 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarding LLM Fine-tuning via Push-Pull Distributional Alignment
Jan 12, 2026The inherent safety alignment of Large Language Models (LLMs) is prone to erosion during fine-tuning, even when using seemingly innocuous datasets. While existing defenses attempt to mitigate this via data selection, they typically rely on heuristic, instance-level assessments that neglect the global geometry of the data distribution and fail to explicitly repel harmful patterns. To address this, we introduce Safety Optimal Transport (SOT), a novel framework that reframes safe fine-tuning from an instance-level filtering challenge to a distribution-level alignment task grounded in Optimal Transport (OT). At its core is a dual-reference ``push-pull'' weight-learning mechanism: SOT optimizes sample importance by actively pulling the downstream distribution towards a trusted safe anchor while simultaneously pushing it away from a general harmful reference. This establishes a robust geometric safety boundary that effectively purifies the training data. Extensive experiments across diverse model families and domains demonstrate that SOT significantly enhances model safety while maintaining competitive downstream performance, achieving a superior safety-utility trade-off compared to baselines.
PDR: A Plug-and-Play Positional Decay Framework for LLM Pre-training Data Detection
Jan 11, 2026Detecting pre-training data in Large Language Models (LLMs) is crucial for auditing data privacy and copyright compliance, yet it remains challenging in black-box, zero-shot settings where computational resources and training data are scarce. While existing likelihood-based methods have shown promise, they typically aggregate token-level scores using uniform weights, thereby neglecting the inherent information-theoretic dynamics of autoregressive generation. In this paper, we hypothesize and empirically validate that memorization signals are heavily skewed towards the high-entropy initial tokens, where model uncertainty is highest, and decay as context accumulates. To leverage this linguistic property, we introduce Positional Decay Reweighting (PDR), a training-free and plug-and-play framework. PDR explicitly reweights token-level scores to amplify distinct signals from early positions while suppressing noise from later ones. Extensive experiments show that PDR acts as a robust prior and can usually enhance a wide range of advanced methods across multiple benchmarks.
A Guardrail for Safety Preservation: When Safety-Sensitive Subspace Meets Harmful-Resistant Null-Space
Oct 16, 2025Large language models (LLMs) have achieved remarkable success in diverse tasks, yet their safety alignment remains fragile during adaptation. Even when fine-tuning on benign data or with low-rank adaptation, pre-trained safety behaviors are easily degraded, leading to harmful responses in the fine-tuned models. To address this challenge, we propose GuardSpace, a guardrail framework for preserving safety alignment throughout fine-tuning, composed of two key components: a safety-sensitive subspace and a harmful-resistant null space. First, we explicitly decompose pre-trained weights into safety-relevant and safety-irrelevant components using covariance-preconditioned singular value decomposition, and initialize low-rank adapters from the safety-irrelevant ones, while freezing safety-relevant components to preserve their associated safety mechanism. Second, we construct a null space projector that restricts adapter updates from altering safe outputs on harmful prompts, thereby maintaining the original refusal behavior. Experiments with various pre-trained models on multiple downstream tasks demonstrate that GuardSpace achieves superior performance over existing methods. Notably, for Llama-2-7B-Chat fine-tuned on GSM8K, GuardSpace outperforms the state-of-the-art method AsFT, reducing the average harmful score from 14.4% to 3.6%, while improving the accuracy from from 26.0% to 28.0%.
Deep Neural Network Calibration by Reducing Classifier Shift with Stochastic Masking
Aug 12, 2025In recent years, deep neural networks (DNNs) have shown competitive results in many fields. Despite this success, they often suffer from poor calibration, especially in safety-critical scenarios such as autonomous driving and healthcare, where unreliable confidence estimates can lead to serious consequences. Recent studies have focused on improving calibration by modifying the classifier, yet such efforts remain limited. Moreover, most existing approaches overlook calibration errors caused by underconfidence, which can be equally detrimental. To address these challenges, we propose MaC-Cal, a novel mask-based classifier calibration method that leverages stochastic sparsity to enhance the alignment between confidence and accuracy. MaC-Cal adopts a two-stage training scheme with adaptive sparsity, dynamically adjusting mask retention rates based on the deviation between confidence and accuracy. Extensive experiments show that MaC-Cal achieves superior calibration performance and robustness under data corruption, offering a practical and effective solution for reliable confidence estimation in DNNs.
Merging Smarter, Generalizing Better: Enhancing Model Merging on OOD Data
Jun 10, 2025Multi-task learning (MTL) concurrently trains a model on diverse task datasets to exploit common features, thereby improving overall performance across the tasks. Recent studies have dedicated efforts to merging multiple independent model parameters into a unified model for MTL, thus circumventing the need for training data and expanding the scope of applicable scenarios of MTL. However, current approaches to model merging predominantly concentrate on enhancing performance within in-domain (ID) datasets, often overlooking their efficacy on out-of-domain (OOD) datasets. In this work, we proposed LwPTV (Layer-wise Pruning Task Vector) by building a saliency score, measuring the redundancy of parameters in task vectors. Designed in this way ours can achieve mask vector for each task and thus perform layer-wise pruning on the task vectors, only keeping the pre-trained model parameters at the corresponding layer in merged model. Owing to its flexibility, our method can be seamlessly integrated with most of existing model merging methods to improve their performance on OOD tasks. Extensive experiments demonstrate that the application of our method results in substantial enhancements in OOD performance while preserving the ability on ID tasks.
LLM Meeting Decision Trees on Tabular Data
May 23, 2025Tabular data have been playing a vital role in diverse real-world fields, including healthcare, finance, etc. With the recent success of Large Language Models (LLMs), early explorations of extending LLMs to the domain of tabular data have been developed. Most of these LLM-based methods typically first serialize tabular data into natural language descriptions, and then tune LLMs or directly infer on these serialized data. However, these methods suffer from two key inherent issues: (i) data perspective: existing data serialization methods lack universal applicability for structured tabular data, and may pose privacy risks through direct textual exposure, and (ii) model perspective: LLM fine-tuning methods struggle with tabular data, and in-context learning scalability is bottle-necked by input length constraints (suitable for few-shot learning). This work explores a novel direction of integrating LLMs into tabular data throughough logical decision tree rules as intermediaries, proposes a decision tree enhancer with LLM-derived rule for tabular prediction, DeLTa. The proposed DeLTa avoids tabular data serialization, and can be applied to full data learning setting without LLM fine-tuning. Specifically, we leverage the reasoning ability of LLMs to redesign an improved rule given a set of decision tree rules. Furthermore, we provide a calibration method for original decision trees via new generated rule by LLM, which approximates the error correction vector to steer the original decision tree predictions in the direction of ``errors'' reducing. Finally, extensive experiments on diverse tabular benchmarks show that our method achieves state-of-the-art performance.
Beyond Words: Augmenting Discriminative Richness via Diffusions in Unsupervised Prompt Learning
Apr 16, 2025Fine-tuning vision-language models (VLMs) with large amounts of unlabeled data has recently garnered significant interest. However, a key challenge remains the lack of high-quality pseudo-labeled data. Current pseudo-labeling strategies often struggle with mismatches between semantic and visual information, leading to sub-optimal performance of unsupervised prompt learning (UPL) methods. In this paper, we introduce a simple yet effective approach called \textbf{A}ugmenting D\textbf{i}scriminative \textbf{R}ichness via Diffusions (AiR), toward learning a richer discriminating way to represent the class comprehensively and thus facilitate classification. Specifically, our approach includes a pseudo-label generation module that leverages high-fidelity synthetic samples to create an auxiliary classifier, which captures richer visual variation, bridging text-image-pair classification to a more robust image-image-pair classification. Additionally, we exploit the diversity of diffusion-based synthetic samples to enhance prompt learning, providing greater information for semantic-visual alignment. Extensive experiments on five public benchmarks, including RESISC45 and Flowers102, and across three learning paradigms-UL, SSL, and TRZSL-demonstrate that AiR achieves substantial and consistent performance improvements over state-of-the-art unsupervised prompt learning methods.
Balancing Two Classifiers via A Simplex ETF Structure for Model Calibration
Apr 14, 2025In recent years, deep neural networks (DNNs) have demonstrated state-of-the-art performance across various domains. However, despite their success, they often face calibration issues, particularly in safety-critical applications such as autonomous driving and healthcare, where unreliable predictions can have serious consequences. Recent research has started to improve model calibration from the view of the classifier. However, the exploration of designing the classifier to solve the model calibration problem is insufficient. Let alone most of the existing methods ignore the calibration errors arising from underconfidence. In this work, we propose a novel method by balancing learnable and ETF classifiers to solve the overconfidence or underconfidence problem for model Calibration named BalCAL. By introducing a confidence-tunable module and a dynamic adjustment method, we ensure better alignment between model confidence and its true accuracy. Extensive experimental validation shows that ours significantly improves model calibration performance while maintaining high predictive accuracy, outperforming existing techniques. This provides a novel solution to the calibration challenges commonly encountered in deep learning.
FedAWA: Adaptive Optimization of Aggregation Weights in Federated Learning Using Client Vectors
Mar 20, 2025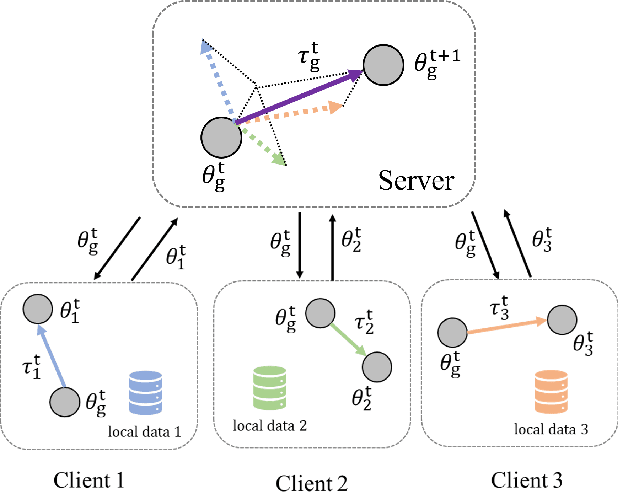
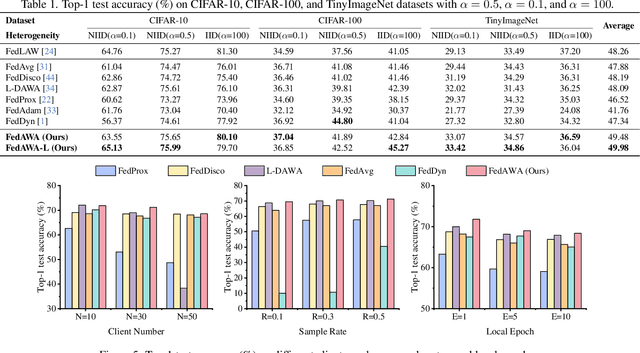
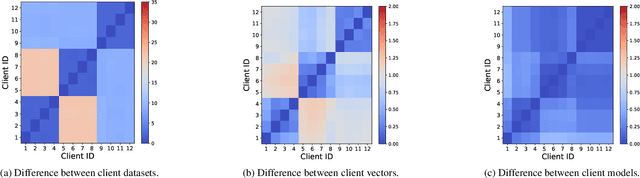
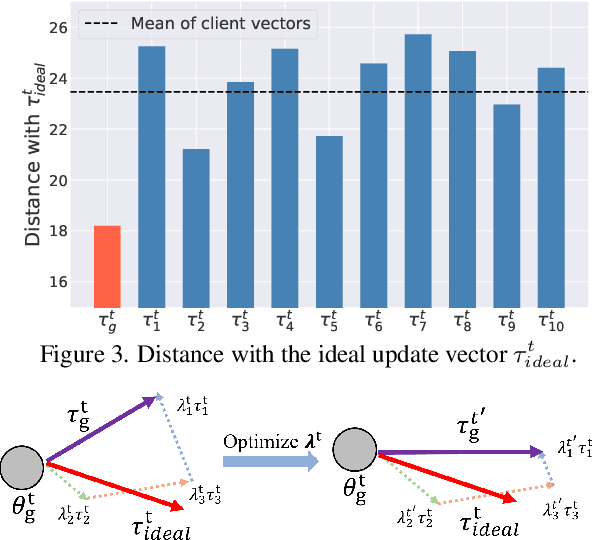
Federated Learning (FL) has emerged as a promising framework for distributed machine learning, enabling collaborative model training without sharing local data, thereby preserving privacy and enhancing security. However, data heterogeneity resulting from differences across user behaviors, preferences, and device characteristics poses a significant challenge for federated learning. Most previous works overlook the adjustment of aggregation weights, relying solely on dataset size for weight assignment, which often leads to unstable convergence and reduced model performance. Recently, several studies have sought to refine aggregation strategies by incorporating dataset characteristics and model alignment. However, adaptively adjusting aggregation weights while ensuring data security-without requiring additional proxy data-remains a significant challenge. In this work, we propose Federated learning with Adaptive Weight Aggregation (FedAWA), a novel method that adaptively adjusts aggregation weights based on client vectors during the learning process. The client vector captures the direction of model updates, reflecting local data variations, and is used to optimize the aggregation weight without requiring additional datasets or violating privacy. By assigning higher aggregation weights to local models whose updates align closely with the global optimization direction, FedAWA enhances the stability and generalization of the global model. Extensive experiments under diverse scenarios demonstrate the superiority of our method, providing a promising solution to the challenges of data heterogeneity in federated learning.
PTaRL: Prototype-based Tabular Representation Learning via Space Calibration
Jul 07, 2024
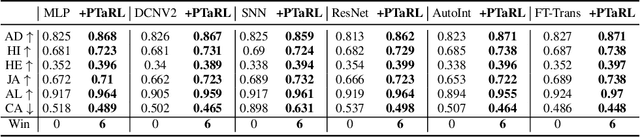


Tabular data have been playing a mostly important role in diverse real-world fields, such as healthcare, engineering, finance, etc. With the recent success of deep learning, many tabular machine learning (ML) methods based on deep networks (e.g., Transformer, ResNet) have achieved competitive performance on tabular benchmarks. However, existing deep tabular ML methods suffer from the representation entanglement and localization, which largely hinders their prediction performance and leads to performance inconsistency on tabular tasks. To overcome these problems, we explore a novel direction of applying prototype learning for tabular ML and propose a prototype-based tabular representation learning framework, PTaRL, for tabular prediction tasks. The core idea of PTaRL is to construct prototype-based projection space (P-Space) and learn the disentangled representation around global data prototypes. Specifically, PTaRL mainly involves two stages: (i) Prototype Generation, that constructs global prototypes as the basis vectors of P-Space for representation, and (ii) Prototype Projection, that projects the data samples into P-Space and keeps the core global data information via Optimal Transport. Then, to further acquire the disentangled representations, we constrain PTaRL with two strategies: (i) to diversify the coordinates towards global prototypes of different representations within P-Space, we bring up a diversification constraint for representation calibration; (ii) to avoid prototype entanglement in P-Space, we introduce a matrix orthogonalization constraint to ensure the independence of global prototypes. Finally, we conduct extensive experiments in PTaRL coupled with state-of-the-art deep tabular ML models on various tabular benchmarks and the results have shown our consistent superiority.