 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND: Unified Inquiry and Diagnosis RL with Criteria Grounded Clinical Supports for Psychiatric Consultation
Mar 04, 2026Large language models (LLMs) have advanced medical dialogue systems, yet psychiatric consultation poses substantially higher demands due to subjective ambiguity and comorbidity complexity: an agent must continuously extract psychopathological cues from incomplete and inconsistent patient reports in multi-turn interactions and perform rigorous differential diagnostic reasoning. However, existing methods face two fundamental challenges. First, without criteria-grounded clinical supports, they are prone to unsupported clinical assertions when symptoms are atypical or underspecified. Second, in multi-turn interactions, they struggle to mitigate inquiry drift (off-topic or low-yield questioning) and optimize questioning strategies. To address these challenges, we propose MIND, a unified inquiry--diagnosis reinforcement learning framework for psychiatric consultation. Specifically, we build a Criteria-Grounded Psychiatric Reasoning Bank (PRB) that summarizes dialogue context into clinical retrieval states, retrieves semantically similar reference consultations, and distills reusable criteria-grounded clinical supports to guide criteria-aligned inquiry and reasoning. Building on this foundation, MIND enforces explicit clinical reasoning with rubric-based process rewards to provide fine-grained supervision over intermediate decision steps, and incorporates a value-aware trajectory rectification mechanism to jointly improve information acquisition and diagnostic decision-making across turns. Extensive experiments demonstrate that MIND consistently outperforms strong baselines in diagnostic accuracy, empathetic interaction quality, interpretability, and generalization.
Pailitao-VL: Unified Embedding and Reranker for Real-Time Multi-Modal Industrial Search
Feb 14, 2026In this work, we presented Pailitao-VL, a comprehensive multi-modal retrieval system engineered for high-precision, real-time industrial search. We here address three critical challenges in the current SOTA solution: insufficient retrieval granularity, vulnerability to environmental noise, and prohibitive efficiency-performance gap. Our primary contribution lies in two fundamental paradigm shifts. First, we transitioned the embedding paradigm from traditional contrastive learning to an absolute ID-recognition task. Through anchoring instances to a globally consistent latent space defined by billions of semantic prototypes, we successfully overcome the stochasticity and granularity bottlenecks inherent in existing embedding solutions. Second, we evolved the generative reranker from isolated pointwise evaluation to the compare-and-calibrate listwise policy. By synergizing chunk-based comparative reasoning with calibrated absolute relevance scoring, the system achieves nuanced discriminative resolution while circumventing the prohibitive latency typically associated with conventional reranking methods. Extensive offline benchmarks and online A/B tests on Alibaba e-commerce platform confirm that Pailitao-VL achieves state-of-the-art performance and delivers substantial business impact. This work demonstrates a robust and scalable path for deploying advanced MLLM-based retrieval architectures in demanding, large-scale production environments.
LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
Feb 11, 2026Mental disorders are highly prevalent worldwide, but the shortage of psychiatrists and the inherent subjectivity of interview-based diagnosis create substantial barriers to timely and consistent mental-health assessment. Progress in AI-assisted psychiatric diagnosis is constrained by the absence of benchmarks that simultaneously provide realistic patient simulation, clinician-verified diagnostic labels, and support for dynamic multi-turn consultation. We present LingxiDiagBench, a large-scale multi-agent benchmark that evaluates LLMs on both static diagnostic inference and dynamic multi-turn psychiatric consultation in Chinese. At its core is LingxiDiag-16K, a dataset of 16,000 EMR-aligned synthetic consultation dialogues designed to reproduce real clinical demographic and diagnostic distributions across 12 ICD-10 psychiatric categories. Through extensive experiments across state-of-the-art LLMs, we establish key findings: (1) although LLMs achieve high accuracy on binary depression--anxiety classification (up to 92.3%), performance deteriorates substantially for depression--anxiety comorbidity recognition (43.0%) and 12-way differential diagnosis (28.5%); (2) dynamic consultation often underperforms static evaluation, indicating that ineffective information-gathering strategies significantly impair downstream diagnostic reasoning; (3) consultation quality assessed by LLM-as-a-Judge shows only moderate correlation with diagnostic accuracy, suggesting that well-structured questioning alone does not ensure correct diagnostic decisions. We release LingxiDiag-16K and the full evaluation framework to support reproducible research at https://github.com/Lingxi-mental-health/LingxiDiagBench.
Omne-R1: Learning to Reason with Memory for Multi-hop Question Answering
Aug 24, 2025This paper introduces Omne-R1, a novel approach designed to enhance multi-hop question answering capabilities on schema-free knowledge graphs by integrating advanced reasoning models. Our method employs a multi-stage training workflow, including two reinforcement learning phases and one supervised fine-tuning phase. We address the challenge of limited suitable knowledge graphs and QA data by constructing domain-independent knowledge graphs and auto-generating QA pairs. Experimental results show significant improvements in answering multi-hop questions, with notable performance gains on more complex 3+ hop questions. Our proposed training framework demonstrates strong generalization abilities across diverse knowledge domains.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Geo-LLaVA: A Large Multi-Modal Model for Solving Geometry Math Problems with Meta In-Context Learning
Dec 12, 2024
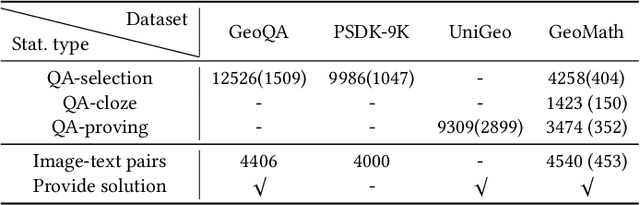
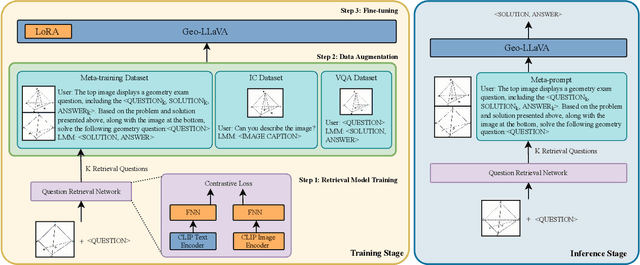
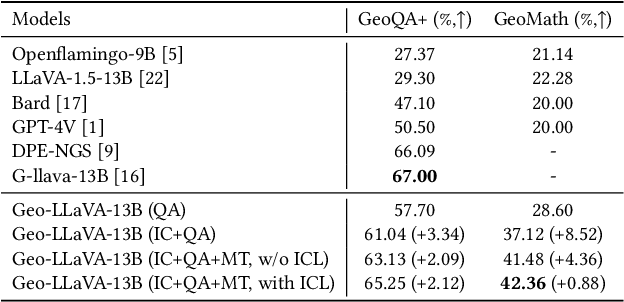
Geometry mathematics problems pose significant challenges for large language models (LLMs) because they involve visual elements and spatial reasoning. Current methods primarily rely on symbolic character awareness to address these problems. Considering geometry problem solving is a relatively nascent field with limited suitable datasets and currently almost no work on solid geometry problem solving, we collect a geometry question-answer dataset by sourcing geometric data from Chinese high school education websites, referred to as GeoMath. It contains solid geometry questions and answers with accurate reasoning steps as compensation for existing plane geometry datasets. Additionally, we propose a Large Multi-modal Model (LMM) framework named Geo-LLaVA, which incorporates retrieval augmentation with supervised fine-tuning (SFT) in the training stage, called meta-training, and employs in-context learning (ICL) during inference to improve performance. Our fine-tuned model with ICL attains the state-of-the-art performance of 65.25% and 42.36% on selected questions of the GeoQA dataset and GeoMath dataset respectively with proper inference steps. Notably, our model initially endows the ability to solve solid geometry problems and supports the generation of reasonable solid geometry picture descriptions and problem-solving steps. Our research sets the stage for further exploration of LLMs in multi-modal math problem-solving, particularly in geometry math problems.
Long Term Memory: The Foundation of AI Self-Evolution
Oct 21, 2024



Large language models (LLMs) like GPTs, trained on vast datasets, have demonstrated impressive capabilities in language understanding, reasoning, and planning, achieving human-level performance in various tasks. Most studies focus on enhancing these models by training on ever-larger datasets to build more powerful foundation models. While training stronger models is important, enabling models to evolve during inference is equally crucial, a process we refer to as AI self-evolution. Unlike large-scale training, self-evolution may rely on limited data or interactions. Inspired by the columnar organization of the human cerebral cortex, we hypothesize that AI models could develop cognitive abilities and build internal representations through iterative interactions with their environment. To achieve this, models need long-term memory (LTM) to store and manage processed interaction data. LTM supports self-evolution by representing diverse experiences across environments and agents. In this report, we explore AI self-evolution and its potential to enhance models during inference. We examine LTM's role in lifelong learning, allowing models to evolve based on accumulated interactions. We outline the structure of LTM and the systems needed for effective data retention and representation. We also classify approaches for building personalized models with LTM data and show how these models achieve self-evolution through interaction. Using LTM, our multi-agent framework OMNE achieved first place on the GAIA benchmark, demonstrating LTM's potential for AI self-evolution. Finally, we present a roadmap for future research, emphasizing the importance of LTM for advancing AI technology and its practical applications.
Multi-Level Graph Encoding with Structural-Collaborative Relation Learning for Skeleton-Based Person Re-Identification
Jun 06, 2021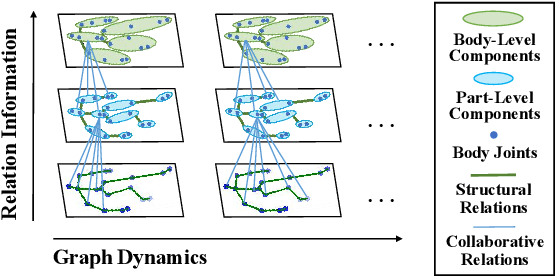
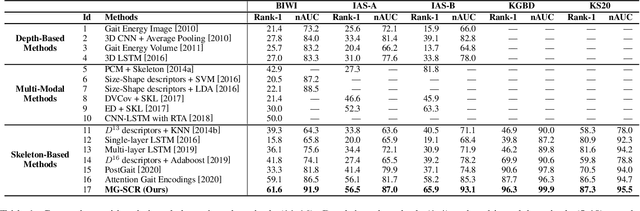
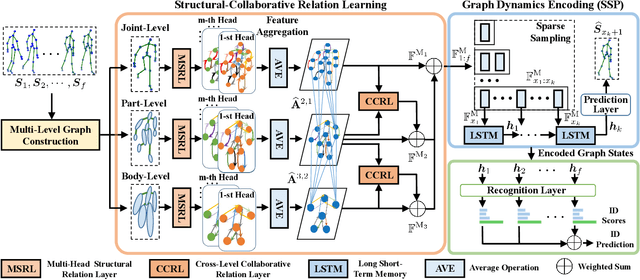
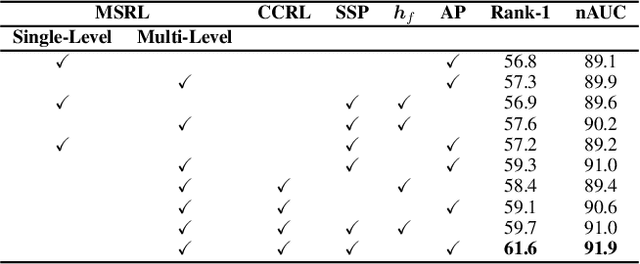
Skeleton-based person re-identification (Re-ID) is an emerging open topic providing great value for safety-critical applications. Existing methods typically extract hand-crafted features or model skeleton dynamics from the trajectory of body joints, while they rarely explore valuable relation information contained in body structure or motion. To fully explore body relations, we construct graphs to model human skeletons from different levels, and for the first time propose a Multi-level Graph encoding approach with Structural-Collaborative Relation learning (MG-SCR) to encode discriminative graph features for person Re-ID. Specifically, considering that structurally-connected body components are highly correlated in a skeleton, we first propose a multi-head structural relation layer to learn different relations of neighbor body-component nodes in graphs, which helps aggregate key correlative features for effective node representations. Second, inspired by the fact that body-component collaboration in walking usually carries recognizable patterns, we propose a cross-level collaborative relation layer to infer collaboration between different level components, so as to capture more discriminative skeleton graph features. Finally, to enhance graph dynamics encoding, we propose a novel self-supervised sparse sequential prediction task for model pre-training, which facilitates encoding high-level graph semantics for person Re-ID. MG-SCR outperforms state-of-the-art skeleton-based methods, and it achieves superior performance to many multi-modal methods that utilize extra RGB or depth features. Our codes are available at https://github.com/Kali-Hac/MG-SCR.
* Accepted at IJCAI 2021 Main Track. Sole copyright holder is IJCAI. Codes are available at https://github.com/Kali-Hac/MG-SCR
Prototypical Contrast and Reverse Prediction: Unsupervised Skeleton Based Action Recognition
Nov 14, 2020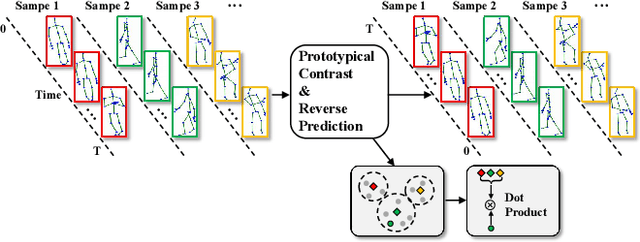

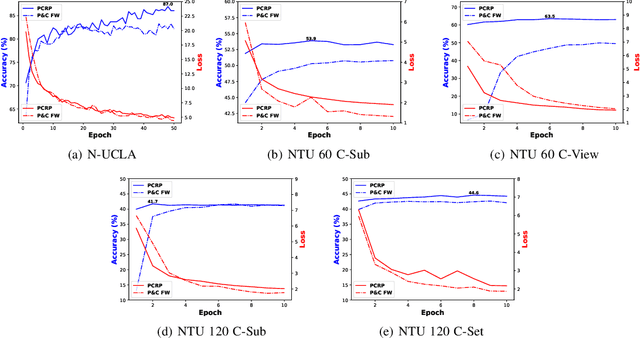
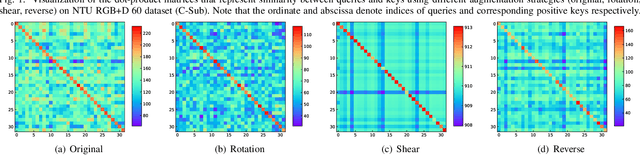
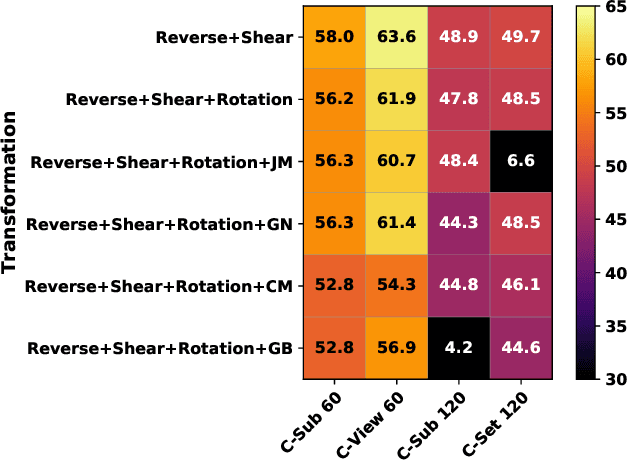
In this paper, we focus on unsupervised representation learning for skeleton-based action recognition. Existing approaches usually learn action representations by sequential prediction but they suffer from the inability to fully learn semantic information. To address this limitation, we propose a novel framework named Prototypical Contrast and Reverse Prediction (PCRP), which not only creates reverse sequential prediction to learn low-level information (e.g., body posture at every frame) and high-level pattern (e.g., motion order), but also devises action prototypes to implicitly encode semantic similarity shared among sequences. In general, we regard action prototypes as latent variables and formulate PCRP as an expectation-maximization task. Specifically, PCRP iteratively runs (1) E-step as determining the distribution of prototypes by clustering action encoding from the encoder, and (2) M-step as optimizing the encoder by minimizing the proposed ProtoMAE loss, which helps simultaneously pull the action encoding closer to its assigned prototype and perform reverse prediction task. Extensive experiments on N-UCLA, NTU 60, and NTU 120 dataset present that PCRP outperforms state-of-the-art unsupervised methods and even achieves superior performance over some of supervised methods. Codes are available at https://github.com/Mikexu007/PCRP.
Augmented Skeleton Based Contrastive Action Learning with Momentum LSTM for Unsupervised Action Recognition
Aug 18, 2020
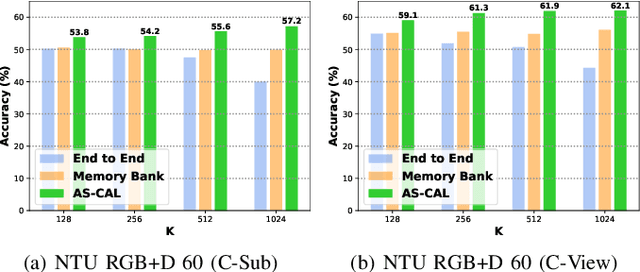
Action recognition via 3D skeleton data is an emerging important topic in these years. Most existing methods either extract hand-crafted descriptors or learn action representations by supervised learning paradigms that require massive labeled data. In this paper, we for the first time propose a contrastive action learning paradigm named AS-CAL that can leverage different augmentations of unlabeled skeleton data to learn action representations in an unsupervised manner. Specifically, we first propose to contrast similarity between augmented instances (query and key) of the input skeleton sequence, which are transformed by multiple novel augmentation strategies, to learn inherent action patterns ("pattern-invariance") of different skeleton transformations. Second, to encourage learning the pattern-invariance with more consistent action representations, we propose a momentum LSTM, which is implemented as the momentum-based moving average of LSTM based query encoder, to encode long-term action dynamics of the key sequence. Third, we introduce a queue to store the encoded keys, which allows our model to flexibly reuse proceeding keys and build a more consistent dictionary to improve contrastive learning. Last, by temporally averaging the hidden states of action learned by the query encoder, a novel representation named Contrastive Action Encoding (CAE) is proposed to represent human's action effectively. Extensive experiments show that our approach typically improves existing hand-crafted methods by 10-50% top-1 accuracy, and it can achieve comparable or even superior performance to numerous supervised learning methods.