 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoorBench: A Comprehensive Benchmark and Analysis of Backdoor Learning
Jan 26, 2024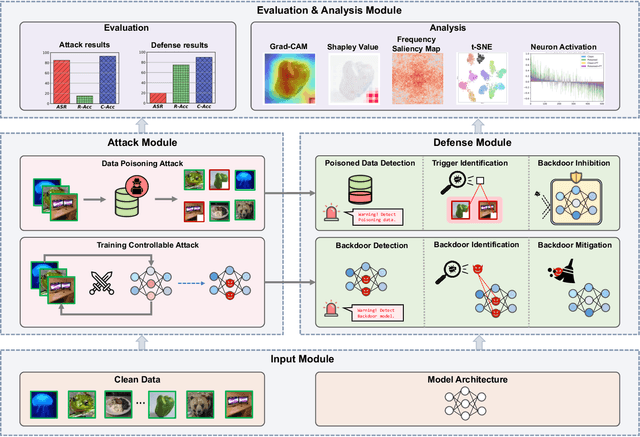
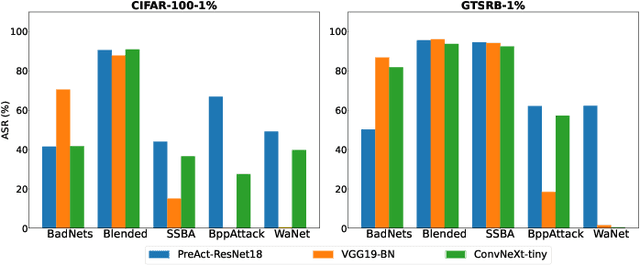
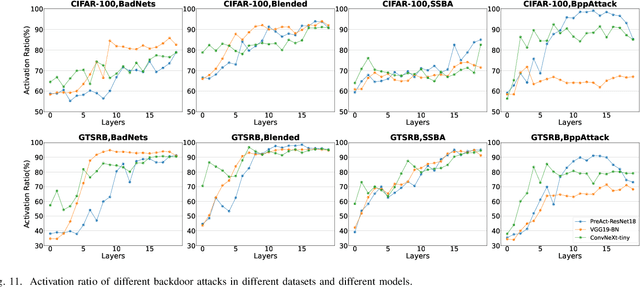

As an emerging and vital topic for studying deep neural networks' vulnerability (DNNs), backdoor learning has attracted increasing interest in recent years, and many seminal backdoor attack and defense algorithms are being developed successively or concurrently, in the status of a rapid arms race. However, mainly due to the diverse settings, and the difficulties of implementation and reproducibility of existing works, there is a lack of a unified and standardized benchmark of backdoor learning, causing unfair comparisons, and unreliable conclusions (e.g., misleading, biased or even false conclusions). Consequently, it is difficult to evaluate the current progress and design the future development roadmap of this literature. To alleviate this dilemma, we build a comprehensive benchmark of backdoor learning called BackdoorBench. Our benchmark makes three valuable contributions to the research community. 1) We provide an integrated implementation of state-of-the-art (SOTA) backdoor learning algorithms (currently including 16 attack and 27 defense algorithms), based on an extensible modular-based codebase. 2) We conduct comprehensive evaluations of 12 attacks against 16 defenses, with 5 poisoning ratios, based on 4 models and 4 datasets, thus 11,492 pairs of evaluations in total. 3) Based on above evaluations, we present abundant analysis from 8 perspectives via 18 useful analysis tools, and provide several inspiring insights about backdoor learning. We hope that our efforts could build a solid foundation of backdoor learning to facilitate researchers to investigate existing algorithms, develop more innovative algorithms, and explore the intrinsic mechanism of backdoor learning. Finally, we have created a user-friendly website at http://backdoorbench.com, which collects all important information of BackdoorBench, including codebase, docs, leaderboard, and model Zoo.
Defenses in Adversarial Machine Learning: A Survey
Dec 13, 2023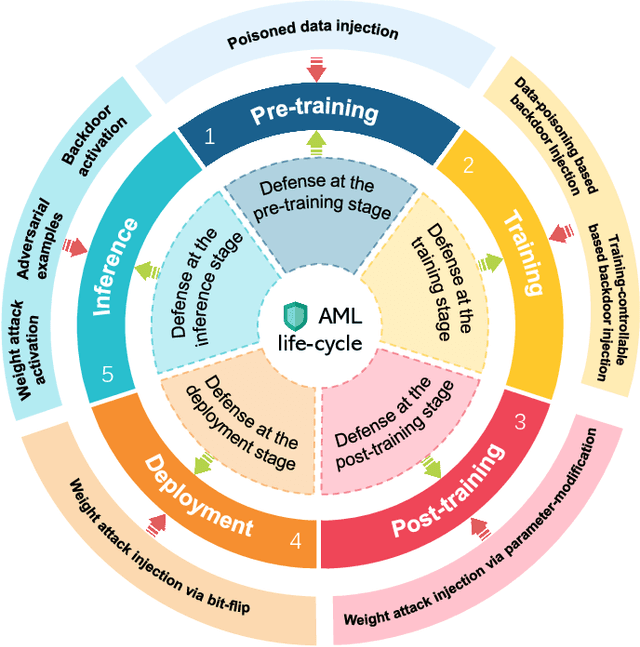
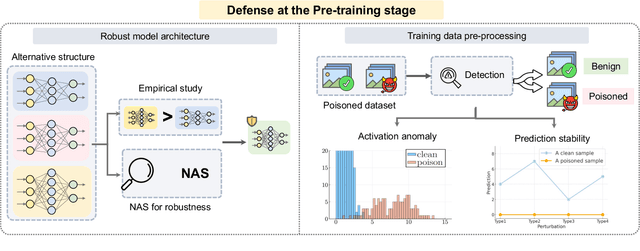
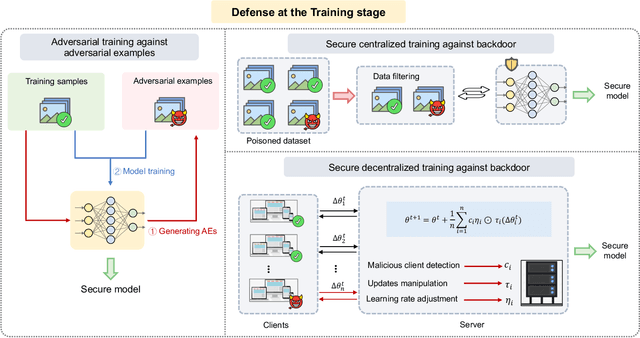
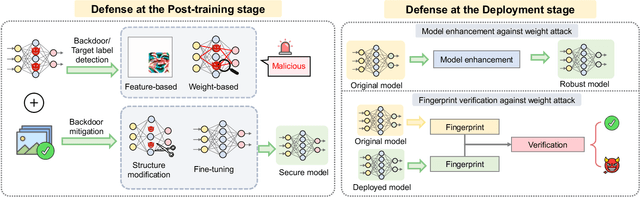
Adversarial phenomenon has been widely observed in machine learning (ML) systems, especially in those using deep neural networks, describing that ML systems may produce inconsistent and incomprehensible predictions with humans at some particular cases. This phenomenon poses a serious security threat to the practical application of ML systems, and several advanced attack paradigms have been developed to explore it, mainly including backdoor attacks, weight attacks, and adversarial examples. For each individual attack paradigm, various defense paradigms have been developed to improve the model robustness against the corresponding attack paradigm. However, due to the independence and diversity of these defense paradigms, it is difficult to examine the overall robustness of an ML system against different kinds of attacks.This survey aims to build a systematic review of all existing defense paradigms from a unified perspective. Specifically, from the life-cycle perspective, we factorize a complete machine learning system into five stages, including pre-training, training, post-training, deployment, and inference stages, respectively. Then, we present a clear taxonomy to categorize and review representative defense methods at each individual stage. The unified perspective and presented taxonomies not only facilitate the analysis of the mechanism of each defense paradigm but also help us to understand connections and differences among different defense paradigms, which may inspire future research to develop more advanced, comprehensive defenses.
Rethinking Data Augmentation in Knowledge Distillation for Object Detection
Sep 20, 2022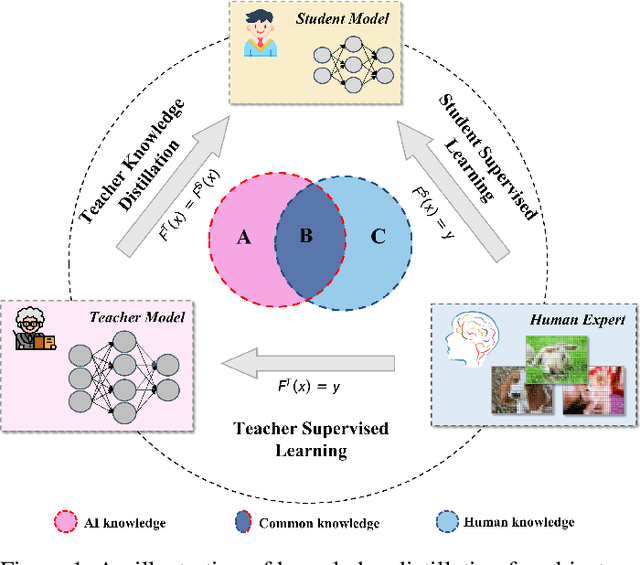
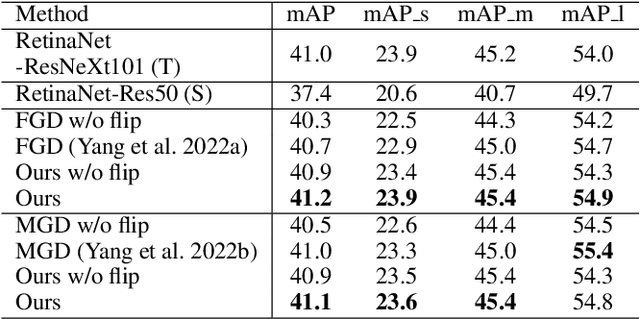
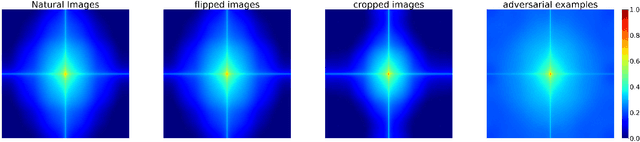

Knowledge distillation (KD) has shown its effectiveness for object detection, where it trains a compact object detector under the supervision of both AI knowledge (teacher detector) and human knowledge (human expert). However, existing studies treat the AI knowledge and human knowledge consistently and adopt a uniform data augmentation strategy during learning, which would lead to the biased learning of multi-scale objects and insufficient learning for the teacher detector causing unsatisfactory distillation performance. To tackle these problems, we propose the sample-specific data augmentation and adversarial feature augmentation. Firstly, to mitigate the impact incurred by multi-scale objects, we propose an adaptive data augmentation based on our observations from the Fourier perspective. Secondly, we propose a feature augmentation method based on adversarial examples for better mimicking AI knowledge to make up for the insufficient information mining of the teacher detector. Furthermore, our proposed method is unified and easily extended to other KD methods. Extensive experiments demonstrate the effectiveness of our framework and improve the performance of state-of-the-art methods in one-stage and two-stage detectors, bringing at most 0.5 mAP gains.
BackdoorBench: A Comprehensive Benchmark of Backdoor Learning
Jun 25, 2022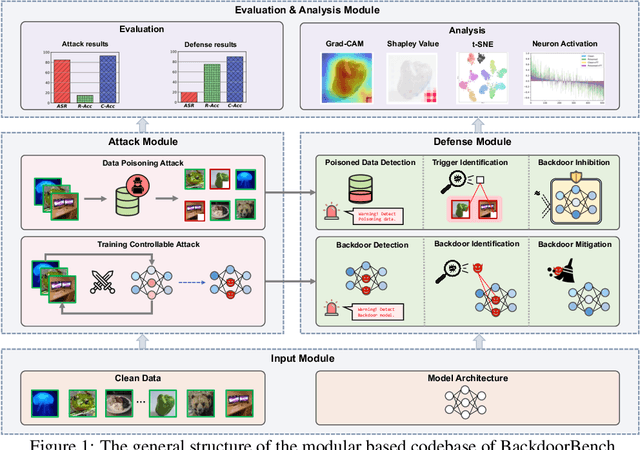
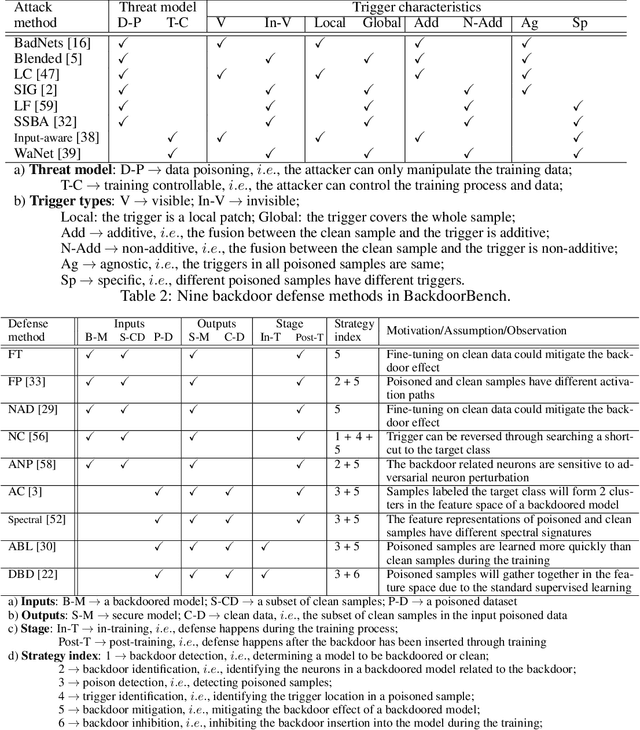
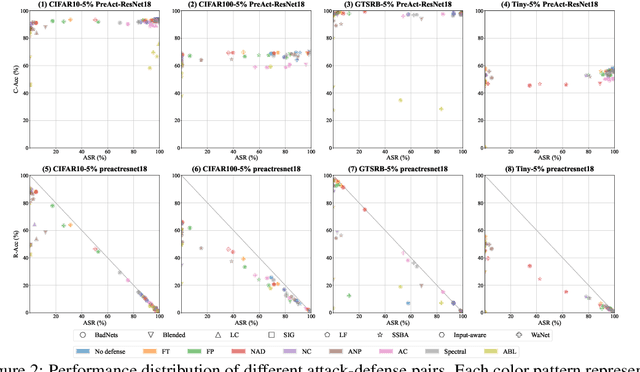

Backdoor learning is an emerging and important topic of studying the vulnerability of deep neural networks (DNNs). Many pioneering backdoor attack and defense methods are being proposed successively or concurrently, in the status of a rapid arms race. However, we find that the evaluations of new methods are often unthorough to verify their claims and real performance, mainly due to the rapid development, diverse settings, as well as the difficulties of implementation and reproducibility. Without thorough evaluations and comparisons, it is difficult to track the current progress and design the future development roadmap of the literature. To alleviate this dilemma, we build a comprehensive benchmark of backdoor learning, called BackdoorBench. It consists of an extensible modular based codebase (currently including implementations of 8 state-of-the-art (SOTA) attack and 9 SOTA defense algorithms), as well as a standardized protocol of a complete backdoor learning. We also provide comprehensive evaluations of every pair of 8 attacks against 9 defenses, with 5 poisoning ratios, based on 5 models and 4 datasets, thus 8,000 pairs of evaluations in total. We further present analysis from different perspectives about these 8,000 evaluations, studying the effects of attack against defense algorithms, poisoning ratio, model and dataset in backdoor learning. All codes and evaluations of BackdoorBench are publicly available at \url{https://backdoorbench.github.io}.