 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Data Augmentation in Knowledge Distillation for Object Detection
Sep 20, 2022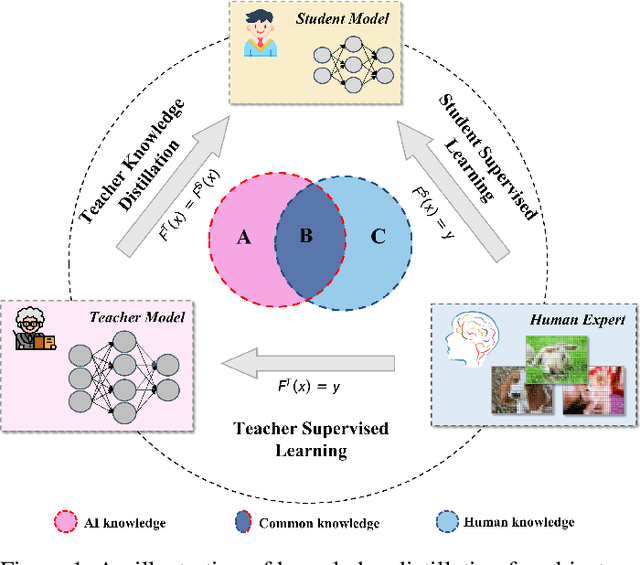
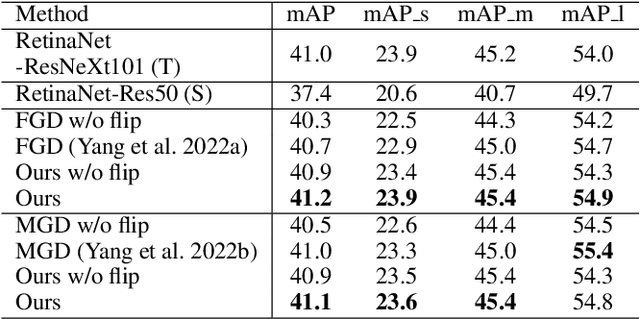
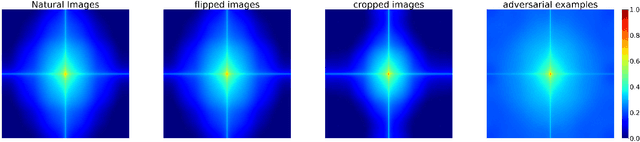

Knowledge distillation (KD) has shown its effectiveness for object detection, where it trains a compact object detector under the supervision of both AI knowledge (teacher detector) and human knowledge (human expert). However, existing studies treat the AI knowledge and human knowledge consistently and adopt a uniform data augmentation strategy during learning, which would lead to the biased learning of multi-scale objects and insufficient learning for the teacher detector causing unsatisfactory distillation performance. To tackle these problems, we propose the sample-specific data augmentation and adversarial feature augmentation. Firstly, to mitigate the impact incurred by multi-scale objects, we propose an adaptive data augmentation based on our observations from the Fourier perspective. Secondly, we propose a feature augmentation method based on adversarial examples for better mimicking AI knowledge to make up for the insufficient information mining of the teacher detector. Furthermore, our proposed method is unified and easily extended to other KD methods. Extensive experiments demonstrate the effectiveness of our framework and improve the performance of state-of-the-art methods in one-stage and two-stage detectors, bringing at most 0.5 mAP gains.
Improving Robust Fairness via Balance Adversarial Training
Sep 15, 2022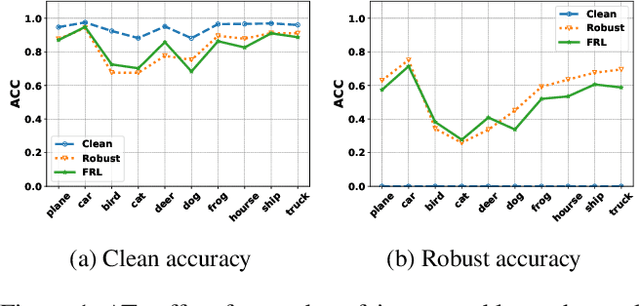
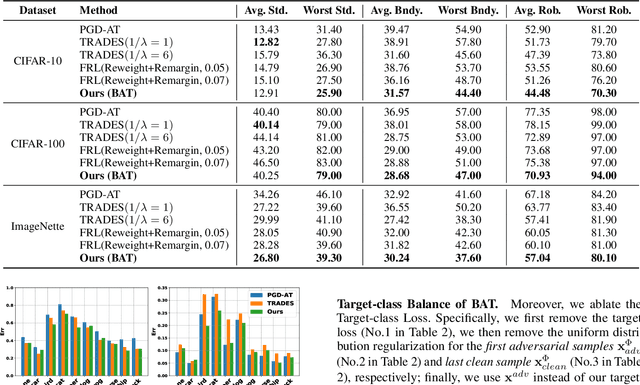
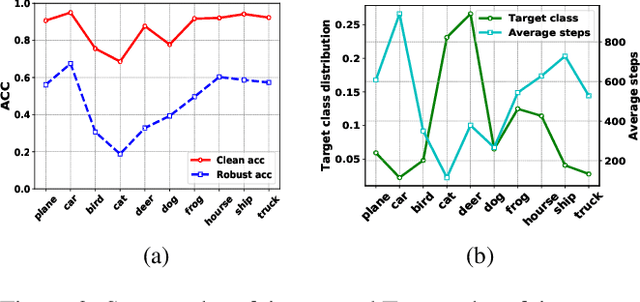

Adversarial training (AT) methods are effective against adversarial attacks, yet they introduce severe disparity of accuracy and robustness between different classes, known as the robust fairness problem. Previously proposed Fair Robust Learning (FRL) adaptively reweights different classes to improve fairness. However, the performance of the better-performed classes decreases, leading to a strong performance drop. In this paper, we observed two unfair phenomena during adversarial training: different difficulties in generating adversarial examples from each class (source-class fairness) and disparate target class tendencies when generating adversarial examples (target-class fairness). From the observations, we propose Balance Adversarial Training (BAT) to address the robust fairness problem. Regarding source-class fairness, we adjust the attack strength and difficulties of each class to generate samples near the decision boundary for easier and fairer model learning; considering target-class fairness, by introducing a uniform distribution constraint, we encourage the adversarial example generation process for each class with a fair tendency. Extensive experiments conducted on multiple datasets (CIFAR-10, CIFAR-100, and ImageNette) demonstrate that our method can significantly outperform other baselines in mitigating the robust fairness problem (+5-10\% on the worst class accuracy)
Exposing Fine-grained Adversarial Vulnerability of Face Anti-spoofing Models
May 30, 2022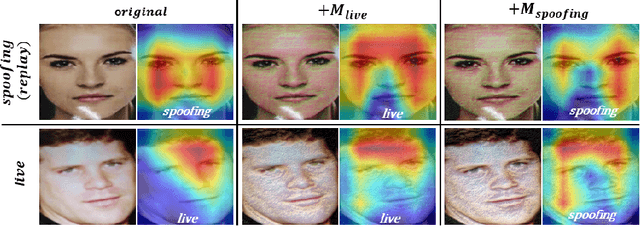
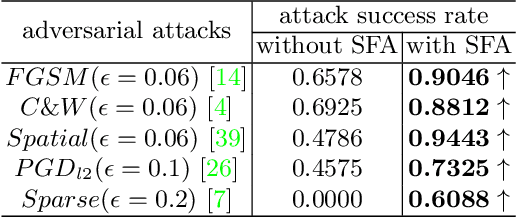
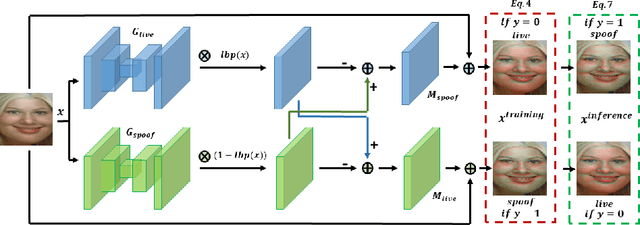
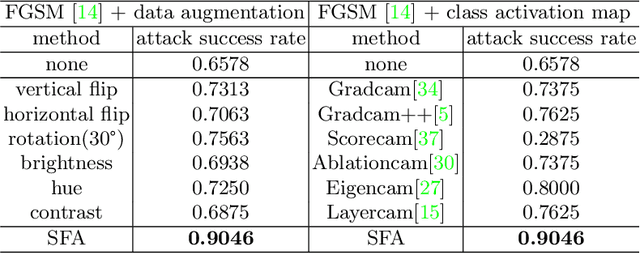
Adversarial attacks seriously threaten the high accuracy of face anti-spoofing models. Little adversarial noise can perturb their classification of live and spoofing. The existing adversarial attacks fail to figure out which part of the target face anti-spoofing model is vulnerable, making adversarial analysis tricky. So we propose fine-grained attacks for exposing adversarial vulnerability of face anti-spoofing models. Firstly, we propose Semantic Feature Augmentation (SFA) module, which makes adversarial noise semantic-aware to live and spoofing features. SFA considers the contrastive classes of data and texture bias of models in the context of face anti-spoofing, increasing the attack success rate by nearly 40% on average. Secondly, we generate fine-grained adversarial examples based on SFA and the multitask network with auxiliary information. We evaluate three annotations (facial attributes, spoofing types and illumination) and two geometric maps (depth and reflection), on four backbone networks (VGG, Resnet, Densenet and Swin Transformer). We find that facial attributes annotation and state-of-art networks fail to guarantee that models are robust to adversarial attacks. Such adversarial attacks can be generalized to more auxiliary information and backbone networks, to help our community handle the trade-off between accuracy and adversarial robustness.