 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatient-Level Diagnosis of Acute Myeloid Leukemia via Deep Learning Analysis of Bone Marrow Smear
Jun 09, 2026Bone marrow smear review remains important for acute myeloid leukemia (AML) assessment, but manual single-cell interpretation is labor-intensive and patient-level diagnosis requires aggregation of many cellular observations. We present a cell-to-patient deep learning pipeline for AML-assisted diagnosis from bone marrow smear images. The study included 258 patients from six anonymized centers, including a main cohort of 169 patients from Centers 1-3 and an external validation cohort of 89 patients from Centers 4-6. A 16-category cell annotation vocabulary was used to describe the global cellular composition, including granulocytic, monocytic, erythroid, lymphoid, eosinophilic, and other cells. Rather than identifying strict AML blasts or leukemic blasts, the model targets an expert-defined composite category termed Composite Blast-like Cells (CBLC), comprising N, N1, M, M1, R, R1, J, and J1 according to the project-wide morphological standard. A fixed YOLO-based segmentation module detected cells, predicted contours were matched to expert polygon annotations by contour IoU, and standardized single-cell crops were generated. An EfficientNet-B0 classifier was trained through a two-stage GT-to-YOLO and YOLO-to-YOLO strategy with class-imbalance correction, center-border regularization, and morphology-assisted supervision. Cell-level predictions were aggregated into patient-level CBLC ratios for AML-oriented diagnostic support. The pipeline achieved stable internal validation and maintained external generalization, with ensemble weighted F1-scores of 0.9076, 0.8696, and 0.9124 on Centers 4, 5, and 6, respectively.
KAE: Kolmogorov-Arnold Auto-Encoder for Representation Learning
Dec 31, 2024



The Kolmogorov-Arnold Network (KAN) has recently gained attention as an alternative to traditional multi-layer perceptrons (MLPs), offering improved accuracy and interpretability by employing learnable activation functions on edges. In this paper, we introduce the Kolmogorov-Arnold Auto-Encoder (KAE), which integrates KAN with autoencoders (AEs) to enhance representation learning for retrieval, classification, and denoising tasks. Leveraging the flexible polynomial functions in KAN layers, KAE captures complex data patterns and non-linear relationships. Experiments on benchmark datasets demonstrate that KAE improves latent representation quality, reduces reconstruction errors, and achieves superior performance in downstream tasks such as retrieval, classification, and denoising, compared to standard autoencoders and other KAN variants. These results suggest KAE's potential as a useful tool for representation learning. Our code is available at \url{https://github.com/SciYu/KAE/}.
Hallo3: Highly Dynamic and Realistic Portrait Image Animation with Diffusion Transformer Networks
Dec 01, 2024Existing methodologies for animating portrait images face significant challenges, particularly in handling non-frontal perspectives, rendering dynamic objects around the portrait, and generating immersive, realistic backgrounds. In this paper, we introduce the first application of a pretrained transformer-based video generative model that demonstrates strong generalization capabilities and generates highly dynamic, realistic videos for portrait animation, effectively addressing these challenges. The adoption of a new video backbone model makes previous U-Net-based methods for identity maintenance, audio conditioning, and video extrapolation inapplicable. To address this limitation, we design an identity reference network consisting of a causal 3D VAE combined with a stacked series of transformer layers, ensuring consistent facial identity across video sequences. Additionally, we investigate various speech audio conditioning and motion frame mechanisms to enable the generation of continuous video driven by speech audio. Our method is validated through experiments on benchmark and newly proposed wild datasets, demonstrating substantial improvements over prior methods in generating realistic portraits characterized by diverse orientations within dynamic and immersive scenes. Further visualizations and the source code are available at: https://github.com/fudan-generative-vision/hallo3.
HA-FGOVD: Highlighting Fine-grained Attributes via Explicit Linear Composition for Open-Vocabulary Object Detection
Sep 24, 2024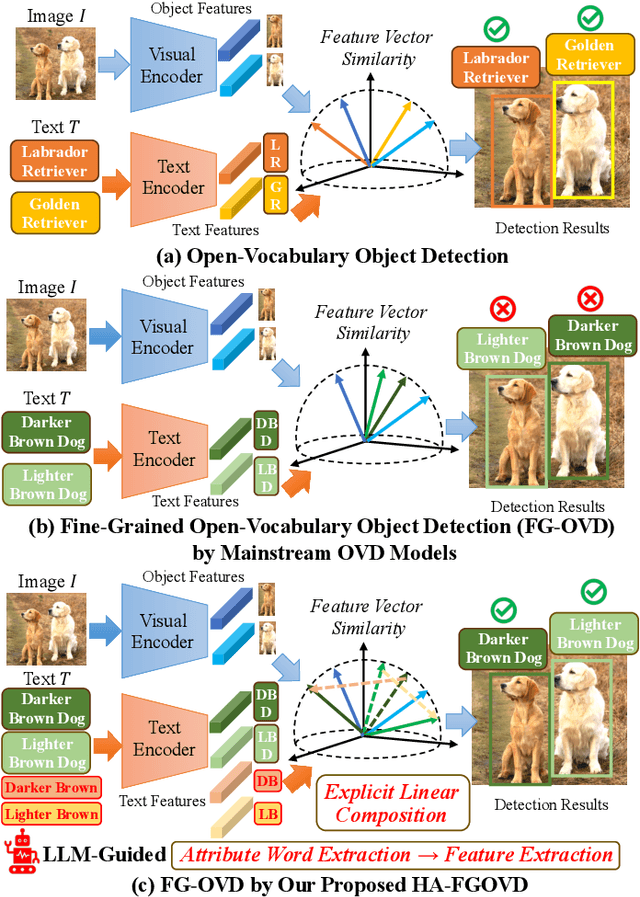
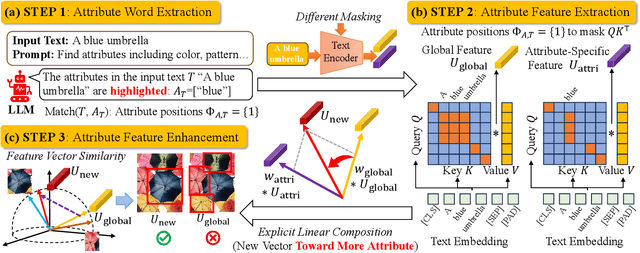

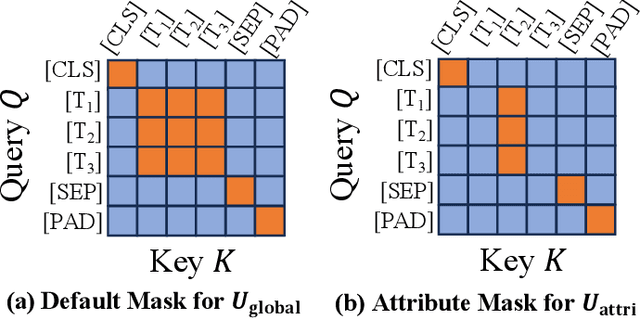
Open-vocabulary object detection (OVD) models are considered to be Large Multi-modal Models (LMM), due to their extensive training data and a large number of parameters. Mainstream OVD models prioritize object coarse-grained category rather than focus on their fine-grained attributes, e.g., colors or materials, thus failed to identify objects specified with certain attributes. However, OVD models are pretrained on large-scale image-text pairs with rich attribute words, whose latent feature space can represent the global text feature as a linear composition of fine-grained attribute tokens without highlighting them. Therefore, we propose in this paper a universal and explicit approach for frozen mainstream OVD models that boosts their attribute-level detection capabilities by highlighting fine-grained attributes in explicit linear space. Firstly, a LLM is leveraged to highlight attribute words within the input text as a zero-shot prompted task. Secondly, by strategically adjusting the token masks, the text encoders of OVD models extract both global text and attribute-specific features, which are then explicitly composited as two vectors in linear space to form the new attribute-highlighted feature for detection tasks, where corresponding scalars are hand-crafted or learned to reweight both two vectors. Notably, these scalars can be seamlessly transferred among different OVD models, which proves that such an explicit linear composition is universal. Empirical evaluation on the FG-OVD dataset demonstrates that our proposed method uniformly improves fine-grained attribute-level OVD of various mainstream models and achieves new state-of-the-art performance.
NeuroMoCo: A Neuromorphic Momentum Contrast Learning Method for Spiking Neural Networks
Jun 10, 2024



Recently, brain-inspired spiking neural networks (SNNs) have attracted great research attention owing to their inherent bio-interpretability, event-triggered properties and powerful perception of spatiotemporal information, which is beneficial to handling event-based neuromorphic datasets. In contrast to conventional static image datasets, event-based neuromorphic datasets present heightened complexity in feature extraction due to their distinctive time series and sparsity characteristics, which influences their classification accuracy. To overcome this challenge, a novel approach termed Neuromorphic Momentum Contrast Learning (NeuroMoCo) for SNNs is introduced in this paper by extending the benefits of self-supervised pre-training to SNNs to effectively stimulate their potential. This is the first time that self-supervised learning (SSL) based on momentum contrastive learning is realized in SNNs. In addition, we devise a novel loss function named MixInfoNCE tailored to their temporal characteristics to further increase the classification accuracy of neuromorphic datasets, which is verified through rigorous ablation experiments. Finally, experiments on DVS-CIFAR10, DVS128Gesture and N-Caltech101 have shown that NeuroMoCo of this paper establishes new state-of-the-art (SOTA) benchmarks: 83.6% (Spikformer-2-256), 98.62% (Spikformer-2-256), and 84.4% (SEW-ResNet-18), respectively.