 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Step Diffusion with Inverse Residual Fields for Unsupervised Industrial Anomaly Detection
Apr 20, 2026Diffusion models have achieved outstanding performance in unsupervised industrial anomaly detection (uIAD) by learning a manifold of normal data under the common assumption that off-manifold anomalies are harder to generate, resulting in larger reconstruction errors in data space or lower probability densities in the tractable latent space. However, their iterative denoising and noising nature leads to slow inference. In this paper, we propose OSD-IRF, a novel one-step diffusion with inverse residual fields, to address this limitation for uIAD task. We first train a deep diffusion probabilistic model (DDPM) on normal data without any conditioning. Then, for a test sample, we predict its inverse residual fields (IRF) based on the noise estimated by the well-trained parametric noise function of the DDPM. Finally, uIAD is performed by evaluating the probability density of the IRF under a Gaussian distribution and comparing it with a threshold. Our key observation is that anomalies become distinguishable in this IRF space, a finding that has seldom been reported in prior works. Moreover, OSD-IRF requires only single step diffusion for uIAD, thanks to the property that IRF holds for any neighboring time step in the denoising process. Extensive experiments on three widely used uIAD benchmarks show that our model achieves SOTA or competitive performance across six metrics, along with roughly a 2X inference speedup without distillation.
FastRef:Fast Prototype Refinement for Few-Shot Industrial Anomaly Detection
Jun 26, 2025Few-shot industrial anomaly detection (FS-IAD) presents a critical challenge for practical automated inspection systems operating in data-scarce environments. While existing approaches predominantly focus on deriving prototypes from limited normal samples, they typically neglect to systematically incorporate query image statistics to enhance prototype representativeness. To address this issue, we propose FastRef, a novel and efficient prototype refinement framework for FS-IAD. Our method operates through an iterative two-stage process: (1) characteristic transfer from query features to prototypes via an optimizable transformation matrix, and (2) anomaly suppression through prototype alignment. The characteristic transfer is achieved through linear reconstruction of query features from prototypes, while the anomaly suppression addresses a key observation in FS-IAD that unlike conventional IAD with abundant normal prototypes, the limited-sample setting makes anomaly reconstruction more probable. Therefore, we employ optimal transport (OT) for non-Gaussian sampled features to measure and minimize the gap between prototypes and their refined counterparts for anomaly suppression. For comprehensive evaluation, we integrate FastRef with three competitive prototype-based FS-IAD methods: PatchCore, FastRecon, WinCLIP, and AnomalyDINO. Extensive experiments across four benchmark datasets of MVTec, ViSA, MPDD and RealIAD demonstrate both the effectiveness and computational efficiency of our approach under 1/2/4-shots.
Meta-SurDiff: Classification Diffusion Model Optimized by Meta Learning is Reliable for Online Surgical Phase Recognition
Jun 17, 2025



Online surgical phase recognition has drawn great attention most recently due to its potential downstream applications closely related to human life and health. Despite deep models have made significant advances in capturing the discriminative long-term dependency of surgical videos to achieve improved recognition, they rarely account for exploring and modeling the uncertainty in surgical videos, which should be crucial for reliable online surgical phase recognition. We categorize the sources of uncertainty into two types, frame ambiguity in videos and unbalanced distribution among surgical phases, which are inevitable in surgical videos. To address this pivot issue, we introduce a meta-learning-optimized classification diffusion model (Meta-SurDiff), to take full advantage of the deep generative model and meta-learning in achieving precise frame-level distribution estimation for reliable online surgical phase recognition. For coarse recognition caused by ambiguous video frames, we employ a classification diffusion model to assess the confidence of recognition results at a finer-grained frame-level instance. For coarse recognition caused by unbalanced phase distribution, we use a meta-learning based objective to learn the diffusion model, thus enhancing the robustness of classification boundaries for different surgical phases.We establish effectiveness of Meta-SurDiff in online surgical phase recognition through extensive experiments on five widely used datasets using more than four practical metrics. The datasets include Cholec80, AutoLaparo, M2Cai16, OphNet, and NurViD, where OphNet comes from ophthalmic surgeries, NurViD is the daily care dataset, while the others come from laparoscopic surgeries. We will release the code upon acceptance.
Hierarchical Vector Quantized Transformer for Multi-class Unsupervised Anomaly Detection
Oct 22, 2023



Unsupervised image Anomaly Detection (UAD) aims to learn robust and discriminative representations of normal samples. While separate solutions per class endow expensive computation and limited generalizability, this paper focuses on building a unified framework for multiple classes. Under such a challenging setting, popular reconstruction-based networks with continuous latent representation assumption always suffer from the "identical shortcut" issue, where both normal and abnormal samples can be well recovered and difficult to distinguish. To address this pivotal issue, we propose a hierarchical vector quantized prototype-oriented Transformer under a probabilistic framework. First, instead of learning the continuous representations, we preserve the typical normal patterns as discrete iconic prototypes, and confirm the importance of Vector Quantization in preventing the model from falling into the shortcut. The vector quantized iconic prototype is integrated into the Transformer for reconstruction, such that the abnormal data point is flipped to a normal data point.Second, we investigate an exquisite hierarchical framework to relieve the codebook collapse issue and replenish frail normal patterns. Third, a prototype-oriented optimal transport method is proposed to better regulate the prototypes and hierarchically evaluate the abnormal score. By evaluating on MVTec-AD and VisA datasets, our model surpasses the state-of-the-art alternatives and possesses good interpretability. The code is available at https://github.com/RuiyingLu/HVQ-Trans.
Prototypes-oriented Transductive Few-shot Learning with Conditional Transport
Aug 06, 2023Transductive Few-Shot Learning (TFSL) has recently attracted increasing attention since it typically outperforms its inductive peer by leveraging statistics of query samples. However, previous TFSL methods usually encode uniform prior that all the classes within query samples are equally likely, which is biased in imbalanced TFSL and causes severe performance degradation. Given this pivotal issue, in this work, we propose a novel Conditional Transport (CT) based imbalanced TFSL model called {\textbf P}rototypes-oriented {\textbf U}nbiased {\textbf T}ransfer {\textbf M}odel (PUTM) to fully exploit unbiased statistics of imbalanced query samples, which employs forward and backward navigators as transport matrices to balance the prior of query samples per class between uniform and adaptive data-driven distributions. For efficiently transferring statistics learned by CT, we further derive a closed form solution to refine prototypes based on MAP given the learned navigators. The above two steps of discovering and transferring unbiased statistics follow an iterative manner, formulating our EM-based solver. Experimental results on four standard benchmarks including miniImageNet, tieredImageNet, CUB, and CIFAR-FS demonstrate superiority of our model in class-imbalanced generalization.
Adaptive Distribution Calibration for Few-Shot Learning with Hierarchical Optimal Transport
Oct 09, 2022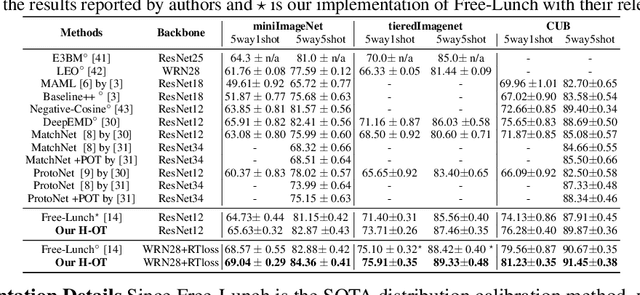
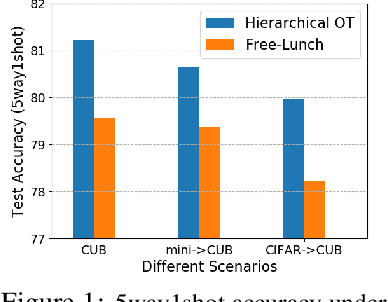
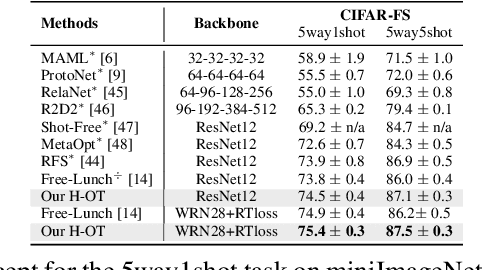

Few-shot classification aims to learn a classifier to recognize unseen classes during training, where the learned model can easily become over-fitted based on the biased distribution formed by only a few training examples. A recent solution to this problem is calibrating the distribution of these few sample classes by transferring statistics from the base classes with sufficient examples, where how to decide the transfer weights from base classes to novel classes is the key. However, principled approaches for learning the transfer weights have not been carefully studied. To this end, we propose a novel distribution calibration method by learning the adaptive weight matrix between novel samples and base classes, which is built upon a hierarchical Optimal Transport (H-OT) framework. By minimizing the high-level OT distance between novel samples and base classes, we can view the learned transport plan as the adaptive weight information for transferring the statistics of base classes. The learning of the cost function between a base class and novel class in the high-level OT leads to the introduction of the low-level OT, which considers the weights of all the data samples in the base class. Experimental results on standard benchmarks demonstrate that our proposed plug-and-play model outperforms competing approaches and owns desired cross-domain generalization ability, indicating the effectiveness of the learned adaptive weights.
Learning Prototype-oriented Set Representations for Meta-Learning
Oct 18, 2021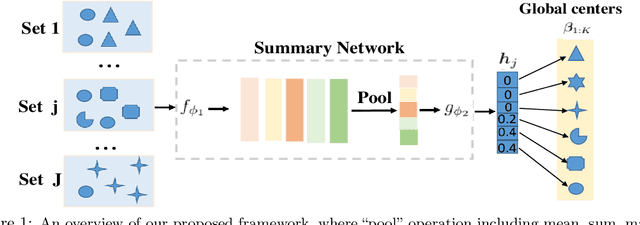

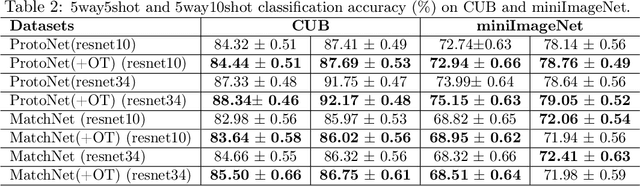
Learning from set-structured data is a fundamental problem that has recently attracted increasing attention, where a series of summary networks are introduced to deal with the set input. In fact, many meta-learning problems can be treated as set-input tasks. Most existing summary networks aim to design different architectures for the input set in order to enforce permutation invariance. However, scant attention has been paid to the common cases where different sets in a meta-distribution are closely related and share certain statistical properties. Viewing each set as a distribution over a set of global prototypes, this paper provides a novel optimal transport (OT) based way to improve existing summary networks. To learn the distribution over the global prototypes, we minimize its OT distance to the set empirical distribution over data points, providing a natural unsupervised way to improve the summary network. Since our plug-and-play framework can be applied to many meta-learning problems, we further instantiate it to the cases of few-shot classification and implicit meta generative modeling. Extensive experiments demonstrate that our framework significantly improves the existing summary networks on learning more powerful summary statistics from sets and can be successfully integrated into metric-based few-shot classification and generative modeling applications, providing a promising tool for addressing set-input and meta-learning problems.
Variational Hetero-Encoder Randomized Generative Adversarial Networks for Joint Image-Text Modeling
May 18, 2019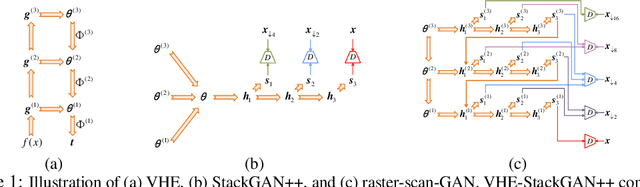

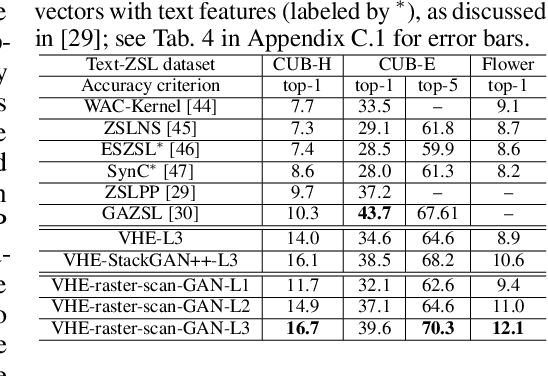

For bidirectional joint image-text modeling, we develop variational hetero-encoder (VHE) randomized generative adversarial network (GAN) that integrates a probabilistic text decoder, probabilistic image encoder, and GAN into a coherent end-to-end multi-modality learning framework. VHE randomized GAN (VHE-GAN) encodes an image to decode its associated text, and feeds the variational posterior as the source of randomness into the GAN image generator. We plug three off-the-shelf modules, including a deep topic model, a ladder-structured image encoder, and StackGAN++, into VHE-GAN, which already achieves competitive performance. This further motivates the development of VHE-raster-scan-GAN that generates photo-realistic images in not only a multi-scale low-to-high-resolution manner, but also a hierarchical-semantic coarse-to-fine fashion. By capturing and relating hierarchical semantic and visual concepts with end-to-end training, VHE-raster-scan-GAN achieves state-of-the-art performance in a wide variety of image-text multi-modality learning and generation tasks. PyTorch code is provided.