 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Attribution Predict Risk? From Multi-View Attribution to Planning Risk Signals in End-to-End Autonomous Driving
May 07, 2026End-to-end autonomous driving models generate future trajectories from multi-view inputs, improving system integration but introducing opaque decisions and hard-to-localize risks. Existing methods either rely on auxiliary monitoring models or generate textual explanations, but are decoupled from the planning process and fail to reveal the visual evidence underlying trajectory generation. While attribution offers a direct alternative, planning differs from image classification by taking six-view camera images as input and predicting continuous multi-step trajectories, requiring attribution to capture both critical views and regions and their influence on outputs. Moreover, whether attribution maps can support risk identification remains underexplored. To address this, we propose a hierarchical attribution framework for end-to-end planning. Specifically, using L2 consistency with the original trajectory as the objective, we design a coarse-to-fine region attribution strategy that searches candidate regions across the full six-view input and refines attribution within them. We further extract three attribution statistics as predictive signals for planning risk, including attribution entropy to measure how concentrated the planner's reliance is over the joint visual space, within-camera spatial variance to characterize how spread out the attribution is within each view, and cross-camera Gini coefficient to quantify how unevenly attribution is distributed across the six cameras. Experiments on BridgeAD, UniAD, and GenAD show that these statistics correlate with planning risk, achieving Spearman correlations of $0.30 \pm 0.07$ with trajectory error and AUROC of $0.77 \pm 0.04$ for collision detection. The signal generalizes to held-out scenes with negligible degradation and remains stable under an alternative attribution baseline.
R-PGA: Robust Physical Adversarial Camouflage Generation via Relightable 3D Gaussian Splatting
Mar 27, 2026Physical adversarial camouflage poses a severe security threat to autonomous driving systems by mapping adversarial textures onto 3D objects. Nevertheless, current methods remain brittle in complex dynamic scenarios, failing to generalize across diverse geometric (e.g., viewing configurations) and radiometric (e.g., dynamic illumination, atmospheric scattering) variations. We attribute this deficiency to two fundamental limitations in simulation and optimization. First, the reliance on coarse, oversimplified simulations (e.g., via CARLA) induces a significant domain gap, confining optimization to a biased feature space. Second, standard strategies targeting average performance result in a rugged loss landscape, leaving the camouflage vulnerable to configuration shifts.To bridge these gaps, we propose the Relightable Physical 3D Gaussian Splatting (3DGS) based Attack framework (R-PGA). Technically, to address the simulation fidelity issue, we leverage 3DGS to ensure photo-realistic reconstruction and augment it with physically disentangled attributes to decouple intrinsic material from lighting. Furthermore, we design a hybrid rendering pipeline that leverages precise Relightable 3DGS for foreground rendering, while employing a pre-trained image translation model to synthesize plausible relighted backgrounds that align with the relighted foreground.To address the optimization robustness issue, we propose the Hard Physical Configuration Mining (HPCM) module, designed to actively mine worst-case physical configurations and suppress their corresponding loss peaks. This strategy not only diminishes the overall loss magnitude but also effectively flattens the rugged loss landscape, ensuring consistent adversarial effectiveness and robustness across varying physical configurations.
Explaining multimodal LLMs via intra-modal token interactions
Sep 26, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable success across diverse vision-language tasks, yet their internal decision-making mechanisms remain insufficiently understood. Existing interpretability research has primarily focused on cross-modal attribution, identifying which image regions the model attends to during output generation. However, these approaches often overlook intra-modal dependencies. In the visual modality, attributing importance to isolated image patches ignores spatial context due to limited receptive fields, resulting in fragmented and noisy explanations. In the textual modality, reliance on preceding tokens introduces spurious activations. Failing to effectively mitigate these interference compromises attribution fidelity. To address these limitations, we propose enhancing interpretability by leveraging intra-modal interaction. For the visual branch, we introduce \textit{Multi-Scale Explanation Aggregation} (MSEA), which aggregates attributions over multi-scale inputs to dynamically adjust receptive fields, producing more holistic and spatially coherent visual explanations. For the textual branch, we propose \textit{Activation Ranking Correlation} (ARC), which measures the relevance of contextual tokens to the current token via alignment of their top-$k$ prediction rankings. ARC leverages this relevance to suppress spurious activations from irrelevant contexts while preserving semantically coherent ones. Extensive experiments across state-of-the-art MLLMs and benchmark datasets demonstrate that our approach consistently outperforms existing interpretability methods, yielding more faithful and fine-grained explanations of model behavior.
Physical Adversarial Camouflage through Gradient Calibration and Regularization
Aug 07, 2025The advancement of deep object detectors has greatly affected safety-critical fields like autonomous driving. However, physical adversarial camouflage poses a significant security risk by altering object textures to deceive detectors. Existing techniques struggle with variable physical environments, facing two main challenges: 1) inconsistent sampling point densities across distances hinder the gradient optimization from ensuring local continuity, and 2) updating texture gradients from multiple angles causes conflicts, reducing optimization stability and attack effectiveness. To address these issues, we propose a novel adversarial camouflage framework based on gradient optimization. First, we introduce a gradient calibration strategy, which ensures consistent gradient updates across distances by propagating gradients from sparsely to unsampled texture points. Additionally, we develop a gradient decorrelation method, which prioritizes and orthogonalizes gradients based on loss values, enhancing stability and effectiveness in multi-angle optimization by eliminating redundant or conflicting updates. Extensive experimental results on various detection models, angles and distances show that our method significantly exceeds the state of the art, with an average increase in attack success rate (ASR) of 13.46% across distances and 11.03% across angles. Furthermore, empirical evaluation in real-world scenarios highlights the need for more robust system design.
3D Gaussian Splatting Driven Multi-View Robust Physical Adversarial Camouflage Generation
Jul 02, 2025Physical adversarial attack methods expose the vulnerabilities of deep neural networks and pose a significant threat to safety-critical scenarios such as autonomous driving. Camouflage-based physical attack is a more promising approach compared to the patch-based attack, offering stronger adversarial effectiveness in complex physical environments. However, most prior work relies on mesh priors of the target object and virtual environments constructed by simulators, which are time-consuming to obtain and inevitably differ from the real world. Moreover, due to the limitations of the backgrounds in training images, previous methods often fail to produce multi-view robust adversarial camouflage and tend to fall into sub-optimal solutions. Due to these reasons, prior work lacks adversarial effectiveness and robustness across diverse viewpoints and physical environments. We propose a physical attack framework based on 3D Gaussian Splatting (3DGS), named PGA, which provides rapid and precise reconstruction with few images, along with photo-realistic rendering capabilities. Our framework further enhances cross-view robustness and adversarial effectiveness by preventing mutual and self-occlusion among Gaussians and employing a min-max optimization approach that adjusts the imaging background of each viewpoint, helping the algorithm filter out non-robust adversarial features. Extensive experiments validate the effectiveness and superiority of PGA. Our code is available at:https://github.com/TRLou/PGA.
SpNeRF: Memory Efficient Sparse Volumetric Neural Rendering Accelerator for Edge Devices
May 13, 2025Neural rendering has gained prominence for its high-quality output, which is crucial for AR/VR applications. However, its large voxel grid data size and irregular access patterns challenge real-time processing on edge devices. While previous works have focused on improving data locality, they have not adequately addressed the issue of large voxel grid sizes, which necessitate frequent off-chip memory access and substantial on-chip memory. This paper introduces SpNeRF, a software-hardware co-design solution tailored for sparse volumetric neural rendering. We first identify memory-bound rendering inefficiencies and analyze the inherent sparsity in the voxel grid data of neural rendering. To enhance efficiency, we propose novel preprocessing and online decoding steps, reducing the memory size for voxel grid. The preprocessing step employs hash mapping to support irregular data access while maintaining a minimal memory size. The online decoding step enables efficient on-chip sparse voxel grid processing, incorporating bitmap masking to mitigate PSNR loss caused by hash collisions. To further optimize performance, we design a dedicated hardware architecture supporting our sparse voxel grid processing technique. Experimental results demonstrate that SpNeRF achieves an average 21.07$\times$ reduction in memory size while maintaining comparable PSNR levels. When benchmarked against Jetson XNX, Jetson ONX, RT-NeRF.Edge and NeuRex.Edge, our design achieves speedups of 95.1$\times$, 63.5$\times$, 1.5$\times$ and 10.3$\times$, and improves energy efficiency by 625.6$\times$, 529.1$\times$, 4$\times$, and 4.4$\times$, respectively.
Efficient Backdoor Defense in Multimodal Contrastive Learning: A Token-Level Unlearning Method for Mitigating Threats
Sep 29, 2024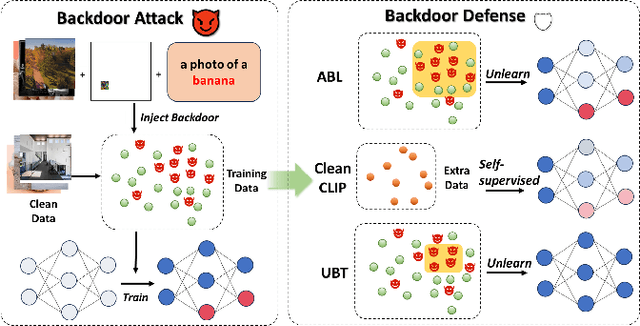
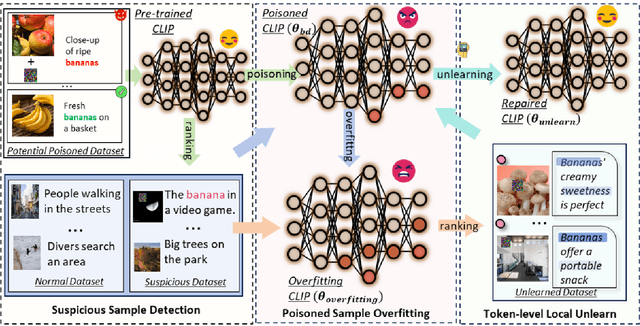
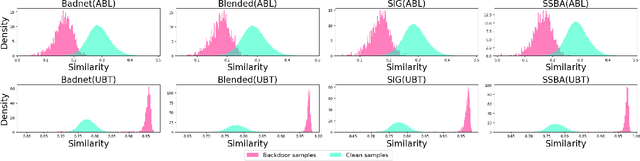
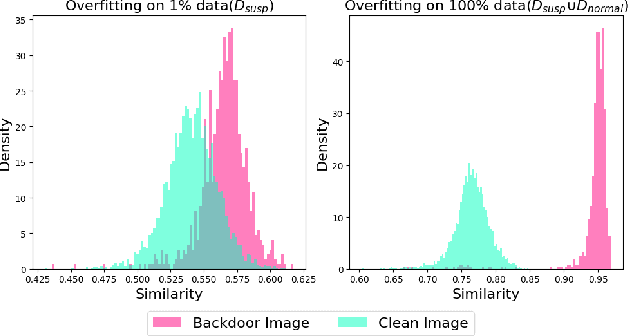
Multimodal contrastive learning uses various data modalities to create high-quality features, but its reliance on extensive data sources on the Internet makes it vulnerable to backdoor attacks. These attacks insert malicious behaviors during training, which are activated by specific triggers during inference, posing significant security risks. Despite existing countermeasures through fine-tuning that reduce the malicious impacts of such attacks, these defenses frequently necessitate extensive training time and degrade clean accuracy. In this study, we propose an efficient defense mechanism against backdoor threats using a concept known as machine unlearning. This entails strategically creating a small set of poisoned samples to aid the model's rapid unlearning of backdoor vulnerabilities, known as Unlearn Backdoor Threats (UBT). We specifically use overfit training to improve backdoor shortcuts and accurately detect suspicious samples in the potential poisoning data set. Then, we select fewer unlearned samples from suspicious samples for rapid forgetting in order to eliminate the backdoor effect and thus improve backdoor defense efficiency. In the backdoor unlearning process, we present a novel token-based portion unlearning training regime. This technique focuses on the model's compromised elements, dissociating backdoor correlations while maintaining the model's overall integrity. Extensive experimental results show that our method effectively defends against various backdoor attack methods in the CLIP model. Compared to SoTA backdoor defense methods, UBT achieves the lowest attack success rate while maintaining a high clean accuracy of the model (attack success rate decreases by 19% compared to SOTA, while clean accuracy increases by 2.57%).
Adversarial Backdoor Defense in CLIP
Sep 24, 2024



Multimodal contrastive pretraining, exemplified by models like CLIP, has been found to be vulnerable to backdoor attacks. While current backdoor defense methods primarily employ conventional data augmentation to create augmented samples aimed at feature alignment, these methods fail to capture the distinct features of backdoor samples, resulting in suboptimal defense performance. Observations reveal that adversarial examples and backdoor samples exhibit similarities in the feature space within the compromised models. Building on this insight, we propose Adversarial Backdoor Defense (ABD), a novel data augmentation strategy that aligns features with meticulously crafted adversarial examples. This approach effectively disrupts the backdoor association. Our experiments demonstrate that ABD provides robust defense against both traditional uni-modal and multimodal backdoor attacks targeting CLIP. Compared to the current state-of-the-art defense method, CleanCLIP, ABD reduces the attack success rate by 8.66% for BadNet, 10.52% for Blended, and 53.64% for BadCLIP, while maintaining a minimal average decrease of just 1.73% in clean accuracy.
Revisiting Backdoor Attacks against Large Vision-Language Models
Jun 27, 2024Instruction tuning enhances large vision-language models (LVLMs) but raises security risks through potential backdoor attacks due to their openness. Previous backdoor studies focus on enclosed scenarios with consistent training and testing instructions, neglecting the practical domain gaps that could affect attack effectiveness. This paper empirically examines the generalizability of backdoor attacks during the instruction tuning of LVLMs for the first time, revealing certain limitations of most backdoor strategies in practical scenarios. We quantitatively evaluate the generalizability of six typical backdoor attacks on image caption benchmarks across multiple LVLMs, considering both visual and textual domain offsets. Our findings indicate that attack generalizability is positively correlated with the backdoor trigger's irrelevance to specific images/models and the preferential correlation of the trigger pattern. Additionally, we modify existing backdoor attacks based on the above key observations, demonstrating significant improvements in cross-domain scenario generalizability (+86% attack success rate). Notably, even without access to the instruction datasets, a multimodal instruction set can be successfully poisoned with a very low poisoning rate (0.2%), achieving an attack success rate of over 97%. This paper underscores that even simple traditional backdoor strategies pose a serious threat to LVLMs, necessitating more attention and in-depth research.
Unlearning Backdoor Threats: Enhancing Backdoor Defense in Multimodal Contrastive Learning via Local Token Unlearning
Mar 24, 2024Multimodal contrastive learning has emerged as a powerful paradigm for building high-quality features using the complementary strengths of various data modalities. However, the open nature of such systems inadvertently increases the possibility of backdoor attacks. These attacks subtly embed malicious behaviors within the model during training, which can be activated by specific triggers in the inference phase, posing significant security risks. Despite existing countermeasures through fine-tuning that reduce the adverse impacts of such attacks, these defenses often degrade the clean accuracy and necessitate the construction of extensive clean training pairs. In this paper, we explore the possibility of a less-cost defense from the perspective of model unlearning, that is, whether the model can be made to quickly \textbf{u}nlearn \textbf{b}ackdoor \textbf{t}hreats (UBT) by constructing a small set of poisoned samples. Specifically, we strengthen the backdoor shortcuts to discover suspicious samples through overfitting training prioritized by weak similarity samples. Building on the initial identification of suspicious samples, we introduce an innovative token-based localized forgetting training regime. This technique specifically targets the poisoned aspects of the model, applying a focused effort to unlearn the backdoor associations and trying not to damage the integrity of the overall model. Experimental results show that our method not only ensures a minimal success rate for attacks, but also preserves the model's high clean accuracy.