother estimates and improved robustness at large scales. Using this refined method, we analyze large structural MRI datasets spanning mid- to late adulthood and find that structural complexity decreases systematically with age, with the strongest effects emerging at coarser scales. These findings highlight structural complexity as a reliable signal processing tool for multiscale analysis of 3D imaging data, while also demonstrating its utility in predicting biological age from brain MRI.
EMoE: Eigenbasis-Guided Routing for Mixture-of-Experts
Jan 17, 2026The relentless scaling of deep learning models has led to unsustainable computational demands, positioning Mixture-of-Experts (MoE) architectures as a promising path towards greater efficiency. However, MoE models are plagued by two fundamental challenges: 1) a load imbalance problem known as the``rich get richer" phenomenon, where a few experts are over-utilized, and 2) an expert homogeneity problem, where experts learn redundant representations, negating their purpose. Current solutions typically employ an auxiliary load-balancing loss that, while mitigating imbalance, often exacerbates homogeneity by enforcing uniform routing at the expense of specialization. To resolve this, we introduce the Eigen-Mixture-of-Experts (EMoE), a novel architecture that leverages a routing mechanism based on a learned orthonormal eigenbasis. EMoE projects input tokens onto this shared eigenbasis and routes them based on their alignment with the principal components of the feature space. This principled, geometric partitioning of data intrinsically promotes both balanced expert utilization and the development of diverse, specialized experts, all without the need for a conflicting auxiliary loss function. Our code is publicly available at https://github.com/Belis0811/EMoE.
ERMoE: Eigen-Reparameterized Mixture-of-Experts for Stable Routing and Interpretable Specialization
Nov 14, 2025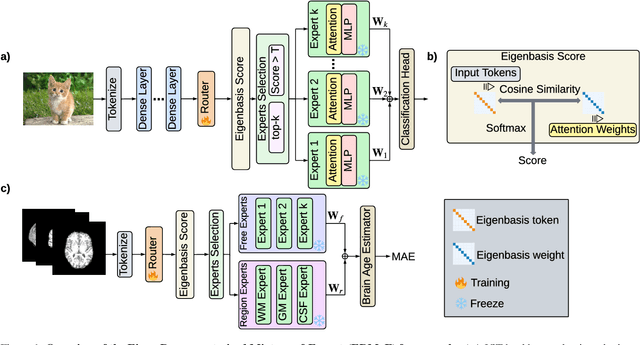
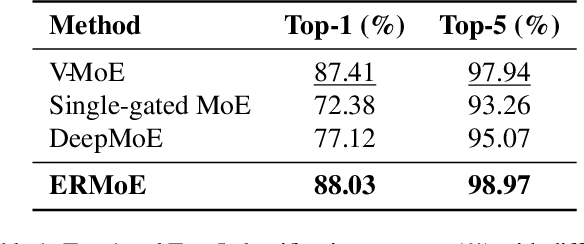
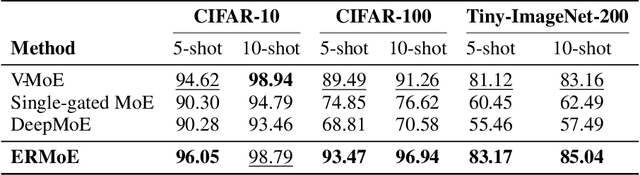
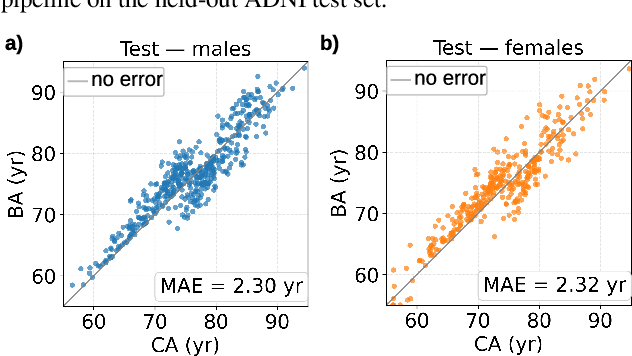
Mixture-of-Experts (MoE) architectures expand model capacity by sparsely activating experts but face two core challenges: misalignment between router logits and each expert's internal structure leads to unstable routing and expert underutilization, and load imbalances create straggler bottlenecks. Standard solutions, such as auxiliary load-balancing losses, can reduce load disparities but often weaken expert specialization and hurt downstream performance. To address these issues, we propose ERMoE, a sparse MoE transformer that reparameterizes each expert in a learned orthonormal eigenbasis and replaces learned gating logits with an "Eigenbasis Score", defined as the cosine similarity between input features and an expert's basis. This content-aware routing ties token assignments directly to experts' representation spaces, stabilizing utilization and promoting interpretable specialization without sacrificing sparsity. Crucially, ERMoE removes the need for explicit balancing losses and avoids the interfering gradients they introduce. We show that ERMoE achieves state-of-the-art accuracy on ImageNet classification and cross-modal image-text retrieval benchmarks (e.g., COCO, Flickr30K), while naturally producing flatter expert load distributions. Moreover, a 3D MRI variant (ERMoE-ba) improves brain age prediction accuracy by more than 7\% and yields anatomically interpretable expert specializations. ERMoE thus introduces a new architectural principle for sparse expert models that directly addresses routing instabilities and enables improved performance with scalable, interpretable specialization.
VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation
Oct 31, 2025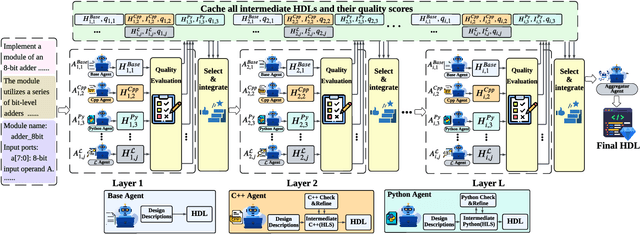
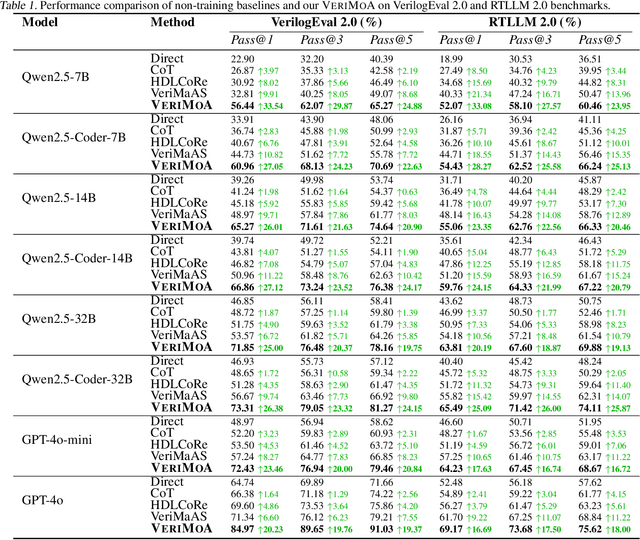
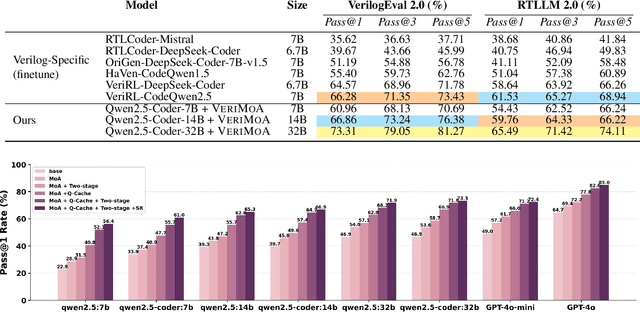
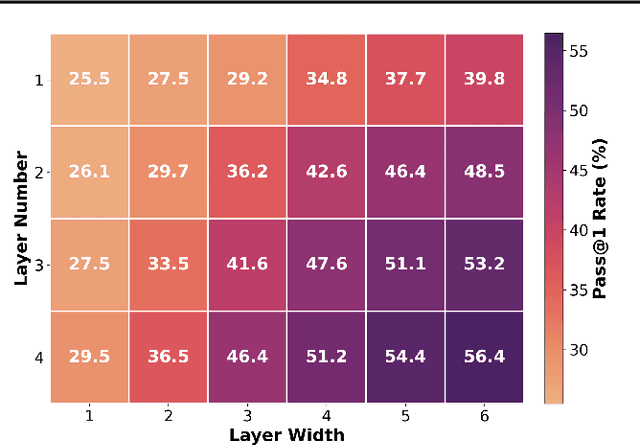
Automation of Register Transfer Level (RTL) design can help developers meet increasing computational demands. Large Language Models (LLMs) show promise for Hardware Description Language (HDL) generation, but face challenges due to limited parametric knowledge and domain-specific constraints. While prompt engineering and fine-tuning have limitations in knowledge coverage and training costs, multi-agent architectures offer a training-free paradigm to enhance reasoning through collaborative generation. However, current multi-agent approaches suffer from two critical deficiencies: susceptibility to noise propagation and constrained reasoning space exploration. We propose VeriMoA, a training-free mixture-of-agents (MoA) framework with two synergistic innovations. First, a quality-guided caching mechanism to maintain all intermediate HDL outputs and enables quality-based ranking and selection across the entire generation process, encouraging knowledge accumulation over layers of reasoning. Second, a multi-path generation strategy that leverages C++ and Python as intermediate representations, decomposing specification-to-HDL translation into two-stage processes that exploit LLM fluency in high-resource languages while promoting solution diversity. Comprehensive experiments on VerilogEval 2.0 and RTLLM 2.0 benchmarks demonstrate that VeriMoA achieves 15--30% improvements in Pass@1 across diverse LLM backbones, especially enabling smaller models to match larger models and fine-tuned alternatives without requiring costly training.
MaskAttn-SDXL: Controllable Region-Level Text-To-Image Generation
Sep 18, 2025Text-to-image diffusion models achieve impressive realism but often suffer from compositional failures on prompts with multiple objects, attributes, and spatial relations, resulting in cross-token interference where entities entangle, attributes mix across objects, and spatial cues are violated. To address these failures, we propose MaskAttn-SDXL,a region-level gating mechanism applied to the cross-attention logits of Stable Diffusion XL(SDXL)'s UNet. MaskAttn-SDXL learns a binary mask per layer, injecting it into each cross-attention logit map before softmax to sparsify token-to-latent interactions so that only semantically relevant connections remain active. The method requires no positional encodings, auxiliary tokens, or external region masks, and preserves the original inference path with negligible overhead. In practice, our model improves spatial compliance and attribute binding in multi-object prompts while preserving overall image quality and diversity. These findings demonstrate that logit-level maksed cross-attention is an data-efficient primitve for enforcing compositional control, and our method thus serves as a practical extension for spatial control in text-to-image generation.
HDLCoRe: A Training-Free Framework for Mitigating Hallucinations in LLM-Generated HDL
Mar 18, 2025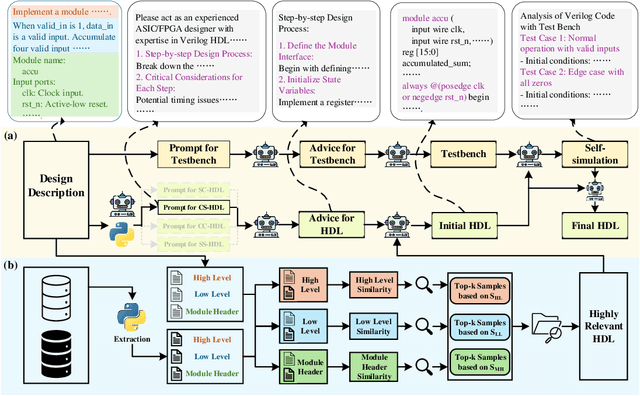



Recent advances in large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, when applied to hardware description languages (HDL), these models exhibit significant limitations due to data scarcity, resulting in hallucinations and incorrect code generation. To address these challenges, we propose HDLCoRe, a training-free framework that enhances LLMs' HDL generation capabilities through prompt engineering techniques and retrieval-augmented generation (RAG). Our approach consists of two main components: (1) an HDL-aware Chain-of-Thought (CoT) prompting technique with self-verification that classifies tasks by complexity and type, incorporates domain-specific knowledge, and guides LLMs through step-by-step self-simulation for error correction; and (2) a two-stage heterogeneous RAG system that addresses formatting inconsistencies through key component extraction and efficiently retrieves relevant HDL examples through sequential filtering and re-ranking. HDLCoRe eliminates the need for model fine-tuning while substantially improving LLMs' HDL generation capabilities. Experimental results demonstrate that our framework achieves superior performance on the RTLLM2.0 benchmark, significantly reducing hallucinations and improving both syntactic and functional correctness.
Unlocking Deep Learning: A BP-Free Approach for Parallel Block-Wise Training of Neural Networks
Dec 20, 2023



Backpropagation (BP) has been a successful optimization technique for deep learning models. However, its limitations, such as backward- and update-locking, and its biological implausibility, hinder the concurrent updating of layers and do not mimic the local learning processes observed in the human brain. To address these issues, recent research has suggested using local error signals to asynchronously train network blocks. However, this approach often involves extensive trial-and-error iterations to determine the best configuration for local training. This includes decisions on how to decouple network blocks and which auxiliary networks to use for each block. In our work, we introduce a novel BP-free approach: a block-wise BP-free (BWBPF) neural network that leverages local error signals to optimize distinct sub-neural networks separately, where the global loss is only responsible for updating the output layer. The local error signals used in the BP-free model can be computed in parallel, enabling a potential speed-up in the weight update process through parallel implementation. Our experimental results consistently show that this approach can identify transferable decoupled architectures for VGG and ResNet variations, outperforming models trained with end-to-end backpropagation and other state-of-the-art block-wise learning techniques on datasets such as CIFAR-10 and Tiny-ImageNet. The code is released at https://github.com/Belis0811/BWBPF.