Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink When You Need: Self-Adaptive Chain-of-Thought Learning
Paper and Code
Apr 04, 2025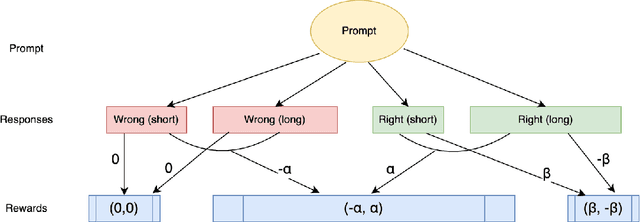
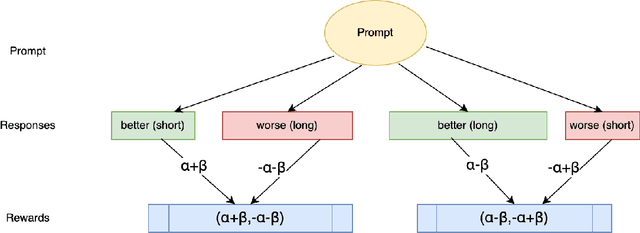
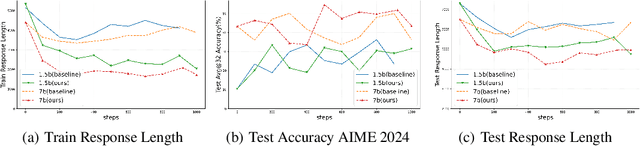
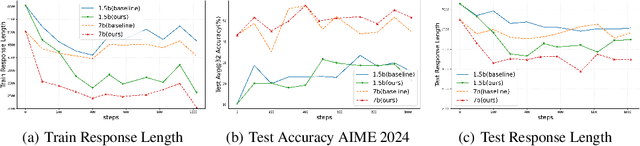
Chain of Thought (CoT) reasoning enhances language models' performance but often leads to inefficient "overthinking" on simple problems. We identify that existing approaches directly penalizing reasoning length fail to account for varying problem complexity. Our approach constructs rewards through length and quality comparisons, guided by theoretical assumptions that jointly enhance solution correctness with conciseness. Moreover, we further demonstrate our method to fuzzy tasks where ground truth is unavailable. Experiments across multiple reasoning benchmarks demonstrate that our method maintains accuracy while generating significantly more concise explanations, effectively teaching models to "think when needed."
* 9 pages
View paper on