 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashCap: Millisecond-Accurate Human Motion Capture via Flashing LEDs and Event-Based Vision
Mar 20, 2026Precise motion timing (PMT) is crucial for swift motion analysis. A millisecond difference may determine victory or defeat in sports competitions. Despite substantial progress in human pose estimation (HPE), PMT remains largely overlooked by the HPE community due to the limited availability of high-temporal-resolution labeled datasets. Today, PMT is achieved using high-speed RGB cameras in specialized scenarios such as the Olympic Games; however, their high costs, light sensitivity, bandwidth, and computational complexity limit their feasibility for daily use. We developed FlashCap, the first flashing LED-based MoCap system for PMT. With FlashCap, we collect a millisecond-resolution human motion dataset, FlashMotion, comprising the event, RGB, LiDAR, and IMU modalities, and demonstrate its high quality through rigorous validation. To evaluate the merits of FlashMotion, we perform two tasks: precise motion timing and high-temporal-resolution HPE. For these tasks, we propose ResPose, a simple yet effective baseline that learns residual poses based on events and RGBs. Experimental results show that ResPose reduces pose estimation errors by ~40% and achieves millisecond-level timing accuracy, enabling new research opportunities. The dataset and code will be shared with the community.
HA-FGOVD: Highlighting Fine-grained Attributes via Explicit Linear Composition for Open-Vocabulary Object Detection
Sep 24, 2024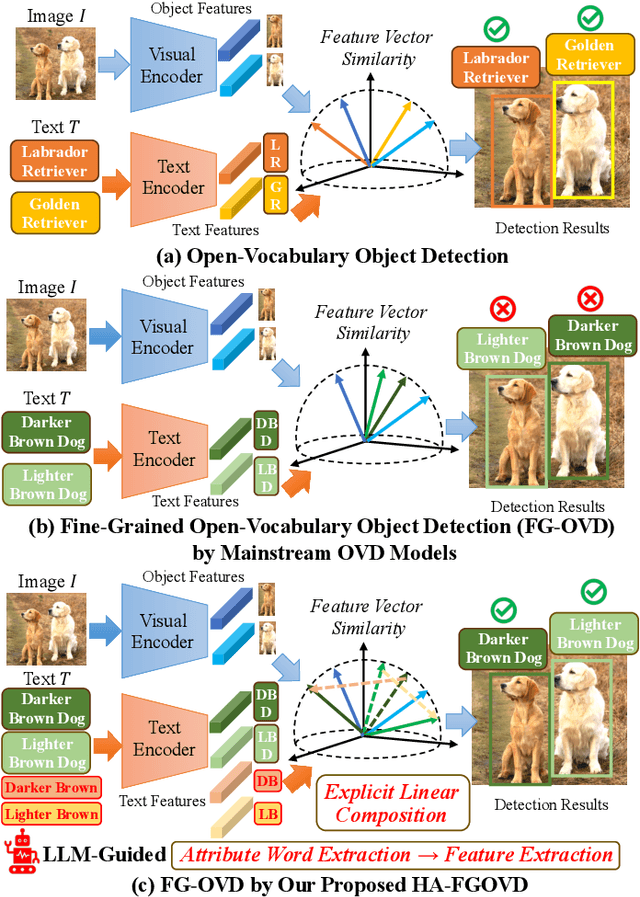
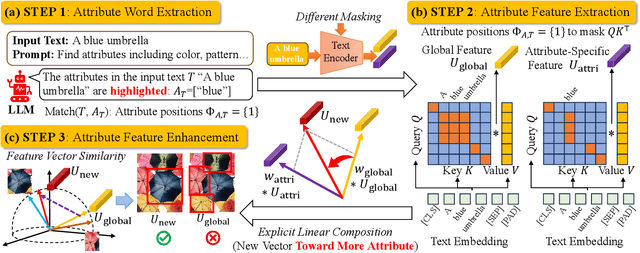

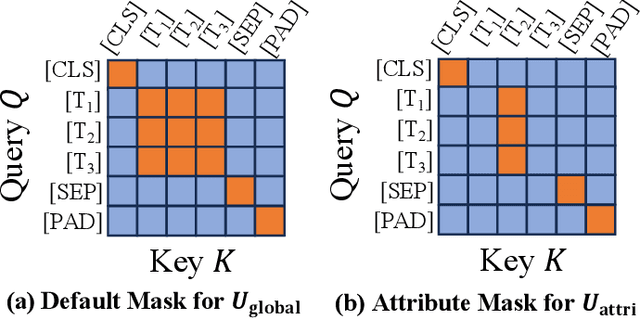
Open-vocabulary object detection (OVD) models are considered to be Large Multi-modal Models (LMM), due to their extensive training data and a large number of parameters. Mainstream OVD models prioritize object coarse-grained category rather than focus on their fine-grained attributes, e.g., colors or materials, thus failed to identify objects specified with certain attributes. However, OVD models are pretrained on large-scale image-text pairs with rich attribute words, whose latent feature space can represent the global text feature as a linear composition of fine-grained attribute tokens without highlighting them. Therefore, we propose in this paper a universal and explicit approach for frozen mainstream OVD models that boosts their attribute-level detection capabilities by highlighting fine-grained attributes in explicit linear space. Firstly, a LLM is leveraged to highlight attribute words within the input text as a zero-shot prompted task. Secondly, by strategically adjusting the token masks, the text encoders of OVD models extract both global text and attribute-specific features, which are then explicitly composited as two vectors in linear space to form the new attribute-highlighted feature for detection tasks, where corresponding scalars are hand-crafted or learned to reweight both two vectors. Notably, these scalars can be seamlessly transferred among different OVD models, which proves that such an explicit linear composition is universal. Empirical evaluation on the FG-OVD dataset demonstrates that our proposed method uniformly improves fine-grained attribute-level OVD of various mainstream models and achieves new state-of-the-art performance.
Unsupervised Multi-view Pedestrian Detection
May 21, 2023



With the prosperity of the video surveillance, multiple visual sensors have been applied for an accurate localization of pedestrians in a specific area, which facilitate various applications like intelligent safety or new retailing. However, previous methods rely on the supervision from the human annotated pedestrian positions in every video frame and camera view, which is a heavy burden in addition to the necessary camera calibration and synchronization. Therefore, we propose in this paper an Unsupervised Multi-view Pedestrian Detection approach (UMPD) to eliminate the need of annotations to learn a multi-view pedestrian detector. 1) Firstly, Semantic-aware Iterative Segmentation (SIS) is proposed to extract discriminative visual representations of the input images from different camera views via an unsupervised pretrained model, then convert them into 2D segments of pedestrians, based on our proposed iterative Principal Component Analysis and the zero-shot semantic classes from the vision-language pretrained models. 2) Secondly, we propose Vertical-aware Differential Rendering (VDR) to not only learn the densities and colors of 3D voxels by the masks of SIS, images and camera poses, but also constraint the voxels to be vertical towards the ground plane, following the physical characteristics of pedestrians. 3) Thirdly, the densities of 3D voxels learned by VDR are projected onto Bird-Eyes-View as the final detection results. Extensive experiments on popular multi-view pedestrian detection benchmarks, i.e., Wildtrack and MultiviewX, show that our proposed UMPD approach, as the first unsupervised method to our best knowledge, performs competitively with the previous state-of-the-art supervised techniques. Code will be available.
VLPD: Context-Aware Pedestrian Detection via Vision-Language Semantic Self-Supervision
Apr 06, 2023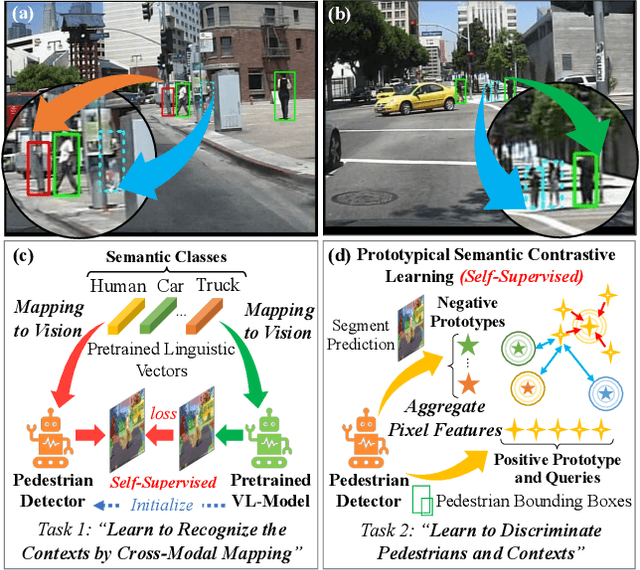

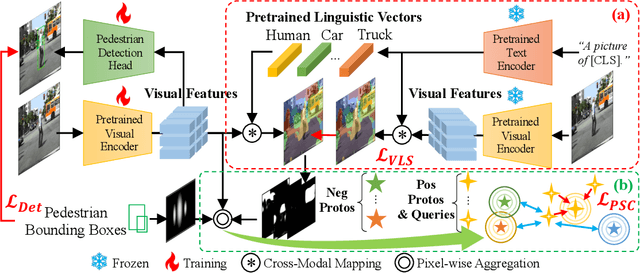

Detecting pedestrians accurately in urban scenes is significant for realistic applications like autonomous driving or video surveillance. However, confusing human-like objects often lead to wrong detections, and small scale or heavily occluded pedestrians are easily missed due to their unusual appearances. To address these challenges, only object regions are inadequate, thus how to fully utilize more explicit and semantic contexts becomes a key problem. Meanwhile, previous context-aware pedestrian detectors either only learn latent contexts with visual clues, or need laborious annotations to obtain explicit and semantic contexts. Therefore, we propose in this paper a novel approach via Vision-Language semantic self-supervision for context-aware Pedestrian Detection (VLPD) to model explicitly semantic contexts without any extra annotations. Firstly, we propose a self-supervised Vision-Language Semantic (VLS) segmentation method, which learns both fully-supervised pedestrian detection and contextual segmentation via self-generated explicit labels of semantic classes by vision-language models. Furthermore, a self-supervised Prototypical Semantic Contrastive (PSC) learning method is proposed to better discriminate pedestrians and other classes, based on more explicit and semantic contexts obtained from VLS. Extensive experiments on popular benchmarks show that our proposed VLPD achieves superior performances over the previous state-of-the-arts, particularly under challenging circumstances like small scale and heavy occlusion. Code is available at https://github.com/lmy98129/VLPD.
Boosting Multi-Modal E-commerce Attribute Value Extraction via Unified Learning Scheme and Dynamic Range Minimization
Jul 15, 2022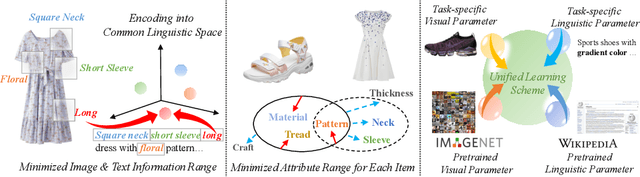
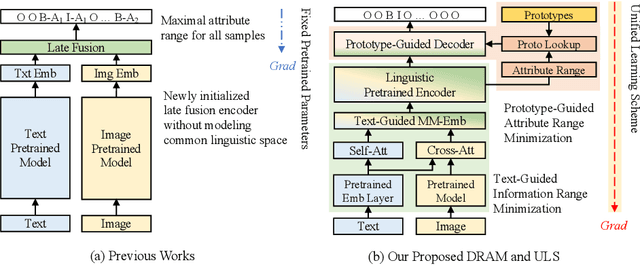
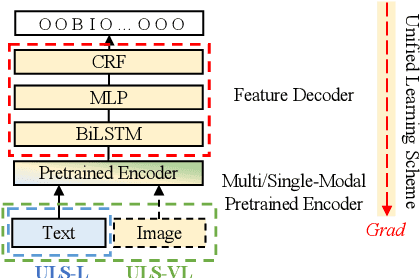

With the prosperity of e-commerce industry, various modalities, e.g., vision and language, are utilized to describe product items. It is an enormous challenge to understand such diversified data, especially via extracting the attribute-value pairs in text sequences with the aid of helpful image regions. Although a series of previous works have been dedicated to this task, there remain seldomly investigated obstacles that hinder further improvements: 1) Parameters from up-stream single-modal pretraining are inadequately applied, without proper jointly fine-tuning in a down-stream multi-modal task. 2) To select descriptive parts of images, a simple late fusion is widely applied, regardless of priori knowledge that language-related information should be encoded into a common linguistic embedding space by stronger encoders. 3) Due to diversity across products, their attribute sets tend to vary greatly, but current approaches predict with an unnecessary maximal range and lead to more potential false positives. To address these issues, we propose in this paper a novel approach to boost multi-modal e-commerce attribute value extraction via unified learning scheme and dynamic range minimization: 1) Firstly, a unified scheme is designed to jointly train a multi-modal task with pretrained single-modal parameters. 2) Secondly, a text-guided information range minimization method is proposed to adaptively encode descriptive parts of each modality into an identical space with a powerful pretrained linguistic model. 3) Moreover, a prototype-guided attribute range minimization method is proposed to first determine the proper attribute set of the current product, and then select prototypes to guide the prediction of the chosen attributes. Experiments on the popular multi-modal e-commerce benchmarks show that our approach achieves superior performance over the other state-of-the-art techniques.