 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMoE: Eigenbasis-Guided Routing for Mixture-of-Experts
Jan 17, 2026The relentless scaling of deep learning models has led to unsustainable computational demands, positioning Mixture-of-Experts (MoE) architectures as a promising path towards greater efficiency. However, MoE models are plagued by two fundamental challenges: 1) a load imbalance problem known as the``rich get richer" phenomenon, where a few experts are over-utilized, and 2) an expert homogeneity problem, where experts learn redundant representations, negating their purpose. Current solutions typically employ an auxiliary load-balancing loss that, while mitigating imbalance, often exacerbates homogeneity by enforcing uniform routing at the expense of specialization. To resolve this, we introduce the Eigen-Mixture-of-Experts (EMoE), a novel architecture that leverages a routing mechanism based on a learned orthonormal eigenbasis. EMoE projects input tokens onto this shared eigenbasis and routes them based on their alignment with the principal components of the feature space. This principled, geometric partitioning of data intrinsically promotes both balanced expert utilization and the development of diverse, specialized experts, all without the need for a conflicting auxiliary loss function. Our code is publicly available at https://github.com/Belis0811/EMoE.
ERMoE: Eigen-Reparameterized Mixture-of-Experts for Stable Routing and Interpretable Specialization
Nov 14, 2025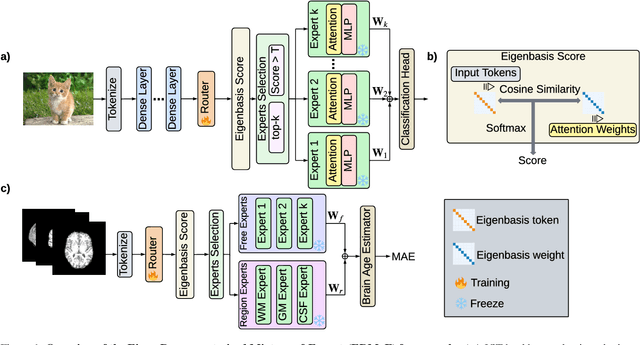
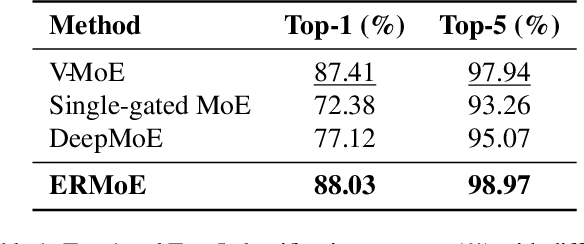
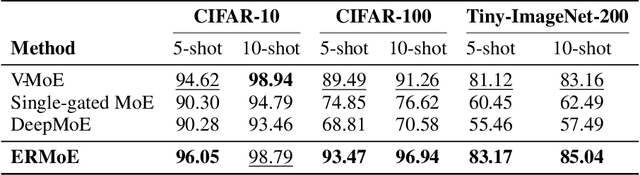
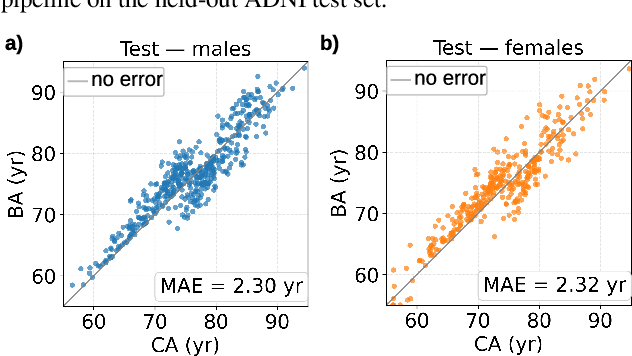
Mixture-of-Experts (MoE) architectures expand model capacity by sparsely activating experts but face two core challenges: misalignment between router logits and each expert's internal structure leads to unstable routing and expert underutilization, and load imbalances create straggler bottlenecks. Standard solutions, such as auxiliary load-balancing losses, can reduce load disparities but often weaken expert specialization and hurt downstream performance. To address these issues, we propose ERMoE, a sparse MoE transformer that reparameterizes each expert in a learned orthonormal eigenbasis and replaces learned gating logits with an "Eigenbasis Score", defined as the cosine similarity between input features and an expert's basis. This content-aware routing ties token assignments directly to experts' representation spaces, stabilizing utilization and promoting interpretable specialization without sacrificing sparsity. Crucially, ERMoE removes the need for explicit balancing losses and avoids the interfering gradients they introduce. We show that ERMoE achieves state-of-the-art accuracy on ImageNet classification and cross-modal image-text retrieval benchmarks (e.g., COCO, Flickr30K), while naturally producing flatter expert load distributions. Moreover, a 3D MRI variant (ERMoE-ba) improves brain age prediction accuracy by more than 7\% and yields anatomically interpretable expert specializations. ERMoE thus introduces a new architectural principle for sparse expert models that directly addresses routing instabilities and enables improved performance with scalable, interpretable specialization.
Exploring Fourier Prior and Event Collaboration for Low-Light Image Enhancement
Aug 01, 2025The event camera, benefiting from its high dynamic range and low latency, provides performance gain for low-light image enhancement. Unlike frame-based cameras, it records intensity changes with extremely high temporal resolution, capturing sufficient structure information. Currently, existing event-based methods feed a frame and events directly into a single model without fully exploiting modality-specific advantages, which limits their performance. Therefore, by analyzing the role of each sensing modality, the enhancement pipeline is decoupled into two stages: visibility restoration and structure refinement. In the first stage, we design a visibility restoration network with amplitude-phase entanglement by rethinking the relationship between amplitude and phase components in Fourier space. In the second stage, a fusion strategy with dynamic alignment is proposed to mitigate the spatial mismatch caused by the temporal resolution discrepancy between two sensing modalities, aiming to refine the structure information of the image enhanced by the visibility restoration network. In addition, we utilize spatial-frequency interpolation to simulate negative samples with diverse illumination, noise and artifact degradations, thereby developing a contrastive loss that encourages the model to learn discriminative representations. Experiments demonstrate that the proposed method outperforms state-of-the-art models.
SpikeSMOKE: Spiking Neural Networks for Monocular 3D Object Detection with Cross-Scale Gated Coding
Jun 09, 2025Low energy consumption for 3D object detection is an important research area because of the increasing energy consumption with their wide application in fields such as autonomous driving. The spiking neural networks (SNNs) with low-power consumption characteristics can provide a novel solution for this research. Therefore, we apply SNNs to monocular 3D object detection and propose the SpikeSMOKE architecture in this paper, which is a new attempt for low-power monocular 3D object detection. As we all know, discrete signals of SNNs will generate information loss and limit their feature expression ability compared with the artificial neural networks (ANNs).In order to address this issue, inspired by the filtering mechanism of biological neuronal synapses, we propose a cross-scale gated coding mechanism(CSGC), which can enhance feature representation by combining cross-scale fusion of attentional methods and gated filtering mechanisms.In addition, to reduce the computation and increase the speed of training, we present a novel light-weight residual block that can maintain spiking computing paradigm and the highest possible detection performance. Compared to the baseline SpikeSMOKE under the 3D Object Detection, the proposed SpikeSMOKE with CSGC can achieve 11.78 (+2.82, Easy), 10.69 (+3.2, Moderate), and 10.48 (+3.17, Hard) on the KITTI autonomous driving dataset by AP|R11 at 0.7 IoU threshold, respectively. It is important to note that the results of SpikeSMOKE can significantly reduce energy consumption compared to the results on SMOKE. For example,the energy consumption can be reduced by 72.2% on the hard category, while the detection performance is reduced by only 4%. SpikeSMOKE-L (lightweight) can further reduce the amount of parameters by 3 times and computation by 10 times compared to SMOKE.
HDLCoRe: A Training-Free Framework for Mitigating Hallucinations in LLM-Generated HDL
Mar 18, 2025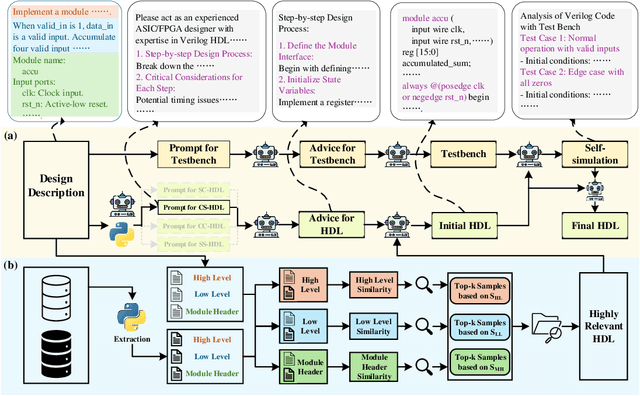



Recent advances in large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, when applied to hardware description languages (HDL), these models exhibit significant limitations due to data scarcity, resulting in hallucinations and incorrect code generation. To address these challenges, we propose HDLCoRe, a training-free framework that enhances LLMs' HDL generation capabilities through prompt engineering techniques and retrieval-augmented generation (RAG). Our approach consists of two main components: (1) an HDL-aware Chain-of-Thought (CoT) prompting technique with self-verification that classifies tasks by complexity and type, incorporates domain-specific knowledge, and guides LLMs through step-by-step self-simulation for error correction; and (2) a two-stage heterogeneous RAG system that addresses formatting inconsistencies through key component extraction and efficiently retrieves relevant HDL examples through sequential filtering and re-ranking. HDLCoRe eliminates the need for model fine-tuning while substantially improving LLMs' HDL generation capabilities. Experimental results demonstrate that our framework achieves superior performance on the RTLLM2.0 benchmark, significantly reducing hallucinations and improving both syntactic and functional correctness.
Temporal Information Reconstruction and Non-Aligned Residual in Spiking Neural Networks for Speech Classification
Dec 31, 2024
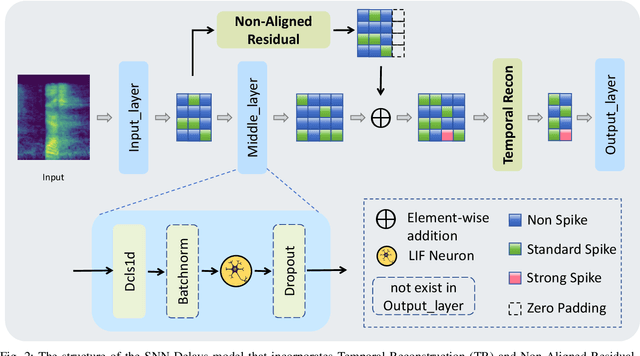
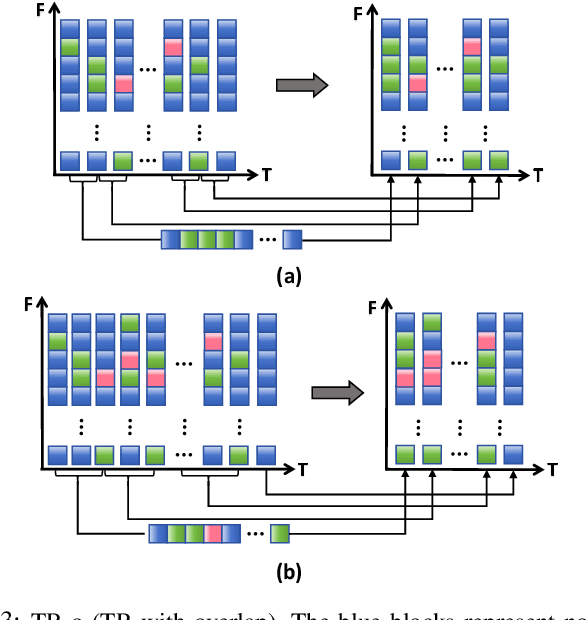
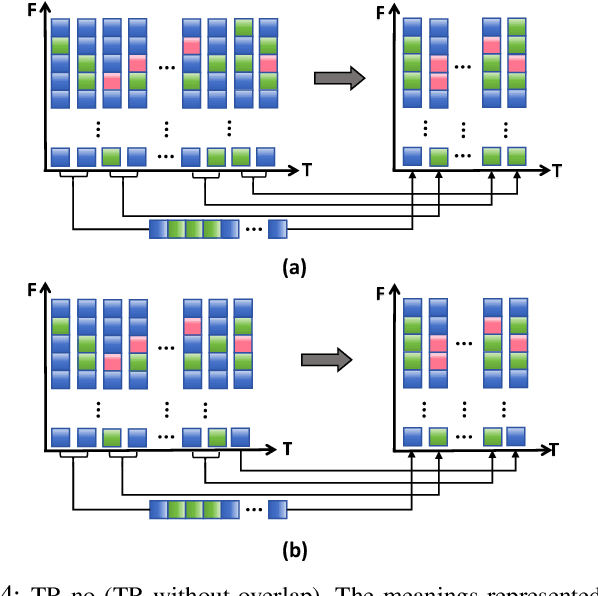
Recently, it can be noticed that most models based on spiking neural networks (SNNs) only use a same level temporal resolution to deal with speech classification problems, which makes these models cannot learn the information of input data at different temporal scales. Additionally, owing to the different time lengths of the data before and after the sub-modules of many models, the effective residual connections cannot be applied to optimize the training processes of these models.To solve these problems, on the one hand, we reconstruct the temporal dimension of the audio spectrum to propose a novel method named as Temporal Reconstruction (TR) by referring the hierarchical processing process of the human brain for understanding speech. Then, the reconstructed SNN model with TR can learn the information of input data at different temporal scales and model more comprehensive semantic information from audio data because it enables the networks to learn the information of input data at different temporal resolutions. On the other hand, we propose the Non-Aligned Residual (NAR) method by analyzing the audio data, which allows the residual connection can be used in two audio data with different time lengths. We have conducted plentiful experiments on the Spiking Speech Commands (SSC), the Spiking Heidelberg Digits (SHD), and the Google Speech Commands v0.02 (GSC) datasets. According to the experiment results, we have achieved the state-of-the-art (SOTA) result 81.02\% on SSC for the test classification accuracy of all SNN models, and we have obtained the SOTA result 96.04\% on SHD for the classification accuracy of all models.
NeuroMoCo: A Neuromorphic Momentum Contrast Learning Method for Spiking Neural Networks
Jun 10, 2024



Recently, brain-inspired spiking neural networks (SNNs) have attracted great research attention owing to their inherent bio-interpretability, event-triggered properties and powerful perception of spatiotemporal information, which is beneficial to handling event-based neuromorphic datasets. In contrast to conventional static image datasets, event-based neuromorphic datasets present heightened complexity in feature extraction due to their distinctive time series and sparsity characteristics, which influences their classification accuracy. To overcome this challenge, a novel approach termed Neuromorphic Momentum Contrast Learning (NeuroMoCo) for SNNs is introduced in this paper by extending the benefits of self-supervised pre-training to SNNs to effectively stimulate their potential. This is the first time that self-supervised learning (SSL) based on momentum contrastive learning is realized in SNNs. In addition, we devise a novel loss function named MixInfoNCE tailored to their temporal characteristics to further increase the classification accuracy of neuromorphic datasets, which is verified through rigorous ablation experiments. Finally, experiments on DVS-CIFAR10, DVS128Gesture and N-Caltech101 have shown that NeuroMoCo of this paper establishes new state-of-the-art (SOTA) benchmarks: 83.6% (Spikformer-2-256), 98.62% (Spikformer-2-256), and 84.4% (SEW-ResNet-18), respectively.
A structure-aware framework for learning device placements on computation graphs
May 23, 2024



Existing approaches for device placement ignore the topological features of computation graphs and rely mostly on heuristic methods for graph partitioning. At the same time, they either follow a grouper-placer or an encoder-placer architecture, which requires understanding the interaction structure between code operations. To bridge the gap between encoder-placer and grouper-placer techniques, we propose a novel framework for the task of device placement, relying on smaller computation graphs extracted from the OpenVINO toolkit using reinforcement learning. The framework consists of five steps, including graph coarsening, node representation learning and policy optimization. It facilitates end-to-end training and takes into consideration the directed and acyclic nature of the computation graphs. We also propose a model variant, inspired by graph parsing networks and complex network analysis, enabling graph representation learning and personalized graph partitioning jointly, using an unspecified number of groups. To train the entire framework, we utilize reinforcement learning techniques by employing the execution time of the suggested device placements to formulate the reward. We demonstrate the flexibility and effectiveness of our approach through multiple experiments with three benchmark models, namely Inception-V3, ResNet, and BERT. The robustness of the proposed framework is also highlighted through an ablation study. The suggested placements improve the inference speed for the benchmark models by up to $58.2\%$ over CPU execution and by up to $60.24\%$ compared to other commonly used baselines.
Leveraging Reinforcement Learning and Large Language Models for Code Optimization
Dec 09, 2023



Code optimization is a daunting task that requires a significant level of expertise from experienced programmers. This level of expertise is not sufficient when compared to the rapid development of new hardware architectures. Towards advancing the whole code optimization process, recent approaches rely on machine learning and artificial intelligence techniques. This paper introduces a new framework to decrease the complexity of code optimization. The proposed framework builds on large language models (LLMs) and reinforcement learning (RL) and enables LLMs to receive feedback from their environment (i.e., unit tests) during the fine-tuning process. We compare our framework with existing state-of-the-art models and show that it is more efficient with respect to speed and computational usage, as a result of the decrement in training steps and its applicability to models with fewer parameters. Additionally, our framework reduces the possibility of logical and syntactical errors. Toward evaluating our approach, we run several experiments on the PIE dataset using a CodeT5 language model and RRHF, a new reinforcement learning algorithm. We adopt a variety of evaluation metrics with regards to optimization quality, and speedup. The evaluation results demonstrate that the proposed framework has similar results in comparison with existing models using shorter training times and smaller pre-trained models. In particular, we accomplish an increase of 5.6% and 2.2 over the baseline models concerning the %OP T and SP metrics.
Network Pruning via Feature Shift Minimization
Jul 06, 2022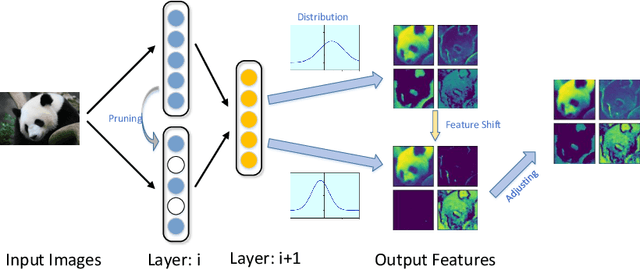
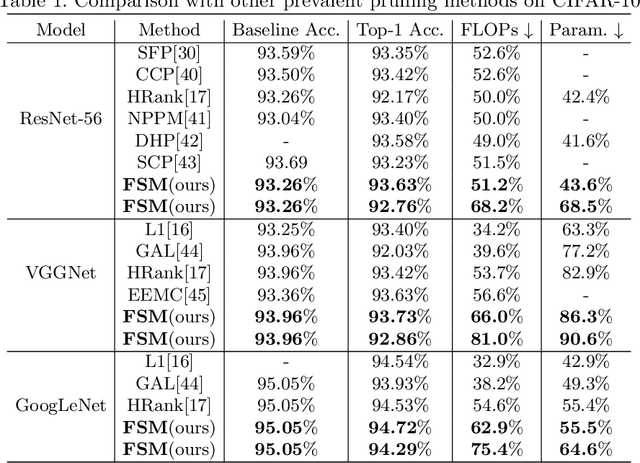
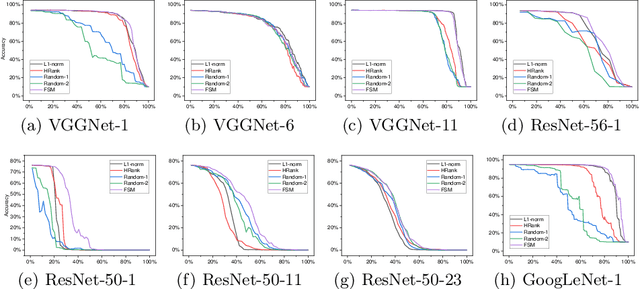
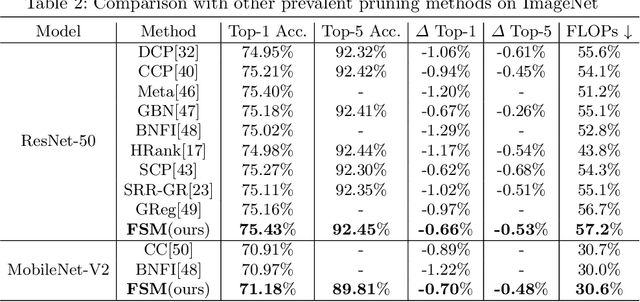
Channel pruning is widely used to reduce the complexity of deep network models. Recent pruning methods usually identify which parts of the network to discard by proposing a channel importance criterion. However, recent studies have shown that these criteria do not work well in all conditions. In this paper, we propose a novel Feature Shift Minimization (FSM) method to compress CNN models, which evaluates the feature shift by converging the information of both features and filters. Specifically, we first investigate the compression efficiency with some prevalent methods in different layer-depths and then propose the feature shift concept. Then, we introduce an approximation method to estimate the magnitude of the feature shift, since it is difficult to compute it directly. Besides, we present a distribution-optimization algorithm to compensate for the accuracy loss and improve the network compression efficiency. The proposed method yields state-of-the-art performance on various benchmark networks and datasets, verified by extensive experiments. The codes can be available at \url{https://github.com/lscgx/FSM}.