 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Skeleton Based Contrastive Action Learning with Momentum LSTM for Unsupervised Action Recognition
Paper and Code

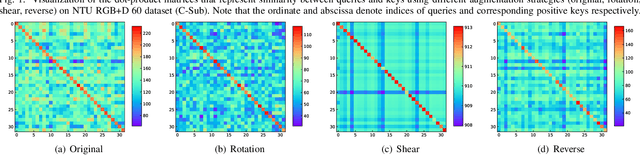
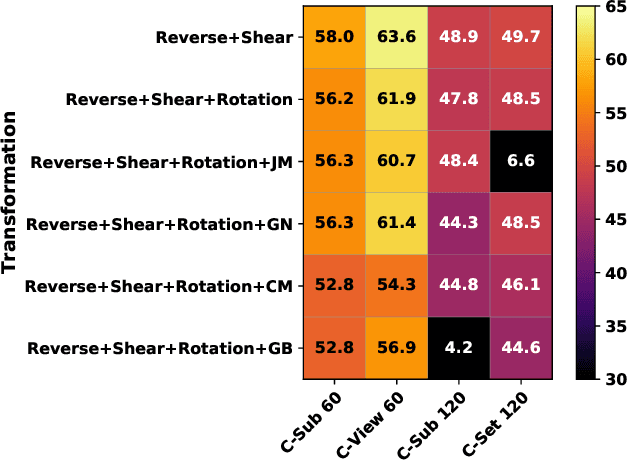
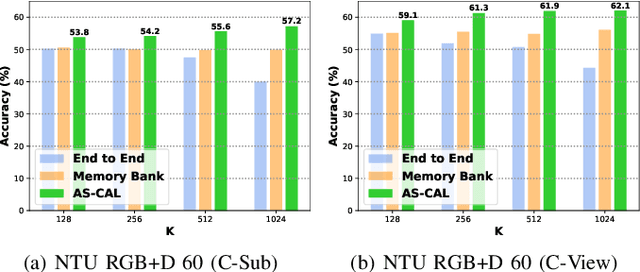
Action recognition via 3D skeleton data is an emerging important topic in these years. Most existing methods either extract hand-crafted descriptors or learn action representations by supervised learning paradigms that require massive labeled data. In this paper, we for the first time propose a contrastive action learning paradigm named AS-CAL that can leverage different augmentations of unlabeled skeleton data to learn action representations in an unsupervised manner. Specifically, we first propose to contrast similarity between augmented instances (query and key) of the input skeleton sequence, which are transformed by multiple novel augmentation strategies, to learn inherent action patterns ("pattern-invariance") of different skeleton transformations. Second, to encourage learning the pattern-invariance with more consistent action representations, we propose a momentum LSTM, which is implemented as the momentum-based moving average of LSTM based query encoder, to encode long-term action dynamics of the key sequence. Third, we introduce a queue to store the encoded keys, which allows our model to flexibly reuse proceeding keys and build a more consistent dictionary to improve contrastive learning. Last, by temporally averaging the hidden states of action learned by the query encoder, a novel representation named Contrastive Action Encoding (CAE) is proposed to represent human's action effectively. Extensive experiments show that our approach typically improves existing hand-crafted methods by 10-50% top-1 accuracy, and it can achieve comparable or even superior performance to numerous supervised learning methods.