 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadVideo: Stealthy Backdoor Attack against Text-to-Video Generation
Apr 23, 2025Text-to-video (T2V) generative models have rapidly advanced and found widespread applications across fields like entertainment, education, and marketing. However, the adversarial vulnerabilities of these models remain rarely explored. We observe that in T2V generation tasks, the generated videos often contain substantial redundant information not explicitly specified in the text prompts, such as environmental elements, secondary objects, and additional details, providing opportunities for malicious attackers to embed hidden harmful content. Exploiting this inherent redundancy, we introduce BadVideo, the first backdoor attack framework tailored for T2V generation. Our attack focuses on designing target adversarial outputs through two key strategies: (1) Spatio-Temporal Composition, which combines different spatiotemporal features to encode malicious information; (2) Dynamic Element Transformation, which introduces transformations in redundant elements over time to convey malicious information. Based on these strategies, the attacker's malicious target seamlessly integrates with the user's textual instructions, providing high stealthiness. Moreover, by exploiting the temporal dimension of videos, our attack successfully evades traditional content moderation systems that primarily analyze spatial information within individual frames. Extensive experiments demonstrate that BadVideo achieves high attack success rates while preserving original semantics and maintaining excellent performance on clean inputs. Overall, our work reveals the adversarial vulnerability of T2V models, calling attention to potential risks and misuse. Our project page is at https://wrt2000.github.io/BadVideo2025/.
Class-Conditional Neural Polarizer: A Lightweight and Effective Backdoor Defense by Purifying Poisoned Features
Feb 23, 2025Recent studies have highlighted the vulnerability of deep neural networks to backdoor attacks, where models are manipulated to rely on embedded triggers within poisoned samples, despite the presence of both benign and trigger information. While several defense methods have been proposed, they often struggle to balance backdoor mitigation with maintaining benign performance.In this work, inspired by the concept of optical polarizer-which allows light waves of specific polarizations to pass while filtering others-we propose a lightweight backdoor defense approach, NPD. This method integrates a neural polarizer (NP) as an intermediate layer within the compromised model, implemented as a lightweight linear transformation optimized via bi-level optimization. The learnable NP filters trigger information from poisoned samples while preserving benign content. Despite its effectiveness, we identify through empirical studies that NPD's performance degrades when the target labels (required for purification) are inaccurately estimated. To address this limitation while harnessing the potential of targeted adversarial mitigation, we propose class-conditional neural polarizer-based defense (CNPD). The key innovation is a fusion module that integrates the backdoored model's predicted label with the features to be purified. This architecture inherently mimics targeted adversarial defense mechanisms without requiring label estimation used in NPD. We propose three implementations of CNPD: the first is r-CNPD, which trains a replicated NP layer for each class and, during inference, selects the appropriate NP layer for defense based on the predicted class from the backdoored model. To efficiently handle a large number of classes, two variants are designed: e-CNPD, which embeds class information as additional features, and a-CNPD, which directs network attention using class information.
Reliable Poisoned Sample Detection against Backdoor Attacks Enhanced by Sharpness Aware Minimization
Nov 18, 2024



Backdoor attack has been considered as a serious security threat to deep neural networks (DNNs). Poisoned sample detection (PSD) that aims at filtering out poisoned samples from an untrustworthy training dataset has shown very promising performance for defending against data poisoning based backdoor attacks. However, we observe that the detection performance of many advanced methods is likely to be unstable when facing weak backdoor attacks, such as low poisoning ratio or weak trigger strength. To further verify this observation, we make a statistical investigation among various backdoor attacks and poisoned sample detections, showing a positive correlation between backdoor effect and detection performance. It inspires us to strengthen the backdoor effect to enhance detection performance. Since we cannot achieve that goal via directly manipulating poisoning ratio or trigger strength, we propose to train one model using the Sharpness-Aware Minimization (SAM) algorithm, rather than the vanilla training algorithm. We also provide both empirical and theoretical analysis about how SAM training strengthens the backdoor effect. Then, this SAM trained model can be seamlessly integrated with any off-the-shelf PSD method that extracts discriminative features from the trained model for detection, called SAM-enhanced PSD. Extensive experiments on several benchmark datasets show the reliable detection performance of the proposed method against both weak and strong backdoor attacks, with significant improvements against various attacks ($+34.38\%$ TPR on average), over the conventional PSD methods (i.e., without SAM enhancement). Overall, this work provides new insights about PSD and proposes a novel approach that can complement existing detection methods, which may inspire more in-depth explorations in this field.
Breaking the False Sense of Security in Backdoor Defense through Re-Activation Attack
May 30, 2024



Deep neural networks face persistent challenges in defending against backdoor attacks, leading to an ongoing battle between attacks and defenses. While existing backdoor defense strategies have shown promising performance on reducing attack success rates, can we confidently claim that the backdoor threat has truly been eliminated from the model? To address it, we re-investigate the characteristics of the backdoored models after defense (denoted as defense models). Surprisingly, we find that the original backdoors still exist in defense models derived from existing post-training defense strategies, and the backdoor existence is measured by a novel metric called backdoor existence coefficient. It implies that the backdoors just lie dormant rather than being eliminated. To further verify this finding, we empirically show that these dormant backdoors can be easily re-activated during inference, by manipulating the original trigger with well-designed tiny perturbation using universal adversarial attack. More practically, we extend our backdoor reactivation to black-box scenario, where the defense model can only be queried by the adversary during inference, and develop two effective methods, i.e., query-based and transfer-based backdoor re-activation attacks. The effectiveness of the proposed methods are verified on both image classification and multimodal contrastive learning (i.e., CLIP) tasks. In conclusion, this work uncovers a critical vulnerability that has never been explored in existing defense strategies, emphasizing the urgency of designing more robust and advanced backdoor defense mechanisms in the future.
BackdoorBench: A Comprehensive Benchmark and Analysis of Backdoor Learning
Jan 26, 2024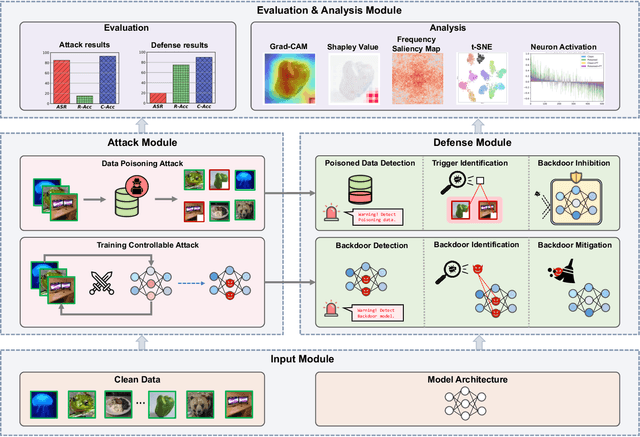
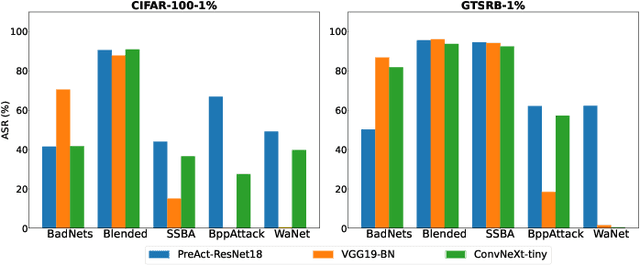
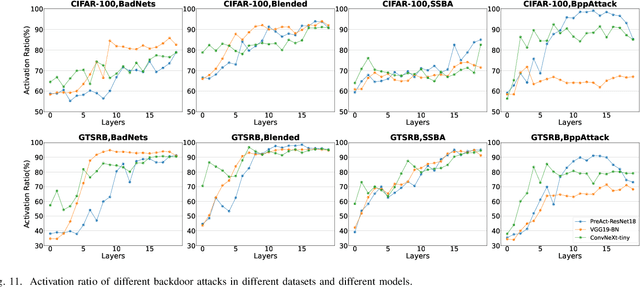

As an emerging and vital topic for studying deep neural networks' vulnerability (DNNs), backdoor learning has attracted increasing interest in recent years, and many seminal backdoor attack and defense algorithms are being developed successively or concurrently, in the status of a rapid arms race. However, mainly due to the diverse settings, and the difficulties of implementation and reproducibility of existing works, there is a lack of a unified and standardized benchmark of backdoor learning, causing unfair comparisons, and unreliable conclusions (e.g., misleading, biased or even false conclusions). Consequently, it is difficult to evaluate the current progress and design the future development roadmap of this literature. To alleviate this dilemma, we build a comprehensive benchmark of backdoor learning called BackdoorBench. Our benchmark makes three valuable contributions to the research community. 1) We provide an integrated implementation of state-of-the-art (SOTA) backdoor learning algorithms (currently including 16 attack and 27 defense algorithms), based on an extensible modular-based codebase. 2) We conduct comprehensive evaluations of 12 attacks against 16 defenses, with 5 poisoning ratios, based on 4 models and 4 datasets, thus 11,492 pairs of evaluations in total. 3) Based on above evaluations, we present abundant analysis from 8 perspectives via 18 useful analysis tools, and provide several inspiring insights about backdoor learning. We hope that our efforts could build a solid foundation of backdoor learning to facilitate researchers to investigate existing algorithms, develop more innovative algorithms, and explore the intrinsic mechanism of backdoor learning. Finally, we have created a user-friendly website at http://backdoorbench.com, which collects all important information of BackdoorBench, including codebase, docs, leaderboard, and model Zoo.
Enhanced Few-Shot Class-Incremental Learning via Ensemble Models
Jan 14, 2024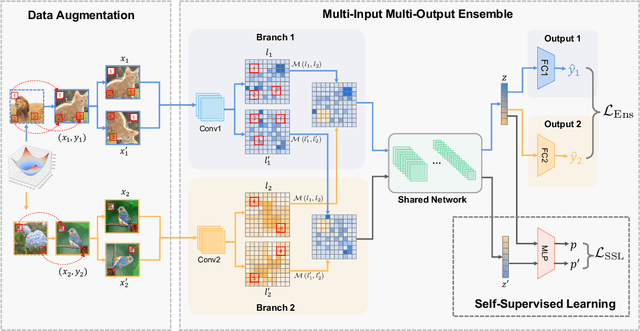
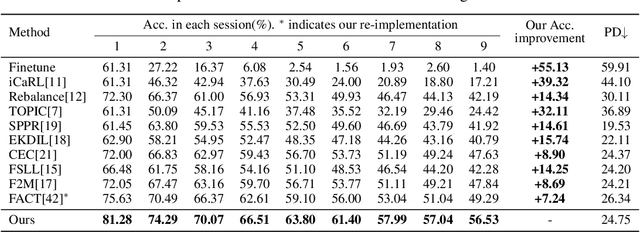
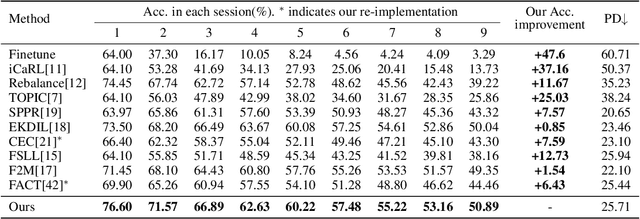
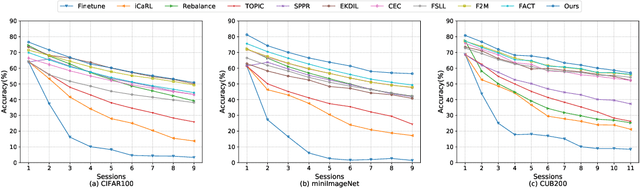
Few-shot class-incremental learning (FSCIL) aims to continually fit new classes with limited training data, while maintaining the performance of previously learned classes. The main challenges are overfitting the rare new training samples and forgetting old classes. While catastrophic forgetting has been extensively studied, the overfitting problem has attracted less attention in FSCIL. To tackle overfitting challenge, we design a new ensemble model framework cooperated with data augmentation to boost generalization. In this way, the enhanced model works as a library storing abundant features to guarantee fast adaptation to downstream tasks. Specifically, the multi-input multi-output ensemble structure is applied with a spatial-aware data augmentation strategy, aiming at diversifying the feature extractor and alleviating overfitting in incremental sessions. Moreover, self-supervised learning is also integrated to further improve the model generalization. Comprehensive experimental results show that the proposed method can indeed mitigate the overfitting problem in FSCIL, and outperform the state-of-the-art methods.
Defenses in Adversarial Machine Learning: A Survey
Dec 13, 2023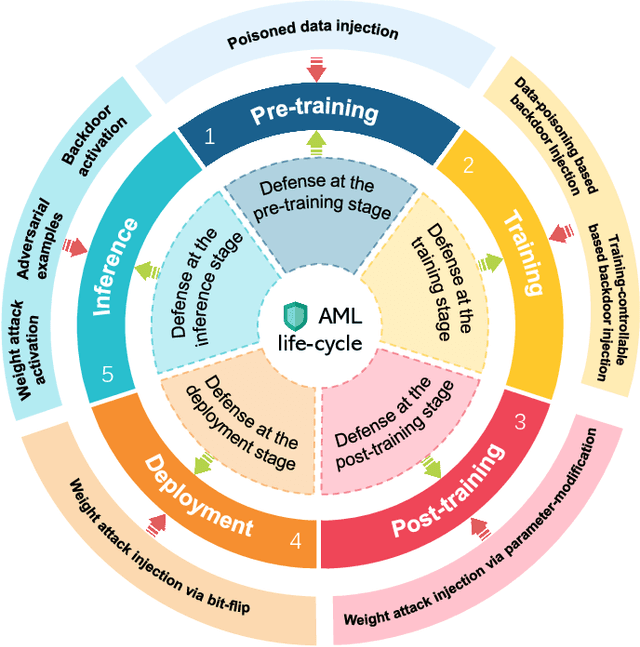
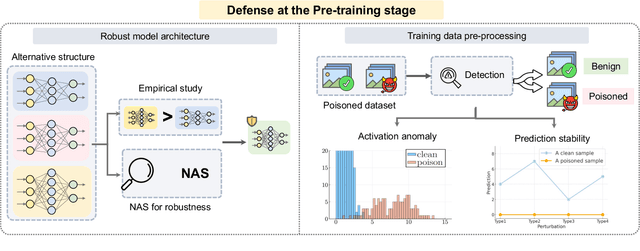
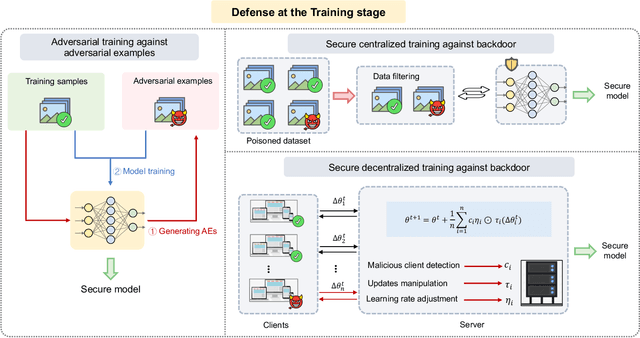
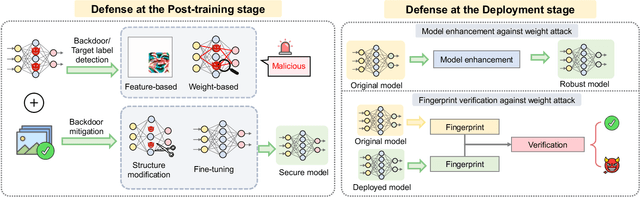
Adversarial phenomenon has been widely observed in machine learning (ML) systems, especially in those using deep neural networks, describing that ML systems may produce inconsistent and incomprehensible predictions with humans at some particular cases. This phenomenon poses a serious security threat to the practical application of ML systems, and several advanced attack paradigms have been developed to explore it, mainly including backdoor attacks, weight attacks, and adversarial examples. For each individual attack paradigm, various defense paradigms have been developed to improve the model robustness against the corresponding attack paradigm. However, due to the independence and diversity of these defense paradigms, it is difficult to examine the overall robustness of an ML system against different kinds of attacks.This survey aims to build a systematic review of all existing defense paradigms from a unified perspective. Specifically, from the life-cycle perspective, we factorize a complete machine learning system into five stages, including pre-training, training, post-training, deployment, and inference stages, respectively. Then, we present a clear taxonomy to categorize and review representative defense methods at each individual stage. The unified perspective and presented taxonomies not only facilitate the analysis of the mechanism of each defense paradigm but also help us to understand connections and differences among different defense paradigms, which may inspire future research to develop more advanced, comprehensive defenses.
BadCLIP: Dual-Embedding Guided Backdoor Attack on Multimodal Contrastive Learning
Nov 20, 2023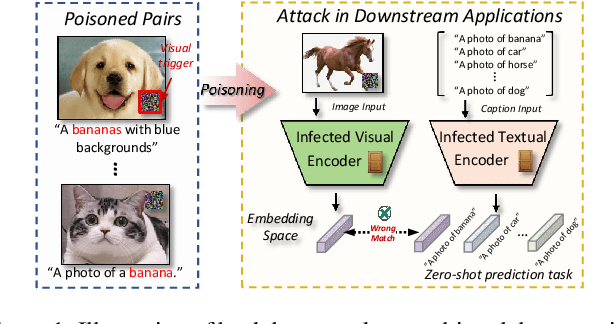



Studying backdoor attacks is valuable for model copyright protection and enhancing defenses. While existing backdoor attacks have successfully infected multimodal contrastive learning models such as CLIP, they can be easily countered by specialized backdoor defenses for MCL models. This paper reveals the threats in this practical scenario that backdoor attacks can remain effective even after defenses and introduces the \emph{\toolns} attack, which is resistant to backdoor detection and model fine-tuning defenses. To achieve this, we draw motivations from the perspective of the Bayesian rule and propose a dual-embedding guided framework for backdoor attacks. Specifically, we ensure that visual trigger patterns approximate the textual target semantics in the embedding space, making it challenging to detect the subtle parameter variations induced by backdoor learning on such natural trigger patterns. Additionally, we optimize the visual trigger patterns to align the poisoned samples with target vision features in order to hinder the backdoor unlearning through clean fine-tuning. Extensive experiments demonstrate that our attack significantly outperforms state-of-the-art baselines (+45.3% ASR) in the presence of SoTA backdoor defenses, rendering these mitigation and detection strategies virtually ineffective. Furthermore, our approach effectively attacks some more rigorous scenarios like downstream tasks. We believe that this paper raises awareness regarding the potential threats associated with the practical application of multimodal contrastive learning and encourages the development of more robust defense mechanisms.
Neural Polarizer: A Lightweight and Effective Backdoor Defense via Purifying Poisoned Features
Jun 29, 2023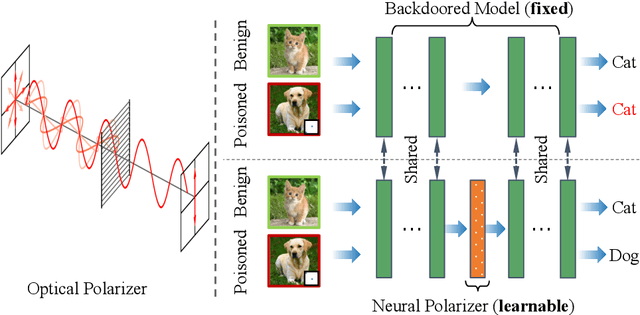
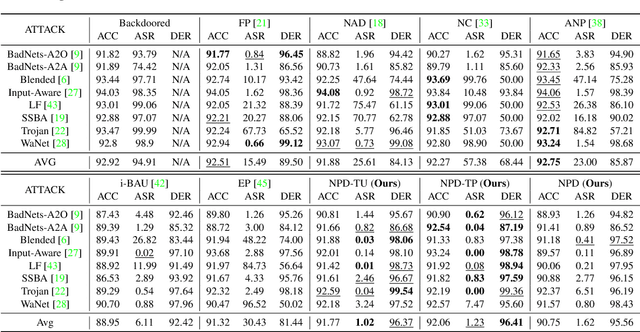
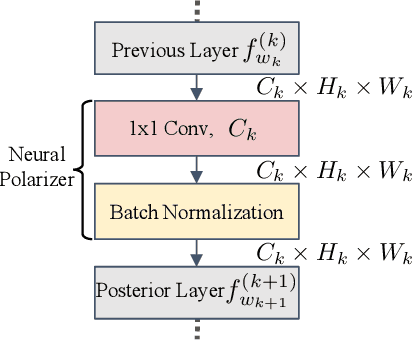
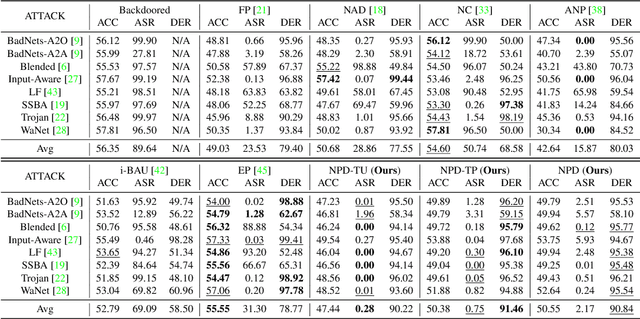
Recent studies have demonstrated the susceptibility of deep neural networks to backdoor attacks. Given a backdoored model, its prediction of a poisoned sample with trigger will be dominated by the trigger information, though trigger information and benign information coexist. Inspired by the mechanism of the optical polarizer that a polarizer could pass light waves with particular polarizations while filtering light waves with other polarizations, we propose a novel backdoor defense method by inserting a learnable neural polarizer into the backdoored model as an intermediate layer, in order to purify the poisoned sample via filtering trigger information while maintaining benign information. The neural polarizer is instantiated as one lightweight linear transformation layer, which is learned through solving a well designed bi-level optimization problem, based on a limited clean dataset. Compared to other fine-tuning-based defense methods which often adjust all parameters of the backdoored model, the proposed method only needs to learn one additional layer, such that it is more efficient and requires less clean data. Extensive experiments demonstrate the effectiveness and efficiency of our method in removing backdoors across various neural network architectures and datasets, especially in the case of very limited clean data.
Enhancing Fine-Tuning Based Backdoor Defense with Sharpness-Aware Minimization
Apr 24, 2023



Backdoor defense, which aims to detect or mitigate the effect of malicious triggers introduced by attackers, is becoming increasingly critical for machine learning security and integrity. Fine-tuning based on benign data is a natural defense to erase the backdoor effect in a backdoored model. However, recent studies show that, given limited benign data, vanilla fine-tuning has poor defense performance. In this work, we provide a deep study of fine-tuning the backdoored model from the neuron perspective and find that backdoorrelated neurons fail to escape the local minimum in the fine-tuning process. Inspired by observing that the backdoorrelated neurons often have larger norms, we propose FTSAM, a novel backdoor defense paradigm that aims to shrink the norms of backdoor-related neurons by incorporating sharpness-aware minimization with fine-tuning. We demonstrate the effectiveness of our method on several benchmark datasets and network architectures, where it achieves state-of-the-art defense performance. Overall, our work provides a promising avenue for improving the robustness of machine learning models against backdoor attacks.