 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmoView: Harmonizing Multi-View Constraints for Identity-Consistent Video Generation
Jun 09, 2026Current identity-consistent video generation methods struggle to preserve appearance fidelity under large viewpoint changes. While introducing multi-view reference input offers a natural solution, progress remains constrained by the lack of effective frameworks for multi-view inputs and the scarcity of multi-view data. We address these challenges by proposing HarmoView, a robust framework for identity-consistent video generation that effectively integrates multi-view cues through three architectural refinements complemented by a staged training curriculum. Specifically, we first introduce Multi-level Feature Injection to anchor identity fidelity; by injecting raw ViT features from frontal references alongside text tokens via cross-attention, MFI provides persistent low-level appearance anchors that complement the high-level identity features within DiT blocks, leading to enhanced identity preservation. Then, we employ learnable proxy tokens to unify heterogeneous reference layouts across single-/multi-view settings while simultaneously resolving the reference-view mismatch problem. Jump-RoPE is further developed for identity-wise feature isolation to reduce identity crosstalk. To activate these structural capabilities while preserving the original generative priors, we propose the Progressive View Curriculum. This four-stage training strategy employs view dropout to facilitate a stable transition from vanilla T2V generation to high-fidelity, identity-persistent spatial reasoning. Furthermore, we construct a large-scale multi-view dataset to address the issue of data scarcity. Extensive evaluation on our multi-view benchmark, comprising 100 manually-curated cases spanning 52 unique identities, demonstrates that HarmoView significantly outperforms open-source baselines and matches leading closed-source engines, achieving state-of-the-art performance in identity-consistent video generation.
Alchemist: Unlocking Efficiency in Text-to-Image Model Training via Meta-Gradient Data Selection
Dec 18, 2025Recent advances in Text-to-Image (T2I) generative models, such as Imagen, Stable Diffusion, and FLUX, have led to remarkable improvements in visual quality. However, their performance is fundamentally limited by the quality of training data. Web-crawled and synthetic image datasets often contain low-quality or redundant samples, which lead to degraded visual fidelity, unstable training, and inefficient computation. Hence, effective data selection is crucial for improving data efficiency. Existing approaches rely on costly manual curation or heuristic scoring based on single-dimensional features in Text-to-Image data filtering. Although meta-learning based method has been explored in LLM, there is no adaptation for image modalities. To this end, we propose **Alchemist**, a meta-gradient-based framework to select a suitable subset from large-scale text-image data pairs. Our approach automatically learns to assess the influence of each sample by iteratively optimizing the model from a data-centric perspective. Alchemist consists of two key stages: data rating and data pruning. We train a lightweight rater to estimate each sample's influence based on gradient information, enhanced with multi-granularity perception. We then use the Shift-Gsampling strategy to select informative subsets for efficient model training. Alchemist is the first automatic, scalable, meta-gradient-based data selection framework for Text-to-Image model training. Experiments on both synthetic and web-crawled datasets demonstrate that Alchemist consistently improves visual quality and downstream performance. Training on an Alchemist-selected 50% of the data can outperform training on the full dataset.
Easier Painting Than Thinking: Can Text-to-Image Models Set the Stage, but Not Direct the Play?
Sep 03, 2025Text-to-image (T2I) generation aims to synthesize images from textual prompts, which jointly specify what must be shown and imply what can be inferred, thereby corresponding to two core capabilities: composition and reasoning. However, with the emerging advances of T2I models in reasoning beyond composition, existing benchmarks reveal clear limitations in providing comprehensive evaluations across and within these capabilities. Meanwhile, these advances also enable models to handle more complex prompts, whereas current benchmarks remain limited to low scene density and simplified one-to-one reasoning. To address these limitations, we propose T2I-CoReBench, a comprehensive and complex benchmark that evaluates both composition and reasoning capabilities of T2I models. To ensure comprehensiveness, we structure composition around scene graph elements (instance, attribute, and relation) and reasoning around the philosophical framework of inference (deductive, inductive, and abductive), formulating a 12-dimensional evaluation taxonomy. To increase complexity, driven by the inherent complexities of real-world scenarios, we curate each prompt with high compositional density for composition and multi-step inference for reasoning. We also pair each prompt with a checklist that specifies individual yes/no questions to assess each intended element independently to facilitate fine-grained and reliable evaluation. In statistics, our benchmark comprises 1,080 challenging prompts and around 13,500 checklist questions. Experiments across 27 current T2I models reveal that their composition capability still remains limited in complex high-density scenarios, while the reasoning capability lags even further behind as a critical bottleneck, with all models struggling to infer implicit elements from prompts. Our project page: https://t2i-corebench.github.io/.
Imbalance in Balance: Online Concept Balancing in Generation Models
Jul 17, 2025In visual generation tasks, the responses and combinations of complex concepts often lack stability and are error-prone, which remains an under-explored area. In this paper, we attempt to explore the causal factors for poor concept responses through elaborately designed experiments. We also design a concept-wise equalization loss function (IMBA loss) to address this issue. Our proposed method is online, eliminating the need for offline dataset processing, and requires minimal code changes. In our newly proposed complex concept benchmark Inert-CompBench and two other public test sets, our method significantly enhances the concept response capability of baseline models and yields highly competitive results with only a few codes.
BadVideo: Stealthy Backdoor Attack against Text-to-Video Generation
Apr 23, 2025Text-to-video (T2V) generative models have rapidly advanced and found widespread applications across fields like entertainment, education, and marketing. However, the adversarial vulnerabilities of these models remain rarely explored. We observe that in T2V generation tasks, the generated videos often contain substantial redundant information not explicitly specified in the text prompts, such as environmental elements, secondary objects, and additional details, providing opportunities for malicious attackers to embed hidden harmful content. Exploiting this inherent redundancy, we introduce BadVideo, the first backdoor attack framework tailored for T2V generation. Our attack focuses on designing target adversarial outputs through two key strategies: (1) Spatio-Temporal Composition, which combines different spatiotemporal features to encode malicious information; (2) Dynamic Element Transformation, which introduces transformations in redundant elements over time to convey malicious information. Based on these strategies, the attacker's malicious target seamlessly integrates with the user's textual instructions, providing high stealthiness. Moreover, by exploiting the temporal dimension of videos, our attack successfully evades traditional content moderation systems that primarily analyze spatial information within individual frames. Extensive experiments demonstrate that BadVideo achieves high attack success rates while preserving original semantics and maintaining excellent performance on clean inputs. Overall, our work reveals the adversarial vulnerability of T2V models, calling attention to potential risks and misuse. Our project page is at https://wrt2000.github.io/BadVideo2025/.
Towards Precise Scaling Laws for Video Diffusion Transformers
Nov 25, 2024



Achieving optimal performance of video diffusion transformers within given data and compute budget is crucial due to their high training costs. This necessitates precisely determining the optimal model size and training hyperparameters before large-scale training. While scaling laws are employed in language models to predict performance, their existence and accurate derivation in visual generation models remain underexplored. In this paper, we systematically analyze scaling laws for video diffusion transformers and confirm their presence. Moreover, we discover that, unlike language models, video diffusion models are more sensitive to learning rate and batch size, two hyperparameters often not precisely modeled. To address this, we propose a new scaling law that predicts optimal hyperparameters for any model size and compute budget. Under these optimal settings, we achieve comparable performance and reduce inference costs by 40.1% compared to conventional scaling methods, within a compute budget of 1e10 TFlops. Furthermore, we establish a more generalized and precise relationship among validation loss, any model size, and compute budget. This enables performance prediction for non-optimal model sizes, which may also be appealed under practical inference cost constraints, achieving a better trade-off.
Koala-36M: A Large-scale Video Dataset Improving Consistency between Fine-grained Conditions and Video Content
Oct 10, 2024As visual generation technologies continue to advance, the scale of video datasets has expanded rapidly, and the quality of these datasets is critical to the performance of video generation models. We argue that temporal splitting, detailed captions, and video quality filtering are three key factors that determine dataset quality. However, existing datasets exhibit various limitations in these areas. To address these challenges, we introduce Koala-36M, a large-scale, high-quality video dataset featuring accurate temporal splitting, detailed captions, and superior video quality. The core of our approach lies in improving the consistency between fine-grained conditions and video content. Specifically, we employ a linear classifier on probability distributions to enhance the accuracy of transition detection, ensuring better temporal consistency. We then provide structured captions for the splitted videos, with an average length of 200 words, to improve text-video alignment. Additionally, we develop a Video Training Suitability Score (VTSS) that integrates multiple sub-metrics, allowing us to filter high-quality videos from the original corpus. Finally, we incorporate several metrics into the training process of the generation model, further refining the fine-grained conditions. Our experiments demonstrate the effectiveness of our data processing pipeline and the quality of the proposed Koala-36M dataset. Our dataset and code will be released at https://koala36m.github.io/.
FGN: Fully Guided Network for Few-Shot Instance Segmentation
Mar 31, 2020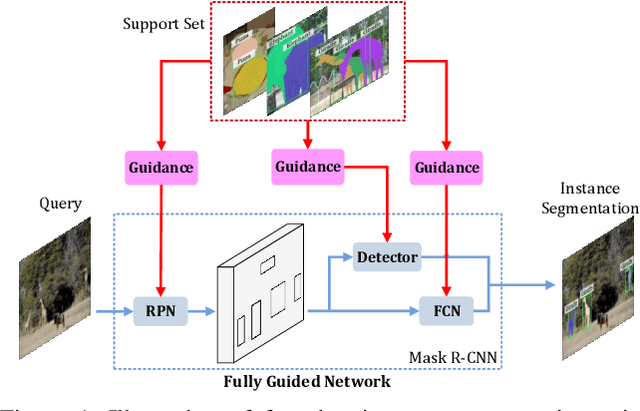

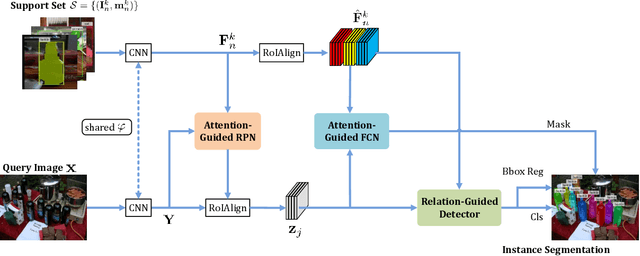
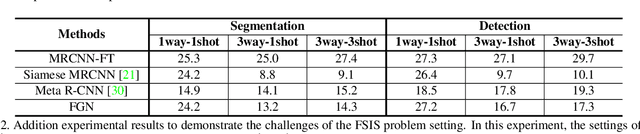
Few-shot instance segmentation (FSIS) conjoins the few-shot learning paradigm with general instance segmentation, which provides a possible way of tackling instance segmentation in the lack of abundant labeled data for training. This paper presents a Fully Guided Network (FGN) for few-shot instance segmentation. FGN perceives FSIS as a guided model where a so-called support set is encoded and utilized to guide the predictions of a base instance segmentation network (i.e., Mask R-CNN), critical to which is the guidance mechanism. In this view, FGN introduces different guidance mechanisms into the various key components in Mask R-CNN, including Attention-Guided RPN, Relation-Guided Detector, and Attention-Guided FCN, in order to make full use of the guidance effect from the support set and adapt better to the inter-class generalization. Experiments on public datasets demonstrate that our proposed FGN can outperform the state-of-the-art methods.