 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDM-ARS: A Domain-Specific Multi-Agent System for Automated Educational Data Mining Research
Mar 18, 2026In this technical report, we present the Educational Data Mining Automated Research System (EDM-ARS), a domain-specific multi-agent pipeline that automates end-to-end educational data mining (EDM) research. We conceptualize EDM-ARS as a general framework for domain-aware automated research pipelines, where educational expertise is embedded into each stage of the research lifecycle. As a first instantiation of this framework, we focus on predictive modeling tasks. Within this scope, EDM-ARS orchestrates five specialized LLM-powered agents (ProblemFormulator, DataEngineer, Analyst, Critic, and Writer) through a state-machine coordinator that supports revision loops, checkpoint-based recovery, and sandboxed code execution. Given a research prompt and a dataset, EDM-ARS produces a complete LaTeX manuscript with real Semantic Scholar citations, validated machine learning analyses, and automated methodological peer review. We also provide a detailed description of the system architecture, the three-tier data registry design that encodes educational domain expertise, the specification of each agent, the inter-agent communication protocol, and mechanisms for error-handling and self-correction. Finally, we discuss current limitations, including single-dataset scope and formulaic paper output, and outline a phased roadmap toward causal inference, transfer learning, psychometric, and multi-dataset generalization. EDM-ARS is released as an open-source project to support the educational research community.
PRIME: A Process-Outcome Alignment Benchmark for Verifiable Reasoning in Mathematics and Engineering
Feb 12, 2026While model-based verifiers are essential for scaling Reinforcement Learning with Verifiable Rewards (RLVR), current outcome-centric verification paradigms primarily focus on the consistency between the final result and the ground truth, often neglecting potential errors in the derivation process. This leads to assigning positive rewards to correct answers produced from incorrect derivations. To bridge this gap, we introduce PRIME, a benchmark for evaluating verifiers on Process-Outcome Alignment verification in Mathematics and Engineering. Curated from a comprehensive collection of college-level STEM problems, PRIME comprises 2,530 high-difficulty samples through a consistency-based filtering pipeline. Through extensive evaluation, we find that current verifiers frequently fail to detect derivation flaws. Furthermore, we propose a process-aware RLVR training paradigm utilizing verifiers selected via PRIME. This approach substantially outperforms the outcome-only verification baseline, achieving absolute performance gains of 8.29%, 9.12%, and 7.31% on AIME24, AIME25, and Beyond-AIME, respectively, for the Qwen3-14B-Base model. Finally, we demonstrate a strong linear correlation ($R^2 > 0.92$) between verifier accuracy on PRIME and RLVR training effectiveness, validating PRIME as a reliable predictor for verifier selection.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
R-Align: Enhancing Generative Reward Models through Rationale-Centric Meta-Judging
Feb 06, 2026Reinforcement Learning from Human Feedback (RLHF) remains indispensable for aligning large language models (LLMs) in subjective domains. To enhance robustness, recent work shifts toward Generative Reward Models (GenRMs) that generate rationales before predicting preferences. Yet in GenRM training and evaluation, practice remains outcome-label-only, leaving reasoning quality unchecked. We show that reasoning fidelity-the consistency between a GenRM's preference decision and reference decision rationales-is highly predictive of downstream RLHF outcomes, beyond standard label accuracy. Specifically, we repurpose existing reward-model benchmarks to compute Spurious Correctness (S-Corr)-the fraction of label-correct decisions with rationales misaligned with golden judgments. Our empirical evaluation reveals substantial S-Corr even for competitive GenRMs, and higher S-Corr is associated with policy degeneration under optimization. To improve fidelity, we propose Rationale-Centric Alignment, R-Align, which augments training with gold judgments and explicitly supervises rationale alignment. R-Align reduces S-Corr on RM benchmarks and yields consistent gains in actor performance across STEM, coding, instruction following, and general tasks.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
Reward Shaping to Mitigate Reward Hacking in RLHF
Feb 26, 2025Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human values. However, RLHF is susceptible to reward hacking, where the agent exploits flaws in the reward function rather than learning the intended behavior, thus degrading alignment. While reward shaping helps stabilize RLHF and partially mitigate reward hacking, a systematic investigation into shaping techniques and their underlying principles remains lacking. To bridge this gap, we present a comprehensive study of the prevalent reward shaping methods. Our analysis suggests three key design principles: (1) RL reward is ideally bounded, (2) RL benefits from rapid initial growth followed by gradual convergence, and (3) RL reward is best formulated as a function of centered reward. Guided by these insights, we propose Preference As Reward (PAR), a novel approach that leverages the latent preferences embedded within the reward model itself as the signal for reinforcement learning. We evaluated PAR on two base models, Gemma2-2B and Llama3-8B, using two datasets, Ultrafeedback-Binarized and HH-RLHF. Experimental results demonstrate PAR's superior performance over other reward shaping methods. On the AlpacaEval 2.0 benchmark, PAR achieves a win rate at least 5 percentage points higher than competing approaches. Furthermore, PAR exhibits remarkable data efficiency, requiring only a single reference reward for optimal performance, and maintains robustness against reward hacking even after two full epochs of training. Code is available at https://github.com/PorUna-byte/PAR.
Improving Robust Fairness via Balance Adversarial Training
Sep 15, 2022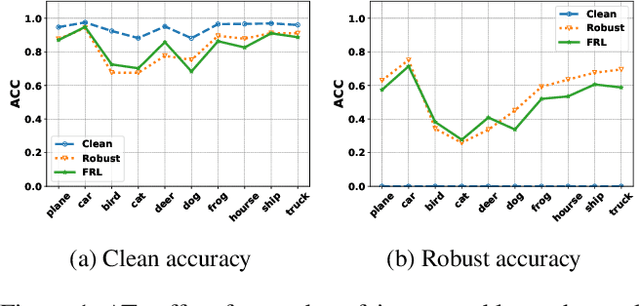
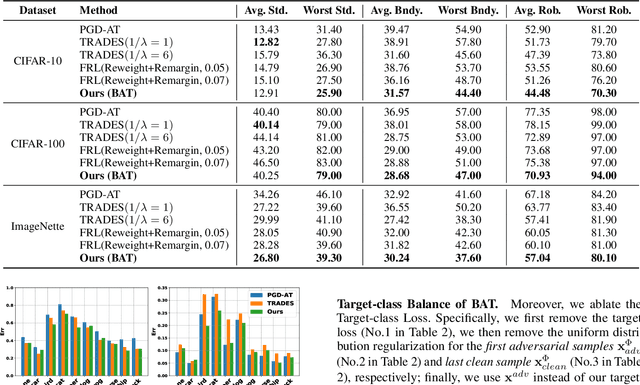
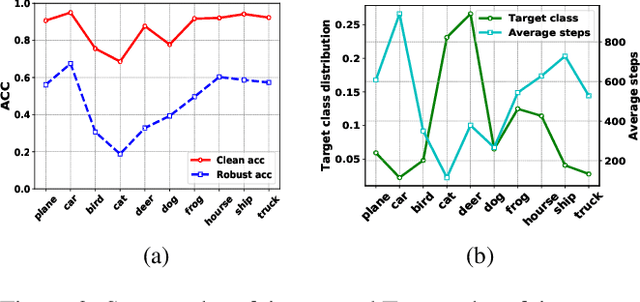

Adversarial training (AT) methods are effective against adversarial attacks, yet they introduce severe disparity of accuracy and robustness between different classes, known as the robust fairness problem. Previously proposed Fair Robust Learning (FRL) adaptively reweights different classes to improve fairness. However, the performance of the better-performed classes decreases, leading to a strong performance drop. In this paper, we observed two unfair phenomena during adversarial training: different difficulties in generating adversarial examples from each class (source-class fairness) and disparate target class tendencies when generating adversarial examples (target-class fairness). From the observations, we propose Balance Adversarial Training (BAT) to address the robust fairness problem. Regarding source-class fairness, we adjust the attack strength and difficulties of each class to generate samples near the decision boundary for easier and fairer model learning; considering target-class fairness, by introducing a uniform distribution constraint, we encourage the adversarial example generation process for each class with a fair tendency. Extensive experiments conducted on multiple datasets (CIFAR-10, CIFAR-100, and ImageNette) demonstrate that our method can significantly outperform other baselines in mitigating the robust fairness problem (+5-10\% on the worst class accuracy)
Automated Discovery of Adaptive Attacks on Adversarial Defenses
Feb 27, 2021
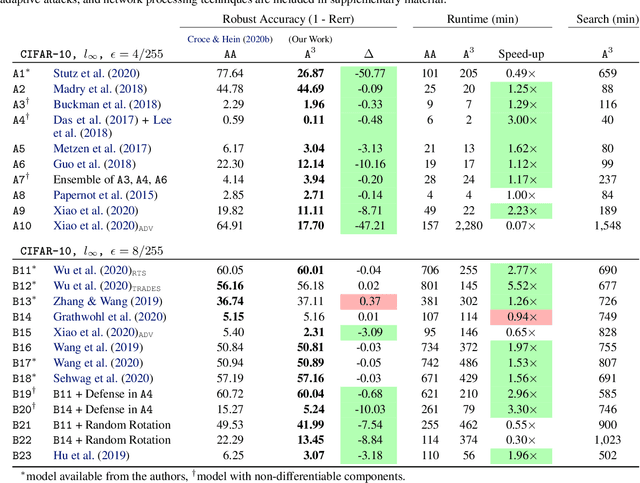
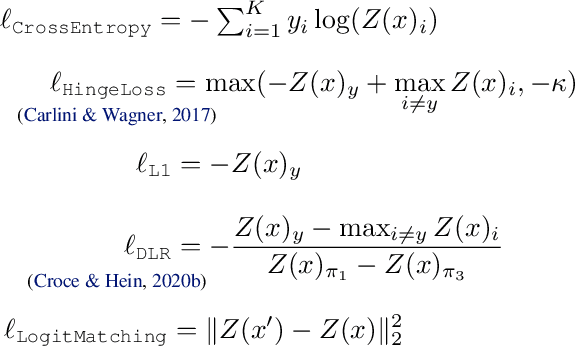
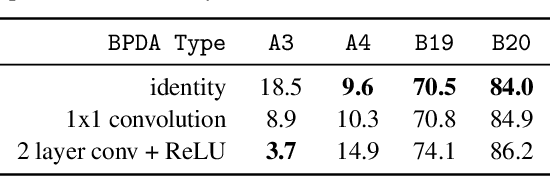
Reliable evaluation of adversarial defenses is a challenging task, currently limited to an expert who manually crafts attacks that exploit the defense's inner workings, or to approaches based on ensemble of fixed attacks, none of which may be effective for the specific defense at hand. Our key observation is that custom attacks are composed from a set of reusable building blocks, such as fine-tuning relevant attack parameters, network transformations, and custom loss functions. Based on this observation, we present an extensible framework that defines a search space over these reusable building blocks and automatically discovers an effective attack on a given model with an unknown defense by searching over suitable combinations of these blocks. We evaluated our framework on 23 adversarial defenses and showed it outperforms AutoAttack, the current state-of-the-art tool for reliable evaluation of adversarial defenses: our discovered attacks are either stronger, producing 3.0%-50.8% additional adversarial examples (10 cases), or are typically 2x faster while enjoying similar adversarial robustness (13 cases).
Deep Learning for Post-Processing Ensemble Weather Forecasts
May 18, 2020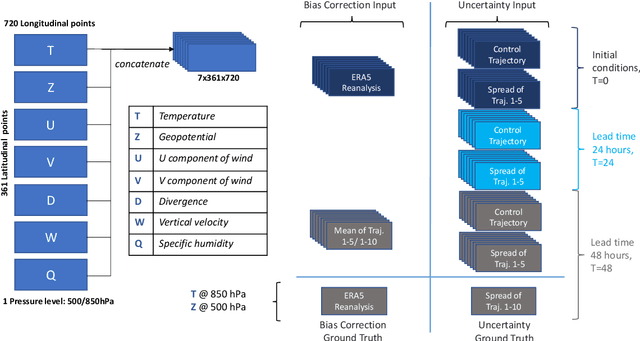

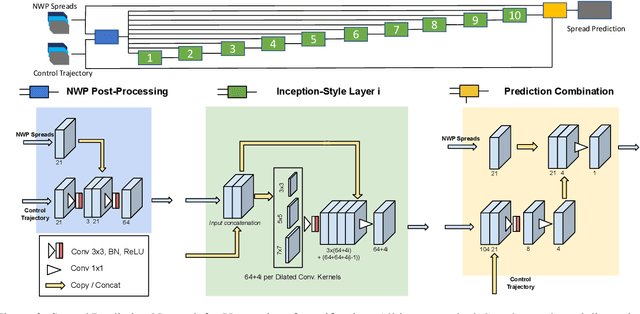

Quantifying uncertainty in weather forecasts typically employs ensemble prediction systems, which consist of many perturbed trajectories run in parallel. These systems are associated with a high computational cost and often include statistical post-processing steps to inexpensively improve their raw prediction qualities. We propose a mixed prediction and post-processing model based on a subset of the original trajectories. In the model, we implement methods from deep learning to account for non-linear relationships that are not captured by current numerical models or other post-processing methods. Applied to global data, our mixed models achieve a relative improvement of the ensemble forecast skill of over 13%. We demonstrate that this is especially the case for extreme weather events on selected case studies, where we see an improvement in predictions by up to 26%. In addition, by using only half the trajectories, the computational costs of ensemble prediction systems can potentially be reduced, allowing weather forecasting pipelines to run higher resolution trajectories, and resulting in even more accurate raw ensemble forecasts.