 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriplet-Block Diffusion RWKV
May 25, 2026Causal Transformer language models suffer from strictly sequential decoding and a quadratic per-step attention cost. While linear-time causal models and discrete diffusion models each address these weaknesses, their integration remains inherently inconsistent: diffusion requires bidirectional attention, while causal models are unidirectional. To unify these architectures, we propose $B^3D-RWKV$, a diffusion RWKV variant that integrates the model's $O(L)$ inference efficiency with parallel, bidirectional discrete-diffusion through a \emph{triplet-block layout} method. $B^3D-RWKV-7.2B$ reaches comparable accuracy on an 8-task suite versus existing models while significantly outperforming baselines in decoding throughput with an average of $\mathbf{1.6\times}$ speedup.
Geo-LLaVA: A Large Multi-Modal Model for Solving Geometry Math Problems with Meta In-Context Learning
Dec 12, 2024
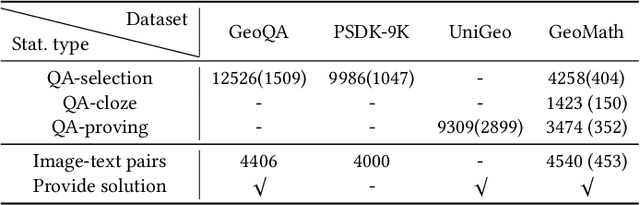
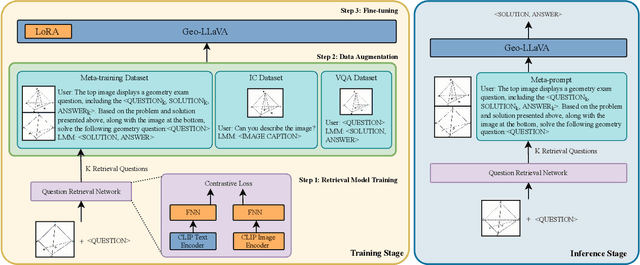
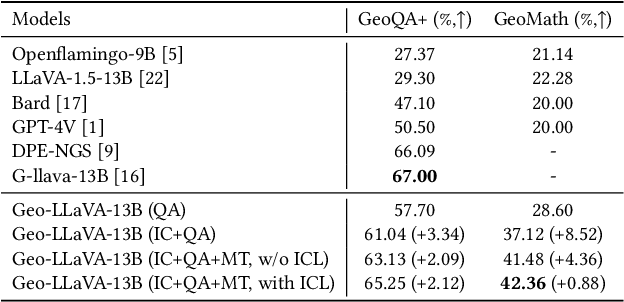
Geometry mathematics problems pose significant challenges for large language models (LLMs) because they involve visual elements and spatial reasoning. Current methods primarily rely on symbolic character awareness to address these problems. Considering geometry problem solving is a relatively nascent field with limited suitable datasets and currently almost no work on solid geometry problem solving, we collect a geometry question-answer dataset by sourcing geometric data from Chinese high school education websites, referred to as GeoMath. It contains solid geometry questions and answers with accurate reasoning steps as compensation for existing plane geometry datasets. Additionally, we propose a Large Multi-modal Model (LMM) framework named Geo-LLaVA, which incorporates retrieval augmentation with supervised fine-tuning (SFT) in the training stage, called meta-training, and employs in-context learning (ICL) during inference to improve performance. Our fine-tuned model with ICL attains the state-of-the-art performance of 65.25% and 42.36% on selected questions of the GeoQA dataset and GeoMath dataset respectively with proper inference steps. Notably, our model initially endows the ability to solve solid geometry problems and supports the generation of reasonable solid geometry picture descriptions and problem-solving steps. Our research sets the stage for further exploration of LLMs in multi-modal math problem-solving, particularly in geometry math problems.
ViRED: Prediction of Visual Relations in Engineering Drawings
Sep 02, 2024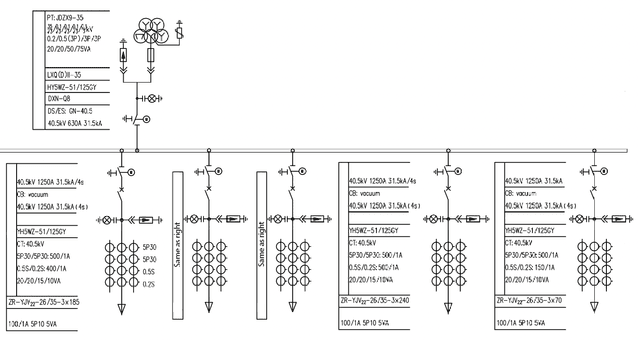
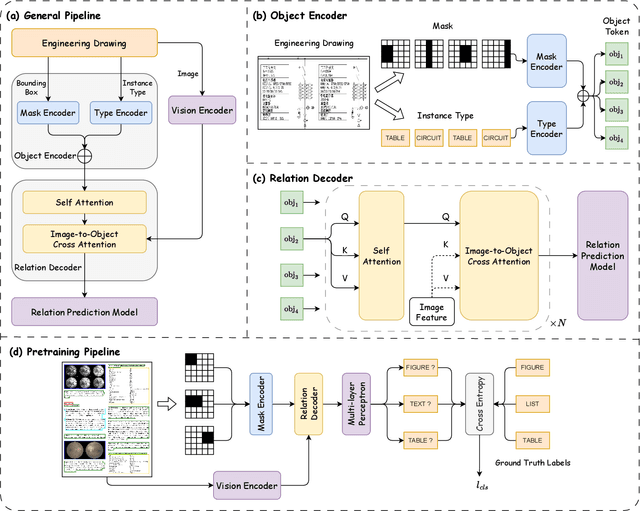
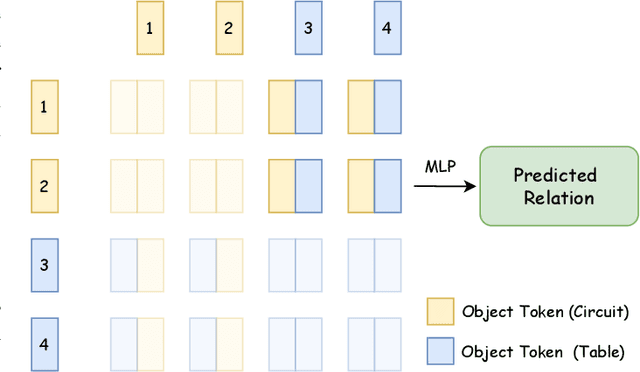

To accurately understand engineering drawings, it is essential to establish the correspondence between images and their description tables within the drawings. Existing document understanding methods predominantly focus on text as the main modality, which is not suitable for documents containing substantial image information. In the field of visual relation detection, the structure of the task inherently limits its capacity to assess relationships among all entity pairs in the drawings. To address this issue, we propose a vision-based relation detection model, named ViRED, to identify the associations between tables and circuits in electrical engineering drawings. Our model mainly consists of three parts: a vision encoder, an object encoder, and a relation decoder. We implement ViRED using PyTorch to evaluate its performance. To validate the efficacy of ViRED, we conduct a series of experiments. The experimental results indicate that, within the engineering drawing dataset, our approach attained an accuracy of 96\% in the task of relation prediction, marking a substantial improvement over existing methodologies. The results also show that ViRED can inference at a fast speed even when there are numerous objects in a single engineering drawing.
Zero-shot Generative Linguistic Steganography
Mar 16, 2024



Generative linguistic steganography attempts to hide secret messages into covertext. Previous studies have generally focused on the statistical differences between the covertext and stegotext, however, ill-formed stegotext can readily be identified by humans. In this paper, we propose a novel zero-shot approach based on in-context learning for linguistic steganography to achieve better perceptual and statistical imperceptibility. We also design several new metrics and reproducible language evaluations to measure the imperceptibility of the stegotext. Our experimental results indicate that our method produces $1.926\times$ more innocent and intelligible stegotext than any other method.
Lost in Overlap: Exploring Watermark Collision in LLMs
Mar 15, 2024



The proliferation of large language models (LLMs) in generating content raises concerns about text copyright. Watermarking methods, particularly logit-based approaches, embed imperceptible identifiers into text to address these challenges. However, the widespread use of watermarking across diverse LLMs has led to an inevitable issue known as watermark collision during common tasks like question answering and paraphrasing. This study focuses on dual watermark collisions, where two watermarks are present simultaneously in the same text. The research demonstrates that watermark collision poses a threat to detection performance for detectors of both upstream and downstream watermark algorithms.
PISA: Point-cloud-based Instructed Scene Augmentation
Nov 26, 2023Indoor scene augmentation has become an emerging topic in the field of computer vision with applications in augmented and virtual reality. However, existing scene augmentation methods mostly require a pre-built object database with a given position as the desired location. In this paper, we propose the first end-to-end multi-modal deep neural network that can generate point cloud objects consistent with their surroundings, conditioned on text instructions. Our model generates a seemly object in the appropriate position based on the inputs of a query and point clouds, thereby enabling the creation of new scenarios involving previously unseen layouts of objects. Database of pre-stored CAD models is no longer needed. We use Point-E as our generative model and introduce methods including quantified position prediction and Top-K estimation to mitigate the false negative problems caused by ambiguous language description. Moreover, we evaluate the ability of our model by demonstrating the diversity of generated objects, the effectiveness of instruction, and quantitative metric results, which collectively indicate that our model is capable of generating realistic in-door objects. For a more thorough evaluation, we also incorporate visual grounding as a metric to assess the quality of the scenes generated by our model.