 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHPO: Modulated Hazard-aware Policy Optimization for Stable Reinforcement Learning
Mar 14, 2026Regulating the importance ratio is critical for the training stability of Group Relative Policy Optimization (GRPO) based frameworks. However, prevailing ratio control methods, such as hard clipping, suffer from non-differentiable boundaries and vanishing gradient regions, failing to maintain gradient fidelity. Furthermore, these methods lack a hazard-aware mechanism to adaptively suppress extreme deviations, leaving the optimization process vulnerable to abrupt policy shifts. To address these challenges, we propose Modulated Hazard-aware Policy Optimization (MHPO), a novel framework designed for robust and stable reinforcement learning. The proposed MHPO introduces a Log-Fidelity Modulator (LFM) to map unbounded importance ratios into a bounded, differentiable domain. This mechanism effectively prevents high-variance outlier tokens from destabilizing the loss landscape while ensuring global gradient stability. Complementarily, a Decoupled Hazard Penalty (DHP) integrates cumulative hazard functions from survival analysis to independently regulate positive and negative policy shifts. By shaping the optimization landscape with hazard-aware penalties, the proposed MHPO achieves fine-grained regulation of asymmetric policy shifts simultaneously mitigating mode collapse from over-expansion and preventing policy erosion from catastrophic contraction within a stabilized trust region. Extensive evaluations on diverse reasoning benchmarks across both text-based and vision-language tasks demonstrate that MHPO consistently outperforms existing methods, achieving superior performance while significantly enhancing training stability.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
Beyond Intermediate States: Explaining Visual Redundancy through Language
Mar 26, 2025Multi-modal Large Langue Models (MLLMs) often process thousands of visual tokens, which consume a significant portion of the context window and impose a substantial computational burden. Prior work has empirically explored visual token pruning methods based on MLLMs' intermediate states (e.g., attention scores). However, they have limitations in precisely defining visual redundancy due to their inability to capture the influence of visual tokens on MLLMs' visual understanding (i.e., the predicted probabilities for textual token candidates). To address this issue, we manipulate the visual input and investigate variations in the textual output from both token-centric and context-centric perspectives, achieving intuitive and comprehensive analysis. Experimental results reveal that visual tokens with low ViT-[cls] association and low text-to-image attention scores can contain recognizable information and significantly contribute to images' overall information. To develop a more reliable method for identifying and pruning redundant visual tokens, we integrate these two perspectives and introduce a context-independent condition to identify redundant prototypes from training images, which probes the redundancy of each visual token during inference. Extensive experiments on single-image, multi-image and video comprehension tasks demonstrate the effectiveness of our method, notably achieving 90% to 110% of the performance while pruning 80% to 90% of visual tokens.
Video-Language Alignment Pre-training via Spatio-Temporal Graph Transformer
Jul 16, 2024



Video-language alignment is a crucial multi-modal task that benefits various downstream applications, e.g., video-text retrieval and video question answering. Existing methods either utilize multi-modal information in video-text pairs or apply global and local alignment techniques to promote alignment precision. However, these methods often fail to fully explore the spatio-temporal relationships among vision tokens within video and across different video-text pairs. In this paper, we propose a novel Spatio-Temporal Graph Transformer module to uniformly learn spatial and temporal contexts for video-language alignment pre-training (dubbed STGT). Specifically, our STGT combines spatio-temporal graph structure information with attention in transformer block, effectively utilizing the spatio-temporal contexts. In this way, we can model the relationships between vision tokens, promoting video-text alignment precision for benefiting downstream tasks. In addition, we propose a self-similarity alignment loss to explore the inherent self-similarity in the video and text. With the initial optimization achieved by contrastive learning, it can further promote the alignment accuracy between video and text. Experimental results on challenging downstream tasks, including video-text retrieval and video question answering, verify the superior performance of our method.
Adaptive Perception Transformer for Temporal Action Localization
Aug 25, 2022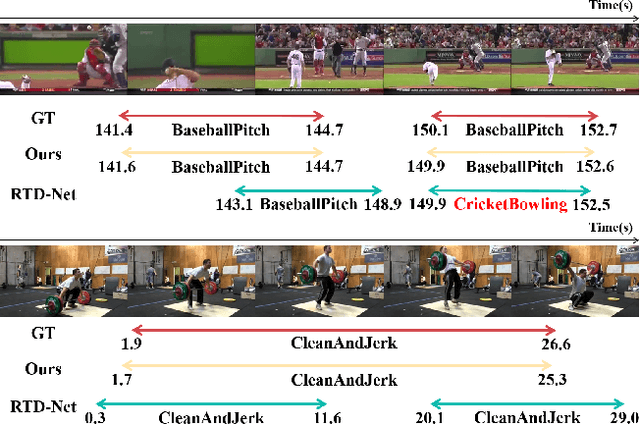
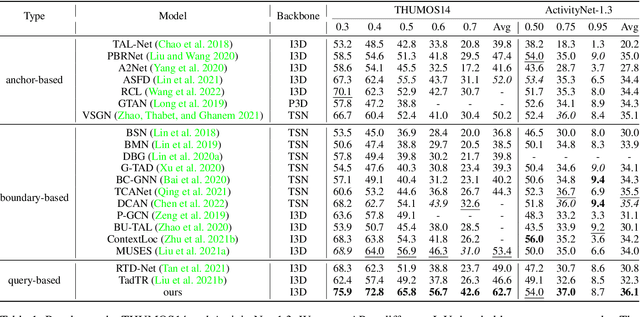
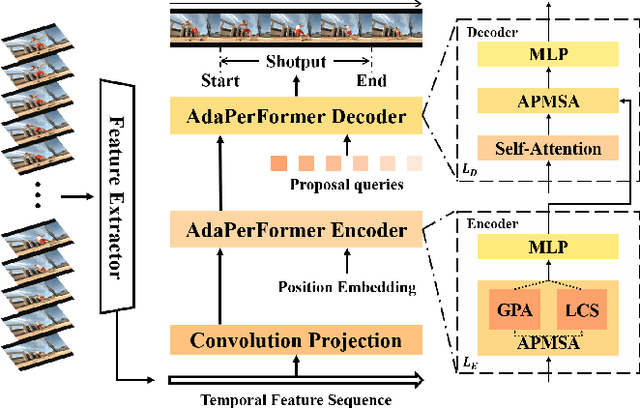
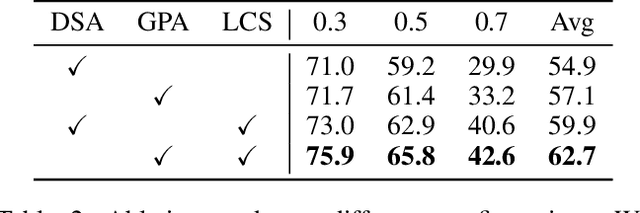
Temporal action localization aims to predict the boundary and category of each action instance in untrimmed long videos. Most of previous methods based on anchors or proposals neglect the global-local context interaction in entire video sequences. Besides, their multi-stage designs cannot generate action boundaries and categories straightforwardly. To address the above issues, this paper proposes a novel end-to-end model, called adaptive perception transformer (AdaPerFormer for short). Specifically, AdaPerFormer explores a dual-branch multi-head self-attention mechanism. One branch takes care of the global perception attention, which can model entire video sequences and aggregate global relevant contexts. While the other branch concentrates on the local convolutional shift to aggregate intra-frame and inter-frame information through our bidirectional shift operation. The end-to-end nature produces the boundaries and categories of video actions without extra steps. Extensive experiments together with ablation studies are provided to reveal the effectiveness of our design. Our method achieves a state-of-the-art accuracy on the THUMOS14 dataset (65.8\% in terms of mAP@0.5, 42.6\% mAP@0.7, and 62.7\% mAP@Avg), and obtains competitive performance on the ActivityNet-1.3 dataset with an average mAP of 36.1\%. The code and models are available at https://github.com/SouperO/AdaPerFormer.
Boosting Multi-Modal E-commerce Attribute Value Extraction via Unified Learning Scheme and Dynamic Range Minimization
Jul 15, 2022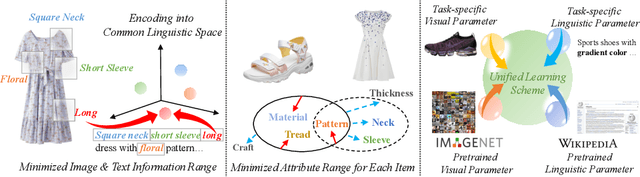
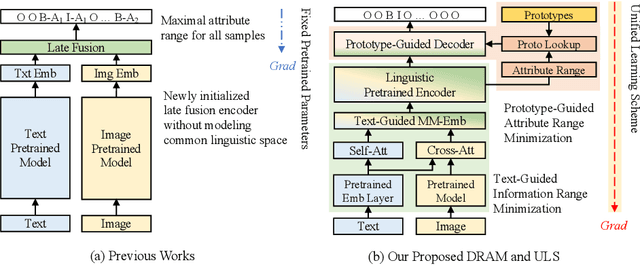
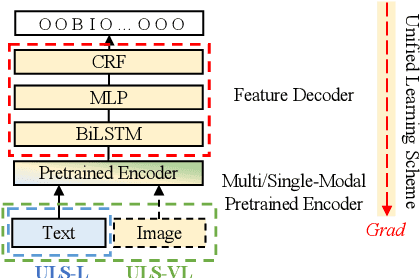

With the prosperity of e-commerce industry, various modalities, e.g., vision and language, are utilized to describe product items. It is an enormous challenge to understand such diversified data, especially via extracting the attribute-value pairs in text sequences with the aid of helpful image regions. Although a series of previous works have been dedicated to this task, there remain seldomly investigated obstacles that hinder further improvements: 1) Parameters from up-stream single-modal pretraining are inadequately applied, without proper jointly fine-tuning in a down-stream multi-modal task. 2) To select descriptive parts of images, a simple late fusion is widely applied, regardless of priori knowledge that language-related information should be encoded into a common linguistic embedding space by stronger encoders. 3) Due to diversity across products, their attribute sets tend to vary greatly, but current approaches predict with an unnecessary maximal range and lead to more potential false positives. To address these issues, we propose in this paper a novel approach to boost multi-modal e-commerce attribute value extraction via unified learning scheme and dynamic range minimization: 1) Firstly, a unified scheme is designed to jointly train a multi-modal task with pretrained single-modal parameters. 2) Secondly, a text-guided information range minimization method is proposed to adaptively encode descriptive parts of each modality into an identical space with a powerful pretrained linguistic model. 3) Moreover, a prototype-guided attribute range minimization method is proposed to first determine the proper attribute set of the current product, and then select prototypes to guide the prediction of the chosen attributes. Experiments on the popular multi-modal e-commerce benchmarks show that our approach achieves superior performance over the other state-of-the-art techniques.