 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciDER: Scientific Data-centric End-to-end Researcher
Mar 02, 2026Automated scientific discovery with large language models is transforming the research lifecycle from ideation to experimentation, yet existing agents struggle to autonomously process raw data collected from scientific experiments. We introduce SciDER, a data-centric end-to-end system that automates the research lifecycle. Unlike traditional frameworks, our specialized agents collaboratively parse and analyze raw scientific data, generate hypotheses and experimental designs grounded in specific data characteristics, and write and execute corresponding code. Evaluation on three benchmarks shows SciDER excels in specialized data-driven scientific discovery and outperforms general-purpose agents and state-of-the-art models through its self-evolving memory and critic-led feedback loop. Distributed as a modular Python package, we also provide easy-to-use PyPI packages with a lightweight web interface to accelerate autonomous, data-driven research and aim to be accessible to all researchers and developers.
Wavelet-based Disentangled Adaptive Normalization for Non-stationary Times Series Forecasting
Jun 06, 2025Forecasting non-stationary time series is a challenging task because their statistical properties often change over time, making it hard for deep models to generalize well. Instance-level normalization techniques can help address shifts in temporal distribution. However, most existing methods overlook the multi-component nature of time series, where different components exhibit distinct non-stationary behaviors. In this paper, we propose Wavelet-based Disentangled Adaptive Normalization (WDAN), a model-agnostic framework designed to address non-stationarity in time series forecasting. WDAN uses discrete wavelet transforms to break down the input into low-frequency trends and high-frequency fluctuations. It then applies tailored normalization strategies to each part. For trend components that exhibit strong non-stationarity, we apply first-order differencing to extract stable features used for predicting normalization parameters. Extensive experiments on multiple benchmarks demonstrate that WDAN consistently improves forecasting accuracy across various backbone model. Code is available at this repository: https://github.com/MonBG/WDAN.
Think When You Need: Self-Adaptive Chain-of-Thought Learning
Apr 04, 2025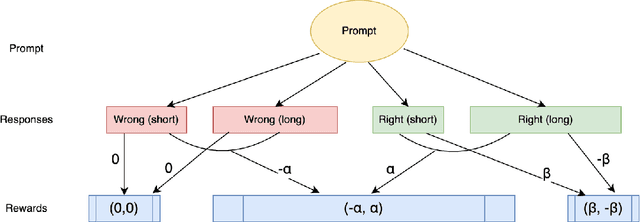
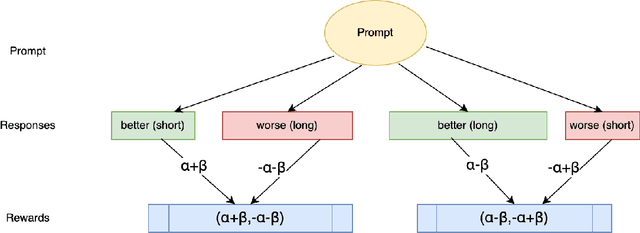
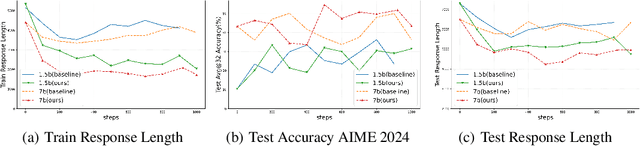
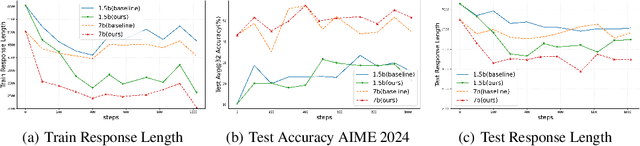
Chain of Thought (CoT) reasoning enhances language models' performance but often leads to inefficient "overthinking" on simple problems. We identify that existing approaches directly penalizing reasoning length fail to account for varying problem complexity. Our approach constructs rewards through length and quality comparisons, guided by theoretical assumptions that jointly enhance solution correctness with conciseness. Moreover, we further demonstrate our method to fuzzy tasks where ground truth is unavailable. Experiments across multiple reasoning benchmarks demonstrate that our method maintains accuracy while generating significantly more concise explanations, effectively teaching models to "think when needed."
Towards Precise Scaling Laws for Video Diffusion Transformers
Nov 25, 2024



Achieving optimal performance of video diffusion transformers within given data and compute budget is crucial due to their high training costs. This necessitates precisely determining the optimal model size and training hyperparameters before large-scale training. While scaling laws are employed in language models to predict performance, their existence and accurate derivation in visual generation models remain underexplored. In this paper, we systematically analyze scaling laws for video diffusion transformers and confirm their presence. Moreover, we discover that, unlike language models, video diffusion models are more sensitive to learning rate and batch size, two hyperparameters often not precisely modeled. To address this, we propose a new scaling law that predicts optimal hyperparameters for any model size and compute budget. Under these optimal settings, we achieve comparable performance and reduce inference costs by 40.1% compared to conventional scaling methods, within a compute budget of 1e10 TFlops. Furthermore, we establish a more generalized and precise relationship among validation loss, any model size, and compute budget. This enables performance prediction for non-optimal model sizes, which may also be appealed under practical inference cost constraints, achieving a better trade-off.
Koala-36M: A Large-scale Video Dataset Improving Consistency between Fine-grained Conditions and Video Content
Oct 10, 2024As visual generation technologies continue to advance, the scale of video datasets has expanded rapidly, and the quality of these datasets is critical to the performance of video generation models. We argue that temporal splitting, detailed captions, and video quality filtering are three key factors that determine dataset quality. However, existing datasets exhibit various limitations in these areas. To address these challenges, we introduce Koala-36M, a large-scale, high-quality video dataset featuring accurate temporal splitting, detailed captions, and superior video quality. The core of our approach lies in improving the consistency between fine-grained conditions and video content. Specifically, we employ a linear classifier on probability distributions to enhance the accuracy of transition detection, ensuring better temporal consistency. We then provide structured captions for the splitted videos, with an average length of 200 words, to improve text-video alignment. Additionally, we develop a Video Training Suitability Score (VTSS) that integrates multiple sub-metrics, allowing us to filter high-quality videos from the original corpus. Finally, we incorporate several metrics into the training process of the generation model, further refining the fine-grained conditions. Our experiments demonstrate the effectiveness of our data processing pipeline and the quality of the proposed Koala-36M dataset. Our dataset and code will be released at https://koala36m.github.io/.
ViRED: Prediction of Visual Relations in Engineering Drawings
Sep 02, 2024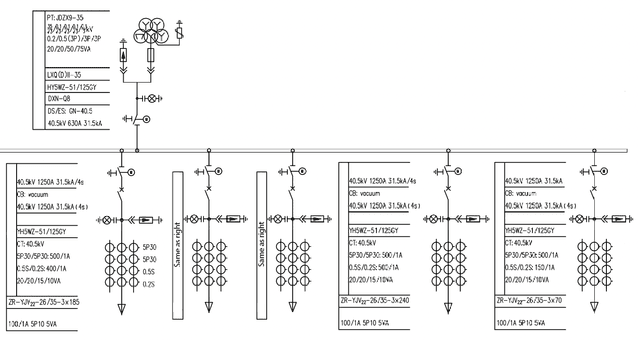
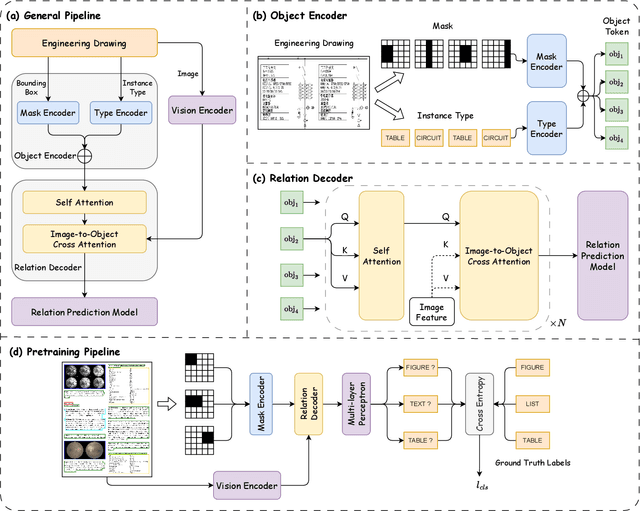
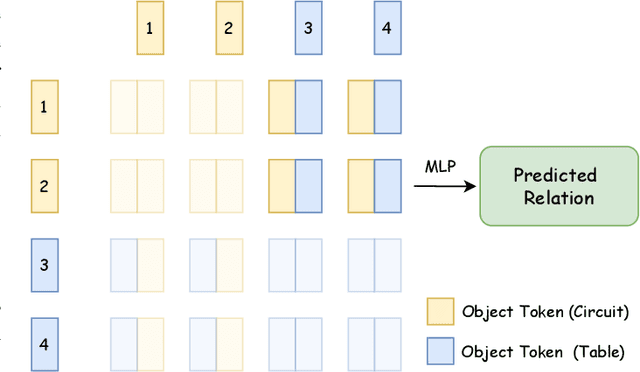

To accurately understand engineering drawings, it is essential to establish the correspondence between images and their description tables within the drawings. Existing document understanding methods predominantly focus on text as the main modality, which is not suitable for documents containing substantial image information. In the field of visual relation detection, the structure of the task inherently limits its capacity to assess relationships among all entity pairs in the drawings. To address this issue, we propose a vision-based relation detection model, named ViRED, to identify the associations between tables and circuits in electrical engineering drawings. Our model mainly consists of three parts: a vision encoder, an object encoder, and a relation decoder. We implement ViRED using PyTorch to evaluate its performance. To validate the efficacy of ViRED, we conduct a series of experiments. The experimental results indicate that, within the engineering drawing dataset, our approach attained an accuracy of 96\% in the task of relation prediction, marking a substantial improvement over existing methodologies. The results also show that ViRED can inference at a fast speed even when there are numerous objects in a single engineering drawing.
SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
Aug 21, 2024Multimodal Large Language Models (MLLMs) have recently demonstrated remarkable perceptual and reasoning abilities, typically comprising a Vision Encoder, an Adapter, and a Large Language Model (LLM). The adapter serves as the critical bridge between the visual and language components. However, training adapters with image-level supervision often results in significant misalignment, undermining the LLMs' capabilities and limiting the potential of Multimodal LLMs. To address this, we introduce Supervised Embedding Alignment (SEA), a token-level alignment method that leverages vision-language pre-trained models, such as CLIP, to align visual tokens with the LLM's embedding space through contrastive learning. This approach ensures a more coherent integration of visual and language representations, enhancing the performance and interpretability of multimodal LLMs while preserving their inherent capabilities. Extensive experiments show that SEA effectively improves MLLMs, particularly for smaller models, without adding extra data or inference computation. SEA also lays the groundwork for developing more general and adaptable solutions to enhance multimodal systems.
Low-Latency Privacy-Preserving Deep Learning Design via Secure MPC
Jul 24, 2024Secure multi-party computation (MPC) facilitates privacy-preserving computation between multiple parties without leaking private information. While most secure deep learning techniques utilize MPC operations to achieve feasible privacy-preserving machine learning on downstream tasks, the overhead of the computation and communication still hampers their practical application. This work proposes a low-latency secret-sharing-based MPC design that reduces unnecessary communication rounds during the execution of MPC protocols. We also present a method for improving the computation of commonly used nonlinear functions in deep learning by integrating multivariate multiplication and coalescing different packets into one to maximize network utilization. Our experimental results indicate that our method is effective in a variety of settings, with a speedup in communication latency of $10\sim20\%$.
Zero-shot Generative Linguistic Steganography
Mar 16, 2024



Generative linguistic steganography attempts to hide secret messages into covertext. Previous studies have generally focused on the statistical differences between the covertext and stegotext, however, ill-formed stegotext can readily be identified by humans. In this paper, we propose a novel zero-shot approach based on in-context learning for linguistic steganography to achieve better perceptual and statistical imperceptibility. We also design several new metrics and reproducible language evaluations to measure the imperceptibility of the stegotext. Our experimental results indicate that our method produces $1.926\times$ more innocent and intelligible stegotext than any other method.
Lost in Overlap: Exploring Watermark Collision in LLMs
Mar 15, 2024



The proliferation of large language models (LLMs) in generating content raises concerns about text copyright. Watermarking methods, particularly logit-based approaches, embed imperceptible identifiers into text to address these challenges. However, the widespread use of watermarking across diverse LLMs has led to an inevitable issue known as watermark collision during common tasks like question answering and paraphrasing. This study focuses on dual watermark collisions, where two watermarks are present simultaneously in the same text. The research demonstrates that watermark collision poses a threat to detection performance for detectors of both upstream and downstream watermark algorithms.