 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeSMOKE: Spiking Neural Networks for Monocular 3D Object Detection with Cross-Scale Gated Coding
Jun 09, 2025Low energy consumption for 3D object detection is an important research area because of the increasing energy consumption with their wide application in fields such as autonomous driving. The spiking neural networks (SNNs) with low-power consumption characteristics can provide a novel solution for this research. Therefore, we apply SNNs to monocular 3D object detection and propose the SpikeSMOKE architecture in this paper, which is a new attempt for low-power monocular 3D object detection. As we all know, discrete signals of SNNs will generate information loss and limit their feature expression ability compared with the artificial neural networks (ANNs).In order to address this issue, inspired by the filtering mechanism of biological neuronal synapses, we propose a cross-scale gated coding mechanism(CSGC), which can enhance feature representation by combining cross-scale fusion of attentional methods and gated filtering mechanisms.In addition, to reduce the computation and increase the speed of training, we present a novel light-weight residual block that can maintain spiking computing paradigm and the highest possible detection performance. Compared to the baseline SpikeSMOKE under the 3D Object Detection, the proposed SpikeSMOKE with CSGC can achieve 11.78 (+2.82, Easy), 10.69 (+3.2, Moderate), and 10.48 (+3.17, Hard) on the KITTI autonomous driving dataset by AP|R11 at 0.7 IoU threshold, respectively. It is important to note that the results of SpikeSMOKE can significantly reduce energy consumption compared to the results on SMOKE. For example,the energy consumption can be reduced by 72.2% on the hard category, while the detection performance is reduced by only 4%. SpikeSMOKE-L (lightweight) can further reduce the amount of parameters by 3 times and computation by 10 times compared to SMOKE.
Discrete Wavelet Transform-Based Capsule Network for Hyperspectral Image Classification
Jan 08, 2025



Hyperspectral image (HSI) classification is a crucial technique for remote sensing to build large-scale earth monitoring systems. HSI contains much more information than traditional visual images for identifying the categories of land covers. One recent feasible solution for HSI is to leverage CapsNets for capturing spectral-spatial information. However, these methods require high computational requirements due to the full connection architecture between stacked capsule layers. To solve this problem, a DWT-CapsNet is proposed to identify partial but important connections in CapsNet for a effective and efficient HSI classification. Specifically, we integrate a tailored attention mechanism into a Discrete Wavelet Transform (DWT)-based downsampling layer, alleviating the information loss problem of conventional downsampling operation in feature extractors. Moreover, we propose a novel multi-scale routing algorithm that prunes a large proportion of connections in CapsNet. A capsule pyramid fusion mechanism is designed to aggregate the spectral-spatial relationships in multiple levels of granularity, and then a self-attention mechanism is further conducted in a partially and locally connected architecture to emphasize the meaningful relationships. As shown in the experimental results, our method achieves state-of-the-art accuracy while keeping lower computational demand regarding running time, flops, and the number of parameters, rendering it an appealing choice for practical implementation in HSI classification.
Temporal Information Reconstruction and Non-Aligned Residual in Spiking Neural Networks for Speech Classification
Dec 31, 2024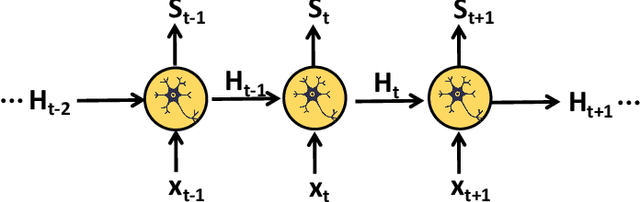
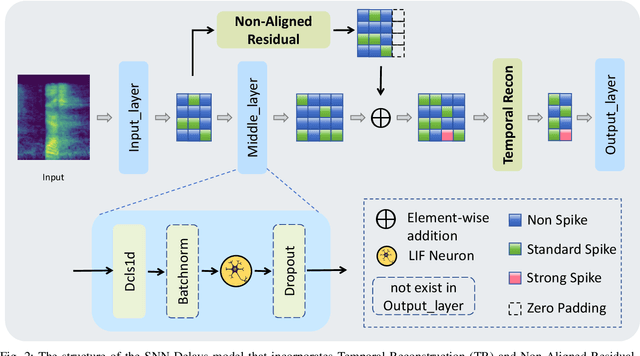
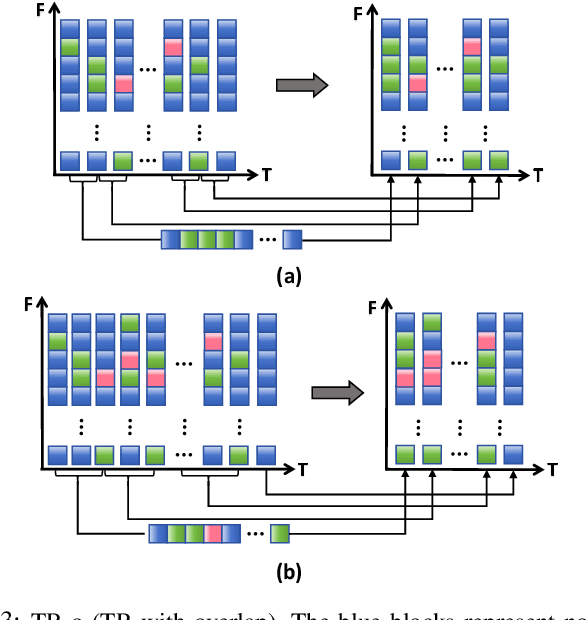
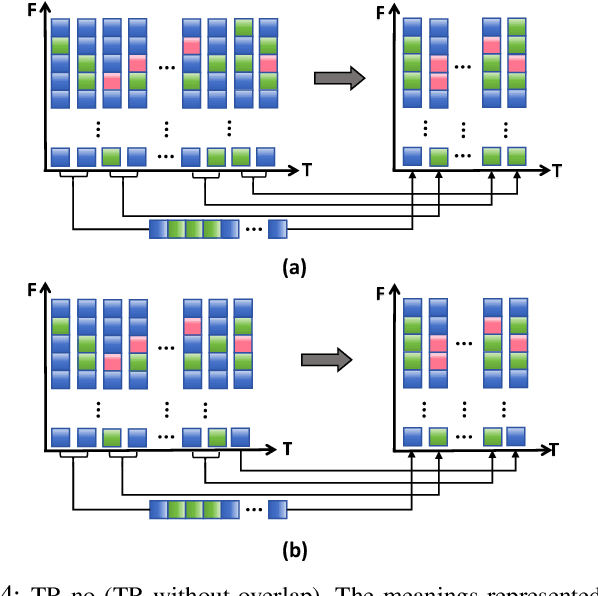
Recently, it can be noticed that most models based on spiking neural networks (SNNs) only use a same level temporal resolution to deal with speech classification problems, which makes these models cannot learn the information of input data at different temporal scales. Additionally, owing to the different time lengths of the data before and after the sub-modules of many models, the effective residual connections cannot be applied to optimize the training processes of these models.To solve these problems, on the one hand, we reconstruct the temporal dimension of the audio spectrum to propose a novel method named as Temporal Reconstruction (TR) by referring the hierarchical processing process of the human brain for understanding speech. Then, the reconstructed SNN model with TR can learn the information of input data at different temporal scales and model more comprehensive semantic information from audio data because it enables the networks to learn the information of input data at different temporal resolutions. On the other hand, we propose the Non-Aligned Residual (NAR) method by analyzing the audio data, which allows the residual connection can be used in two audio data with different time lengths. We have conducted plentiful experiments on the Spiking Speech Commands (SSC), the Spiking Heidelberg Digits (SHD), and the Google Speech Commands v0.02 (GSC) datasets. According to the experiment results, we have achieved the state-of-the-art (SOTA) result 81.02\% on SSC for the test classification accuracy of all SNN models, and we have obtained the SOTA result 96.04\% on SHD for the classification accuracy of all models.
NeuroMoCo: A Neuromorphic Momentum Contrast Learning Method for Spiking Neural Networks
Jun 10, 2024



Recently, brain-inspired spiking neural networks (SNNs) have attracted great research attention owing to their inherent bio-interpretability, event-triggered properties and powerful perception of spatiotemporal information, which is beneficial to handling event-based neuromorphic datasets. In contrast to conventional static image datasets, event-based neuromorphic datasets present heightened complexity in feature extraction due to their distinctive time series and sparsity characteristics, which influences their classification accuracy. To overcome this challenge, a novel approach termed Neuromorphic Momentum Contrast Learning (NeuroMoCo) for SNNs is introduced in this paper by extending the benefits of self-supervised pre-training to SNNs to effectively stimulate their potential. This is the first time that self-supervised learning (SSL) based on momentum contrastive learning is realized in SNNs. In addition, we devise a novel loss function named MixInfoNCE tailored to their temporal characteristics to further increase the classification accuracy of neuromorphic datasets, which is verified through rigorous ablation experiments. Finally, experiments on DVS-CIFAR10, DVS128Gesture and N-Caltech101 have shown that NeuroMoCo of this paper establishes new state-of-the-art (SOTA) benchmarks: 83.6% (Spikformer-2-256), 98.62% (Spikformer-2-256), and 84.4% (SEW-ResNet-18), respectively.