 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViRED: Prediction of Visual Relations in Engineering Drawings
Sep 02, 2024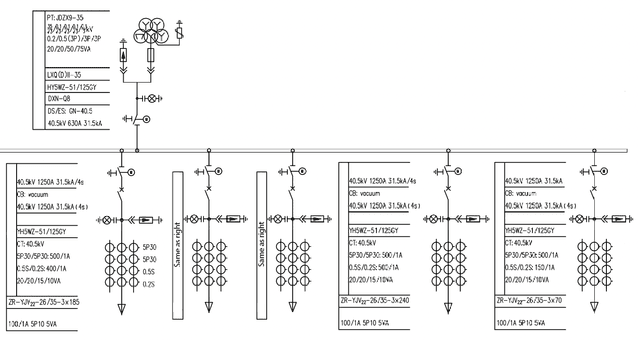
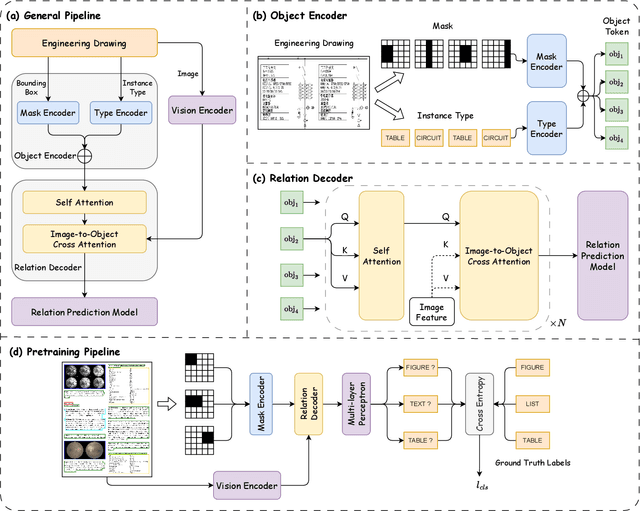
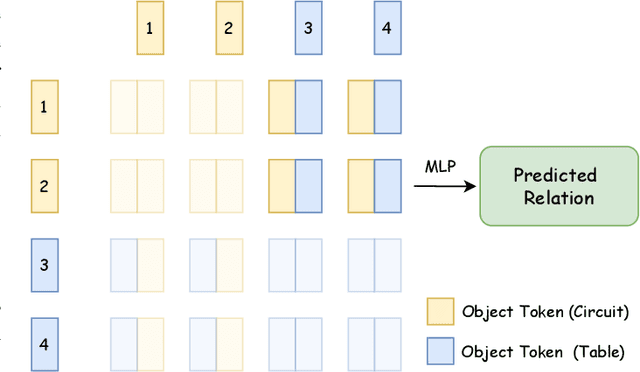

To accurately understand engineering drawings, it is essential to establish the correspondence between images and their description tables within the drawings. Existing document understanding methods predominantly focus on text as the main modality, which is not suitable for documents containing substantial image information. In the field of visual relation detection, the structure of the task inherently limits its capacity to assess relationships among all entity pairs in the drawings. To address this issue, we propose a vision-based relation detection model, named ViRED, to identify the associations between tables and circuits in electrical engineering drawings. Our model mainly consists of three parts: a vision encoder, an object encoder, and a relation decoder. We implement ViRED using PyTorch to evaluate its performance. To validate the efficacy of ViRED, we conduct a series of experiments. The experimental results indicate that, within the engineering drawing dataset, our approach attained an accuracy of 96\% in the task of relation prediction, marking a substantial improvement over existing methodologies. The results also show that ViRED can inference at a fast speed even when there are numerous objects in a single engineering drawing.
Lost in Overlap: Exploring Watermark Collision in LLMs
Mar 15, 2024



The proliferation of large language models (LLMs) in generating content raises concerns about text copyright. Watermarking methods, particularly logit-based approaches, embed imperceptible identifiers into text to address these challenges. However, the widespread use of watermarking across diverse LLMs has led to an inevitable issue known as watermark collision during common tasks like question answering and paraphrasing. This study focuses on dual watermark collisions, where two watermarks are present simultaneously in the same text. The research demonstrates that watermark collision poses a threat to detection performance for detectors of both upstream and downstream watermark algorithms.