 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Backdoor Defense in CLIP
Sep 24, 2024



Multimodal contrastive pretraining, exemplified by models like CLIP, has been found to be vulnerable to backdoor attacks. While current backdoor defense methods primarily employ conventional data augmentation to create augmented samples aimed at feature alignment, these methods fail to capture the distinct features of backdoor samples, resulting in suboptimal defense performance. Observations reveal that adversarial examples and backdoor samples exhibit similarities in the feature space within the compromised models. Building on this insight, we propose Adversarial Backdoor Defense (ABD), a novel data augmentation strategy that aligns features with meticulously crafted adversarial examples. This approach effectively disrupts the backdoor association. Our experiments demonstrate that ABD provides robust defense against both traditional uni-modal and multimodal backdoor attacks targeting CLIP. Compared to the current state-of-the-art defense method, CleanCLIP, ABD reduces the attack success rate by 8.66% for BadNet, 10.52% for Blended, and 53.64% for BadCLIP, while maintaining a minimal average decrease of just 1.73% in clean accuracy.
Poisoned Forgery Face: Towards Backdoor Attacks on Face Forgery Detection
Feb 18, 2024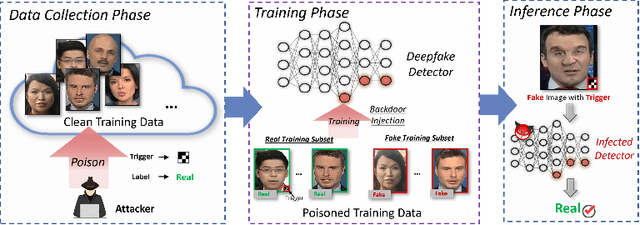
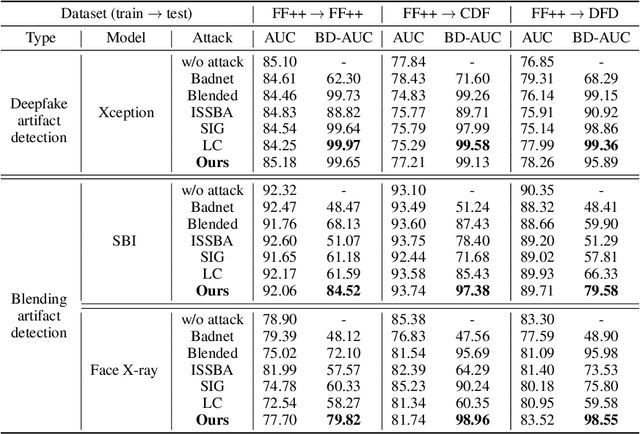
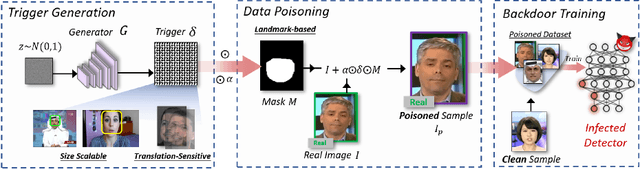

The proliferation of face forgery techniques has raised significant concerns within society, thereby motivating the development of face forgery detection methods. These methods aim to distinguish forged faces from genuine ones and have proven effective in practical applications. However, this paper introduces a novel and previously unrecognized threat in face forgery detection scenarios caused by backdoor attack. By embedding backdoors into models and incorporating specific trigger patterns into the input, attackers can deceive detectors into producing erroneous predictions for forged faces. To achieve this goal, this paper proposes \emph{Poisoned Forgery Face} framework, which enables clean-label backdoor attacks on face forgery detectors. Our approach involves constructing a scalable trigger generator and utilizing a novel convolving process to generate translation-sensitive trigger patterns. Moreover, we employ a relative embedding method based on landmark-based regions to enhance the stealthiness of the poisoned samples. Consequently, detectors trained on our poisoned samples are embedded with backdoors. Notably, our approach surpasses SoTA backdoor baselines with a significant improvement in attack success rate (+16.39\% BD-AUC) and reduction in visibility (-12.65\% $L_\infty$). Furthermore, our attack exhibits promising performance against backdoor defenses. We anticipate that this paper will draw greater attention to the potential threats posed by backdoor attacks in face forgery detection scenarios. Our codes will be made available at \url{https://github.com/JWLiang007/PFF}