 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Perception Transformer for Temporal Action Localization
Aug 25, 2022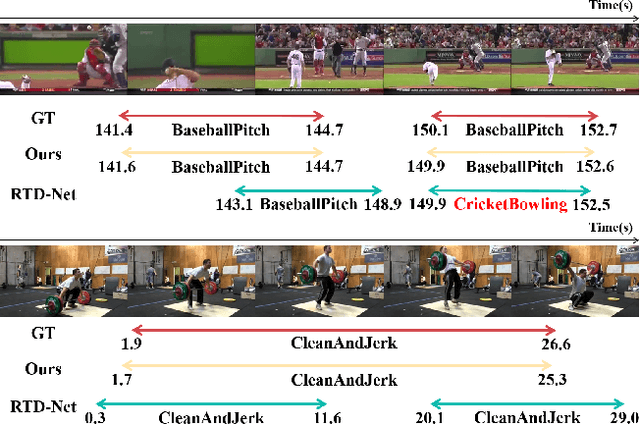
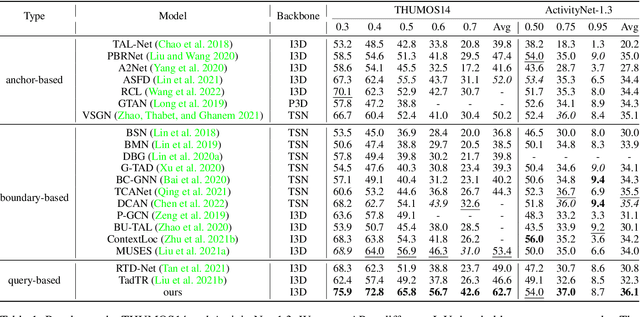
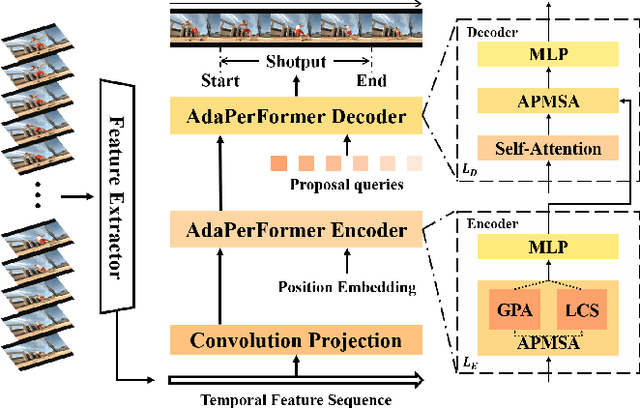
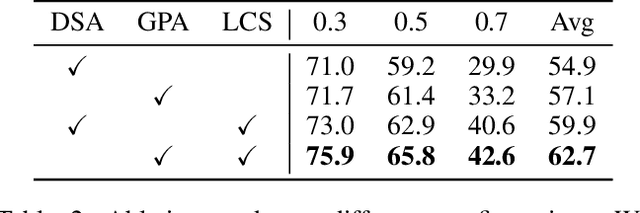
Temporal action localization aims to predict the boundary and category of each action instance in untrimmed long videos. Most of previous methods based on anchors or proposals neglect the global-local context interaction in entire video sequences. Besides, their multi-stage designs cannot generate action boundaries and categories straightforwardly. To address the above issues, this paper proposes a novel end-to-end model, called adaptive perception transformer (AdaPerFormer for short). Specifically, AdaPerFormer explores a dual-branch multi-head self-attention mechanism. One branch takes care of the global perception attention, which can model entire video sequences and aggregate global relevant contexts. While the other branch concentrates on the local convolutional shift to aggregate intra-frame and inter-frame information through our bidirectional shift operation. The end-to-end nature produces the boundaries and categories of video actions without extra steps. Extensive experiments together with ablation studies are provided to reveal the effectiveness of our design. Our method achieves a state-of-the-art accuracy on the THUMOS14 dataset (65.8\% in terms of mAP@0.5, 42.6\% mAP@0.7, and 62.7\% mAP@Avg), and obtains competitive performance on the ActivityNet-1.3 dataset with an average mAP of 36.1\%. The code and models are available at https://github.com/SouperO/AdaPerFormer.