 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeking Flat Minima over Diverse Surrogates for Improved Adversarial Transferability: A Theoretical Framework and Algorithmic Instantiation
Apr 23, 2025



The transfer-based black-box adversarial attack setting poses the challenge of crafting an adversarial example (AE) on known surrogate models that remain effective against unseen target models. Due to the practical importance of this task, numerous methods have been proposed to address this challenge. However, most previous methods are heuristically designed and intuitively justified, lacking a theoretical foundation. To bridge this gap, we derive a novel transferability bound that offers provable guarantees for adversarial transferability. Our theoretical analysis has the advantages of \textit{(i)} deepening our understanding of previous methods by building a general attack framework and \textit{(ii)} providing guidance for designing an effective attack algorithm. Our theoretical results demonstrate that optimizing AEs toward flat minima over the surrogate model set, while controlling the surrogate-target model shift measured by the adversarial model discrepancy, yields a comprehensive guarantee for AE transferability. The results further lead to a general transfer-based attack framework, within which we observe that previous methods consider only partial factors contributing to the transferability. Algorithmically, inspired by our theoretical results, we first elaborately construct the surrogate model set in which models exhibit diverse adversarial vulnerabilities with respect to AEs to narrow an instantiated adversarial model discrepancy. Then, a \textit{model-Diversity-compatible Reverse Adversarial Perturbation} (DRAP) is generated to effectively promote the flatness of AEs over diverse surrogate models to improve transferability. Extensive experiments on NIPS2017 and CIFAR-10 datasets against various target models demonstrate the effectiveness of our proposed attack.
Defenses in Adversarial Machine Learning: A Survey
Dec 13, 2023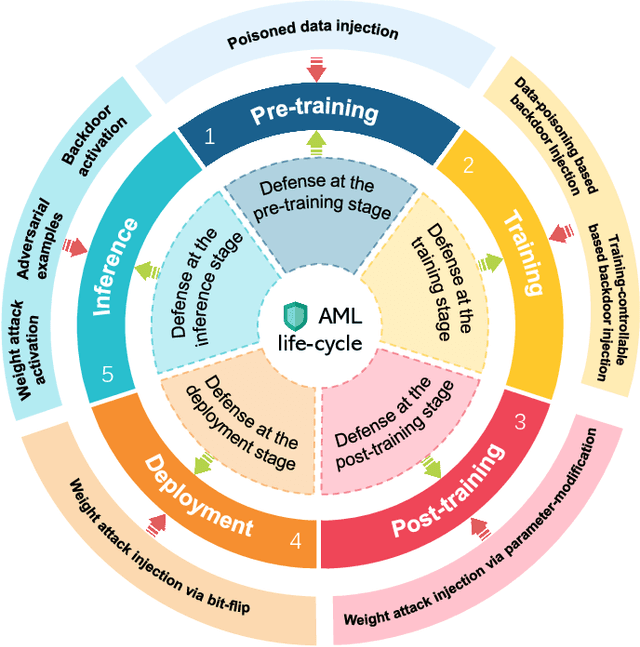
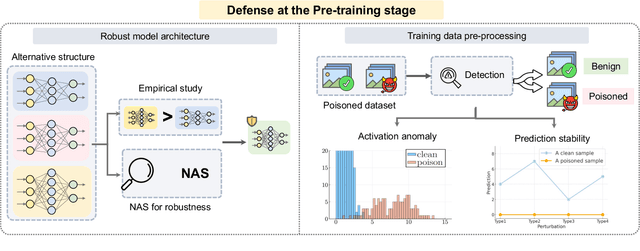
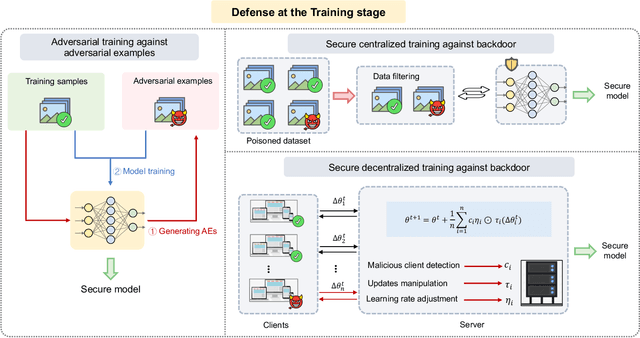
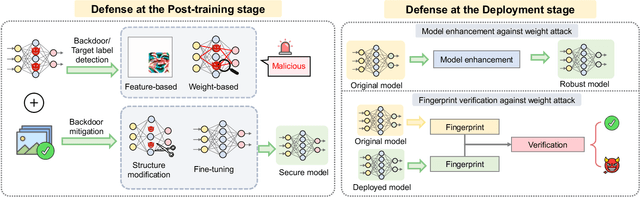
Adversarial phenomenon has been widely observed in machine learning (ML) systems, especially in those using deep neural networks, describing that ML systems may produce inconsistent and incomprehensible predictions with humans at some particular cases. This phenomenon poses a serious security threat to the practical application of ML systems, and several advanced attack paradigms have been developed to explore it, mainly including backdoor attacks, weight attacks, and adversarial examples. For each individual attack paradigm, various defense paradigms have been developed to improve the model robustness against the corresponding attack paradigm. However, due to the independence and diversity of these defense paradigms, it is difficult to examine the overall robustness of an ML system against different kinds of attacks.This survey aims to build a systematic review of all existing defense paradigms from a unified perspective. Specifically, from the life-cycle perspective, we factorize a complete machine learning system into five stages, including pre-training, training, post-training, deployment, and inference stages, respectively. Then, we present a clear taxonomy to categorize and review representative defense methods at each individual stage. The unified perspective and presented taxonomies not only facilitate the analysis of the mechanism of each defense paradigm but also help us to understand connections and differences among different defense paradigms, which may inspire future research to develop more advanced, comprehensive defenses.
Learning to Re-weight Examples with Optimal Transport for Imbalanced Classification
Aug 05, 2022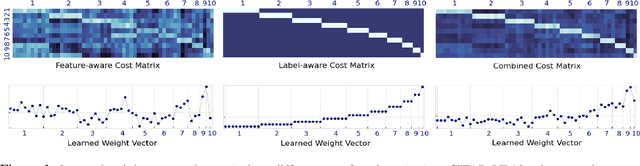



Imbalanced data pose challenges for deep learning based classification models. One of the most widely-used approaches for tackling imbalanced data is re-weighting, where training samples are associated with different weights in the loss function. Most of existing re-weighting approaches treat the example weights as the learnable parameter and optimize the weights on the meta set, entailing expensive bilevel optimization. In this paper, we propose a novel re-weighting method based on optimal transport (OT) from a distributional point of view. Specifically, we view the training set as an imbalanced distribution over its samples, which is transported by OT to a balanced distribution obtained from the meta set. The weights of the training samples are the probability mass of the imbalanced distribution and learned by minimizing the OT distance between the two distributions. Compared with existing methods, our proposed one disengages the dependence of the weight learning on the concerned classifier at each iteration. Experiments on image, text and point cloud datasets demonstrate that our proposed re-weighting method has excellent performance, achieving state-of-the-art results in many cases and providing a promising tool for addressing the imbalanced classification issue.