 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the State of Open Science in Transportation Using Large Language Models
Jan 20, 2026Open science initiatives have strengthened scientific integrity and accelerated research progress across many fields, but the state of their practice within transportation research remains under-investigated. Key features of open science, defined here as data and code availability, are difficult to extract due to the inherent complexity of the field. Previous work has either been limited to small-scale studies due to the labor-intensive nature of manual analysis or has relied on large-scale bibliometric approaches that sacrifice contextual richness. This paper introduces an automatic and scalable feature-extraction pipeline to measure data and code availability in transportation research. We employ Large Language Models (LLMs) for this task and validate their performance against a manually curated dataset and through an inter-rater agreement analysis. We applied this pipeline to examine 10,724 research articles published in the Transportation Research Part series of journals between 2019 and 2024. Our analysis found that only 5% of quantitative papers shared a code repository, 4% of quantitative papers shared a data repository, and about 3% of papers shared both, with trends differing across journals, topics, and geographic regions. We found no significant difference in citation counts or review duration between papers that provided data and code and those that did not, suggesting a misalignment between open science efforts and traditional academic metrics. Consequently, encouraging these practices will likely require structural interventions from journals and funding agencies to supplement the lack of direct author incentives. The pipeline developed in this study can be readily scaled to other journals, representing a critical step toward the automated measurement and monitoring of open science practices in transportation research.
Schrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
Aixel: A Unified, Adaptive and Extensible System for AI-powered Data Analysis
Oct 14, 2025A growing trend in modern data analysis is the integration of data management with learning, guided by accuracy, latency, and cost requirements. In practice, applications draw data of different formats from many sources. In the meanwhile, the objectives and budgets change over time. Existing systems handle these applications across databases, analysis libraries, and tuning services. Such fragmentation leads to complex user interaction, limited adaptability, suboptimal performance, and poor extensibility across components. To address these challenges, we present Aixel, a unified, adaptive, and extensible system for AI-powered data analysis. The system organizes work across four layers: application, task, model, and data. The task layer provides a declarative interface to capture user intent, which is parsed into an executable operator plan. An optimizer compiles and schedules this plan to meet specified goals in accuracy, latency, and cost. The task layer coordinates the execution of data and model operators, with built-in support for reuse and caching to improve efficiency. The model layer offers versioned storage for index, metadata, tensors, and model artifacts. It supports adaptive construction, task-aligned drift detection, and safe updates that reuse shared components. The data layer provides unified data management capabilities, including indexing, constraint-aware discovery, task-aligned selection, and comprehensive feature management. With the above designed layers, Aixel delivers a user friendly, adaptive, efficient, and extensible system.
Meta-SurDiff: Classification Diffusion Model Optimized by Meta Learning is Reliable for Online Surgical Phase Recognition
Jun 17, 2025



Online surgical phase recognition has drawn great attention most recently due to its potential downstream applications closely related to human life and health. Despite deep models have made significant advances in capturing the discriminative long-term dependency of surgical videos to achieve improved recognition, they rarely account for exploring and modeling the uncertainty in surgical videos, which should be crucial for reliable online surgical phase recognition. We categorize the sources of uncertainty into two types, frame ambiguity in videos and unbalanced distribution among surgical phases, which are inevitable in surgical videos. To address this pivot issue, we introduce a meta-learning-optimized classification diffusion model (Meta-SurDiff), to take full advantage of the deep generative model and meta-learning in achieving precise frame-level distribution estimation for reliable online surgical phase recognition. For coarse recognition caused by ambiguous video frames, we employ a classification diffusion model to assess the confidence of recognition results at a finer-grained frame-level instance. For coarse recognition caused by unbalanced phase distribution, we use a meta-learning based objective to learn the diffusion model, thus enhancing the robustness of classification boundaries for different surgical phases.We establish effectiveness of Meta-SurDiff in online surgical phase recognition through extensive experiments on five widely used datasets using more than four practical metrics. The datasets include Cholec80, AutoLaparo, M2Cai16, OphNet, and NurViD, where OphNet comes from ophthalmic surgeries, NurViD is the daily care dataset, while the others come from laparoscopic surgeries. We will release the code upon acceptance.
Few-shot Semantic Encoding and Decoding for Video Surveillance
May 12, 2025With the continuous increase in the number and resolution of video surveillance cameras, the burden of transmitting and storing surveillance video is growing. Traditional communication methods based on Shannon's theory are facing optimization bottlenecks. Semantic communication, as an emerging communication method, is expected to break through this bottleneck and reduce the storage and transmission consumption of video. Existing semantic decoding methods often require many samples to train the neural network for each scene, which is time-consuming and labor-intensive. In this study, a semantic encoding and decoding method for surveillance video is proposed. First, the sketch was extracted as semantic information, and a sketch compression method was proposed to reduce the bit rate of semantic information. Then, an image translation network was proposed to translate the sketch into a video frame with a reference frame. Finally, a few-shot sketch decoding network was proposed to reconstruct video from sketch. Experimental results showed that the proposed method achieved significantly better video reconstruction performance than baseline methods. The sketch compression method could effectively reduce the storage and transmission consumption of semantic information with little compromise on video quality. The proposed method provides a novel semantic encoding and decoding method that only needs a few training samples for each surveillance scene, thus improving the practicality of the semantic communication system.
Can Diffusion Models Disentangle? A Theoretical Perspective
Mar 31, 2025This paper presents a novel theoretical framework for understanding how diffusion models can learn disentangled representations. Within this framework, we establish identifiability conditions for general disentangled latent variable models, analyze training dynamics, and derive sample complexity bounds for disentangled latent subspace models. To validate our theory, we conduct disentanglement experiments across diverse tasks and modalities, including subspace recovery in latent subspace Gaussian mixture models, image colorization, image denoising, and voice conversion for speech classification. Additionally, our experiments show that training strategies inspired by our theory, such as style guidance regularization, consistently enhance disentanglement performance.
Contextual Bandit with Herding Effects: Algorithms and Recommendation Applications
Aug 26, 2024Contextual bandits serve as a fundamental algorithmic framework for optimizing recommendation decisions online. Though extensive attention has been paid to tailoring contextual bandits for recommendation applications, the "herding effects" in user feedback have been ignored. These herding effects bias user feedback toward historical ratings, breaking down the assumption of unbiased feedback inherent in contextual bandits. This paper develops a novel variant of the contextual bandit that is tailored to address the feedback bias caused by the herding effects. A user feedback model is formulated to capture this feedback bias. We design the TS-Conf (Thompson Sampling under Conformity) algorithm, which employs posterior sampling to balance the exploration and exploitation tradeoff. We prove an upper bound for the regret of the algorithm, revealing the impact of herding effects on learning speed. Extensive experiments on datasets demonstrate that TS-Conf outperforms four benchmark algorithms. Analysis reveals that TS-Conf effectively mitigates the negative impact of herding effects, resulting in faster learning and improved recommendation accuracy.
Automatic Prediction of Amyotrophic Lateral Sclerosis Progression using Longitudinal Speech Transformer
Jun 26, 2024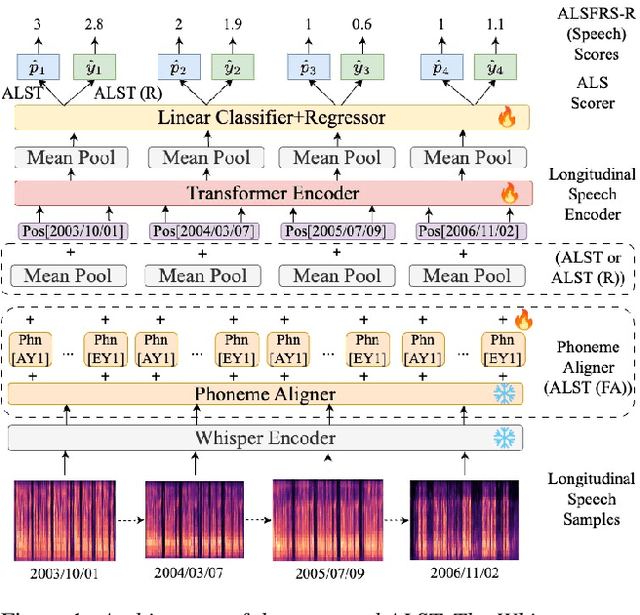
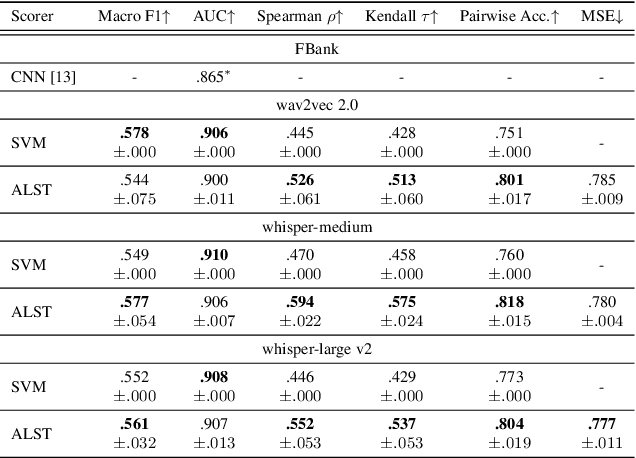

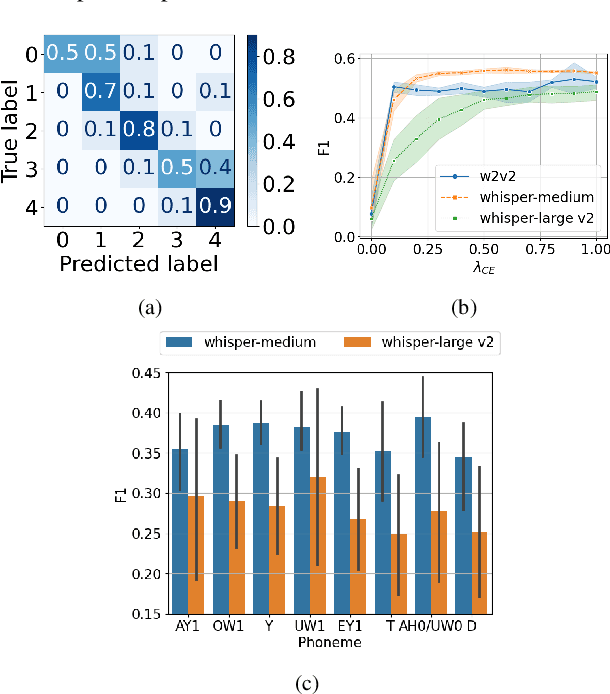
Automatic prediction of amyotrophic lateral sclerosis (ALS) disease progression provides a more efficient and objective alternative than manual approaches. We propose ALS longitudinal speech transformer (ALST), a neural network-based automatic predictor of ALS disease progression from longitudinal speech recordings of ALS patients. By taking advantage of high-quality pretrained speech features and longitudinal information in the recordings, our best model achieves 91.0\% AUC, improving upon the previous best model by 5.6\% relative on the ALS TDI dataset. Careful analysis reveals that ALST is capable of fine-grained and interpretable predictions of ALS progression, especially for distinguishing between rarer and more severe cases. Code is publicly available.
NTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024


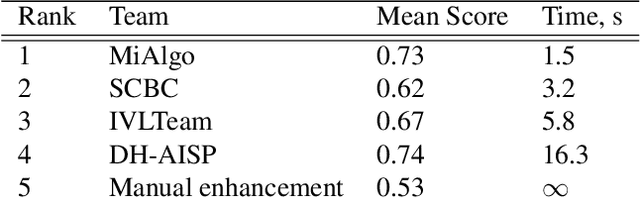
This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
Towards Unsupervised Speech Recognition Without Pronunciation Models
Jun 12, 2024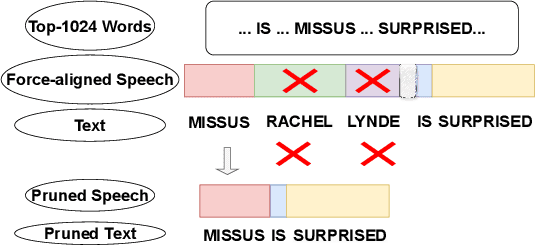
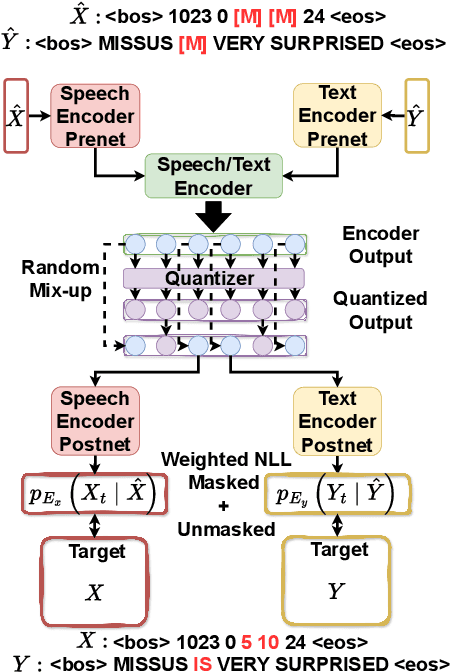
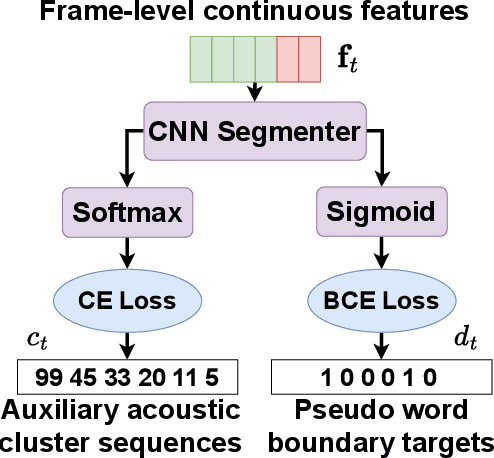
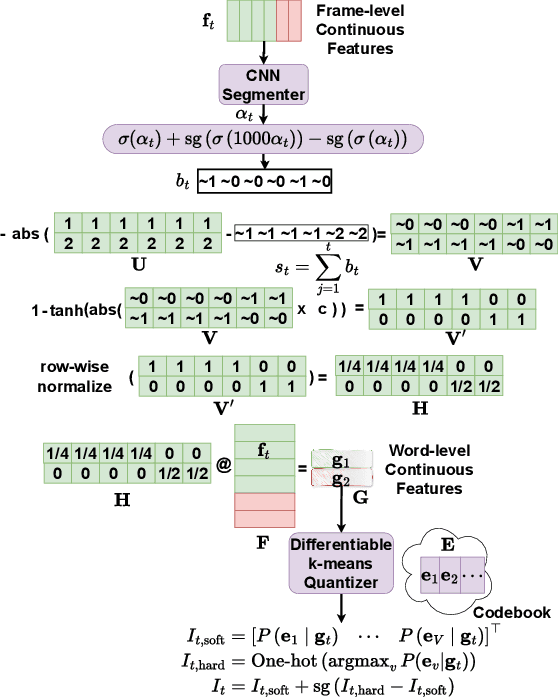
Recent advancements in supervised automatic speech recognition (ASR) have achieved remarkable performance, largely due to the growing availability of large transcribed speech corpora. However, most languages lack sufficient paired speech and text data to effectively train these systems. In this article, we tackle the challenge of developing ASR systems without paired speech and text corpora by proposing the removal of reliance on a phoneme lexicon. We explore a new research direction: word-level unsupervised ASR. Using a curated speech corpus containing only high-frequency English words, our system achieves a word error rate of nearly 20% without parallel transcripts or oracle word boundaries. Furthermore, we experimentally demonstrate that an unsupervised speech recognizer can emerge from joint speech-to-speech and text-to-text masked token-infilling. This innovative model surpasses the performance of previous unsupervised ASR models trained with direct distribution matching.