 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Traditional Machine Learning, Deep Learning, and Large Language Models for Mental Health Forecasting using Smartphone Sensing Data
Jan 07, 2026Smartphone sensing offers an unobtrusive and scalable way to track daily behaviors linked to mental health, capturing changes in sleep, mobility, and phone use that often precede symptoms of stress, anxiety, or depression. While most prior studies focus on detection that responds to existing conditions, forecasting mental health enables proactive support through Just-in-Time Adaptive Interventions. In this paper, we present the first comprehensive benchmarking study comparing traditional machine learning (ML), deep learning (DL), and large language model (LLM) approaches for mental health forecasting using the College Experience Sensing (CES) dataset, the most extensive longitudinal dataset of college student mental health to date. We systematically evaluate models across temporal windows, feature granularities, personalization strategies, and class imbalance handling. Our results show that DL models, particularly Transformer (Macro-F1 = 0.58), achieve the best overall performance, while LLMs show strength in contextual reasoning but weaker temporal modeling. Personalization substantially improves forecasts of severe mental health states. By revealing how different modeling approaches interpret phone sensing behavioral data over time, this work lays the groundwork for next-generation, adaptive, and human-centered mental health technologies that can advance both research and real-world well-being.
What Makes Reasoning Invalid: Echo Reflection Mitigation for Large Language Models
Nov 09, 2025
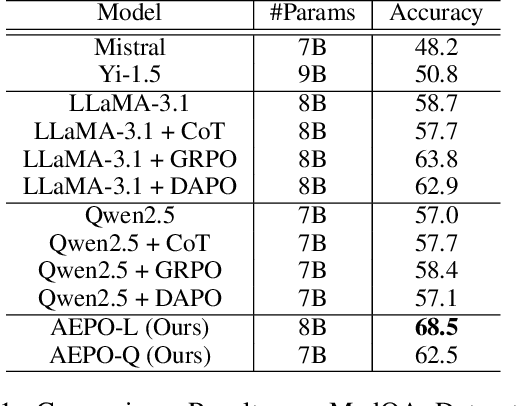
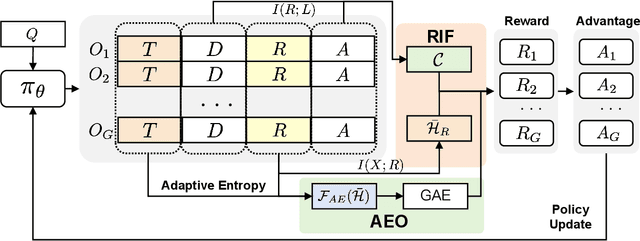
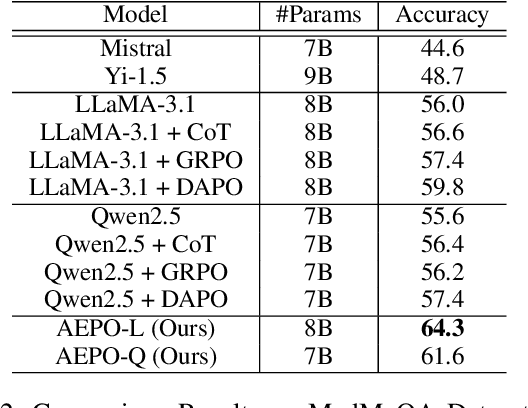
Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of reasoning tasks. Recent methods have further improved LLM performance in complex mathematical reasoning. However, when extending these methods beyond the domain of mathematical reasoning to tasks involving complex domain-specific knowledge, we observe a consistent failure of LLMs to generate novel insights during the reflection stage. Instead of conducting genuine cognitive refinement, the model tends to mechanically reiterate earlier reasoning steps without introducing new information or perspectives, a phenomenon referred to as "Echo Reflection". We attribute this behavior to two key defects: (1) Uncontrollable information flow during response generation, which allows premature intermediate thoughts to propagate unchecked and distort final decisions; (2) Insufficient exploration of internal knowledge during reflection, leading to repeating earlier findings rather than generating new cognitive insights. Building on these findings, we proposed a novel reinforcement learning method termed Adaptive Entropy Policy Optimization (AEPO). Specifically, the AEPO framework consists of two major components: (1) Reflection-aware Information Filtration, which quantifies the cognitive information flow and prevents the final answer from being affected by earlier bad cognitive information; (2) Adaptive-Entropy Optimization, which dynamically balances exploration and exploitation across different reasoning stages, promoting both reflective diversity and answer correctness. Extensive experiments demonstrate that AEPO consistently achieves state-of-the-art performance over mainstream reinforcement learning baselines across diverse benchmarks.
Investigating Advanced Reasoning of Large Language Models via Black-Box Interaction
Aug 26, 2025Existing tasks fall short in evaluating reasoning ability of Large Language Models (LLMs) in an interactive, unknown environment. This deficiency leads to the isolated assessment of deductive, inductive, and abductive reasoning, neglecting the integrated reasoning process that is indispensable for humans discovery of real world. We introduce a novel evaluation paradigm, \textit{black-box interaction}, to tackle this challenge. A black-box is defined by a hidden function that maps a specific set of inputs to outputs. LLMs are required to unravel the hidden function behind the black-box by interacting with it in given exploration turns, and reasoning over observed input-output pairs. Leveraging this idea, we build the \textsc{Oracle} benchmark which comprises 6 types of black-box task and 96 black-boxes. 19 modern LLMs are benchmarked. o3 ranks first in 5 of the 6 tasks, achieving over 70\% accuracy on most easy black-boxes. But it still struggles with some hard black-box tasks, where its average performance drops below 40\%. Further analysis indicates a universal difficulty among LLMs: They lack the high-level planning capability to develop efficient and adaptive exploration strategies for hypothesis refinement.
AgentDistill: Training-Free Agent Distillation with Generalizable MCP Boxes
Jun 17, 2025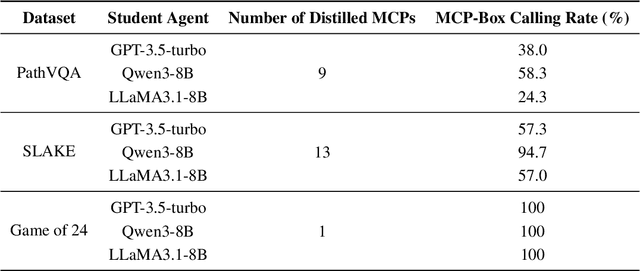
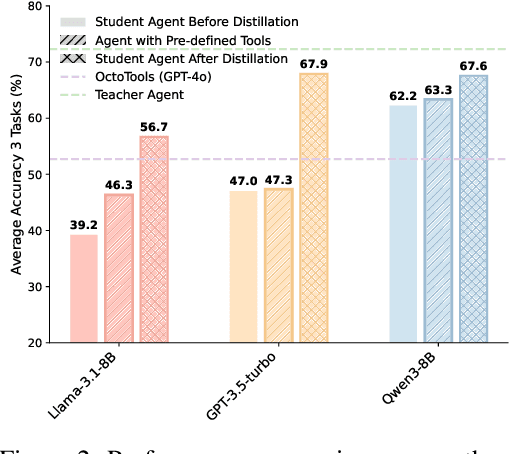
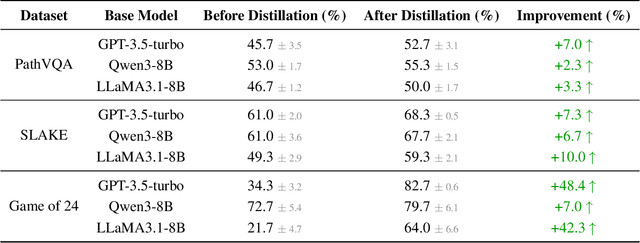
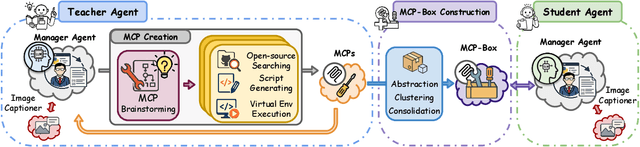
While knowledge distillation has become a mature field for compressing large language models (LLMs) into smaller ones by aligning their outputs or internal representations, the distillation of LLM-based agents, which involve planning, memory, and tool use, remains relatively underexplored. Existing agent distillation methods typically replay full teacher trajectories or imitate step-by-step teacher tool usage, but they often struggle to train student agents to dynamically plan and act in novel environments. We propose AgentDistill, a novel, training-free agent distillation framework that enables efficient and scalable knowledge transfer via direct reuse of Model-Context-Protocols (MCPs), which are structured and reusable task-solving modules autonomously generated by teacher agents. The reuse of these distilled MCPs enables student agents to generalize their capabilities across domains and solve new problems with minimal supervision or human intervention. Experiments on biomedical and mathematical benchmarks demonstrate that our distilled student agents, built on small language models, can achieve performance comparable to advanced systems using large LLMs such as OctoTools (GPT-4o), highlighting the effectiveness of our framework in building scalable and cost-efficient intelligent agents.
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
May 26, 2025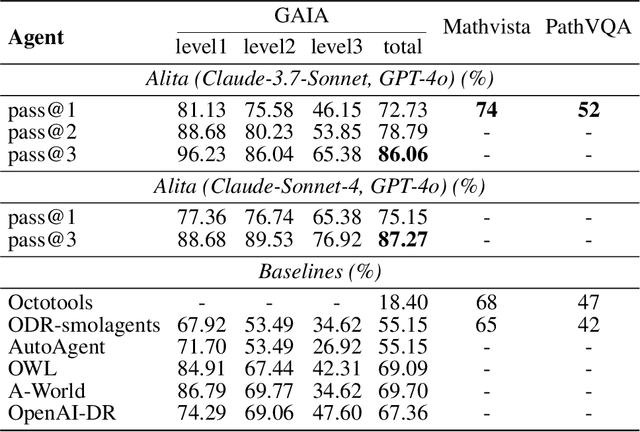
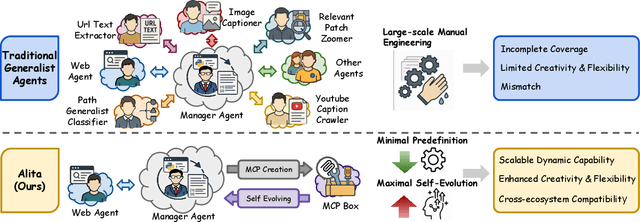
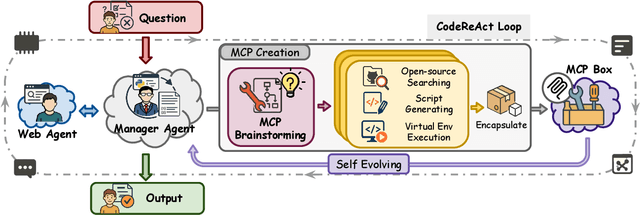

Recent advances in large language models (LLMs) have enabled agents to autonomously perform complex, open-ended tasks. However, many existing frameworks depend heavily on manually predefined tools and workflows, which hinder their adaptability, scalability, and generalization across domains. In this work, we introduce Alita--a generalist agent designed with the principle of "Simplicity is the ultimate sophistication," enabling scalable agentic reasoning through minimal predefinition and maximal self-evolution. For minimal predefinition, Alita is equipped with only one component for direct problem-solving, making it much simpler and neater than previous approaches that relied heavily on hand-crafted, elaborate tools and workflows. This clean design enhances its potential to generalize to challenging questions, without being limited by tools. For Maximal self-evolution, we enable the creativity of Alita by providing a suite of general-purpose components to autonomously construct, refine, and reuse external capabilities by generating task-related model context protocols (MCPs) from open source, which contributes to scalable agentic reasoning. Notably, Alita achieves 75.15% pass@1 and 87.27% pass@3 accuracy, which is top-ranking among general-purpose agents, on the GAIA benchmark validation dataset, 74.00% and 52.00% pass@1, respectively, on Mathvista and PathVQA, outperforming many agent systems with far greater complexity. More details will be updated at $\href{https://github.com/CharlesQ9/Alita}{https://github.com/CharlesQ9/Alita}$.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
EmoAgent: Assessing and Safeguarding Human-AI Interaction for Mental Health Safety
Apr 13, 2025The rise of LLM-driven AI characters raises safety concerns, particularly for vulnerable human users with psychological disorders. To address these risks, we propose EmoAgent, a multi-agent AI framework designed to evaluate and mitigate mental health hazards in human-AI interactions. EmoAgent comprises two components: EmoEval simulates virtual users, including those portraying mentally vulnerable individuals, to assess mental health changes before and after interactions with AI characters. It uses clinically proven psychological and psychiatric assessment tools (PHQ-9, PDI, PANSS) to evaluate mental risks induced by LLM. EmoGuard serves as an intermediary, monitoring users' mental status, predicting potential harm, and providing corrective feedback to mitigate risks. Experiments conducted in popular character-based chatbots show that emotionally engaging dialogues can lead to psychological deterioration in vulnerable users, with mental state deterioration in more than 34.4% of the simulations. EmoGuard significantly reduces these deterioration rates, underscoring its role in ensuring safer AI-human interactions. Our code is available at: https://github.com/1akaman/EmoAgent
Long Term Memory: The Foundation of AI Self-Evolution
Oct 21, 2024



Large language models (LLMs) like GPTs, trained on vast datasets, have demonstrated impressive capabilities in language understanding, reasoning, and planning, achieving human-level performance in various tasks. Most studies focus on enhancing these models by training on ever-larger datasets to build more powerful foundation models. While training stronger models is important, enabling models to evolve during inference is equally crucial, a process we refer to as AI self-evolution. Unlike large-scale training, self-evolution may rely on limited data or interactions. Inspired by the columnar organization of the human cerebral cortex, we hypothesize that AI models could develop cognitive abilities and build internal representations through iterative interactions with their environment. To achieve this, models need long-term memory (LTM) to store and manage processed interaction data. LTM supports self-evolution by representing diverse experiences across environments and agents. In this report, we explore AI self-evolution and its potential to enhance models during inference. We examine LTM's role in lifelong learning, allowing models to evolve based on accumulated interactions. We outline the structure of LTM and the systems needed for effective data retention and representation. We also classify approaches for building personalized models with LTM data and show how these models achieve self-evolution through interaction. Using LTM, our multi-agent framework OMNE achieved first place on the GAIA benchmark, demonstrating LTM's potential for AI self-evolution. Finally, we present a roadmap for future research, emphasizing the importance of LTM for advancing AI technology and its practical applications.
MDD-5k: A New Diagnostic Conversation Dataset for Mental Disorders Synthesized via Neuro-Symbolic LLM Agents
Aug 22, 2024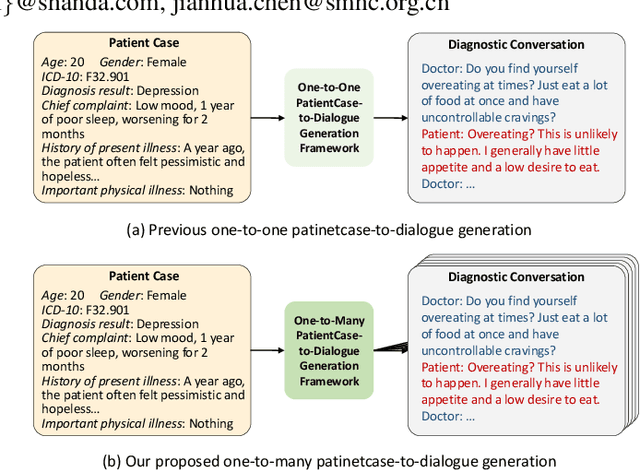

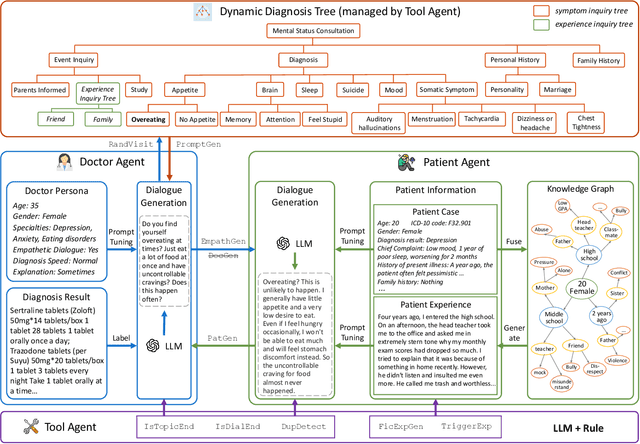

The clinical diagnosis of most mental disorders primarily relies on the conversations between psychiatrist and patient. The creation of such diagnostic conversation datasets is promising to boost the AI mental healthcare community. However, directly collecting the conversations in real diagnosis scenarios is near impossible due to stringent privacy and ethical considerations. To address this issue, we seek to synthesize diagnostic conversation by exploiting anonymous patient cases that are easier to access. Specifically, we design a neuro-symbolic multi-agent framework for synthesizing the diagnostic conversation of mental disorders with large language models. It takes patient case as input and is capable of generating multiple diverse conversations with one single patient case. The framework basically involves the interaction between a doctor agent and a patient agent, and achieves text generation under symbolic control via a dynamic diagnosis tree from a tool agent. By applying the proposed framework, we develop the largest Chinese mental disorders diagnosis dataset MDD-5k, which is built upon 1000 cleaned real patient cases by cooperating with a pioneering psychiatric hospital, and contains 5000 high-quality long conversations with diagnosis results as labels. To the best of our knowledge, it's also the first labelled Chinese mental disorders diagnosis dataset. Human evaluation demonstrates the proposed MDD-5k dataset successfully simulates human-like diagnostic process of mental disorders. The dataset and code will become publicly accessible in https://github.com/lemonsis/MDD-5k.
PDNNet: PDN-Aware GNN-CNN Heterogeneous Network for Dynamic IR Drop Prediction
Mar 27, 2024
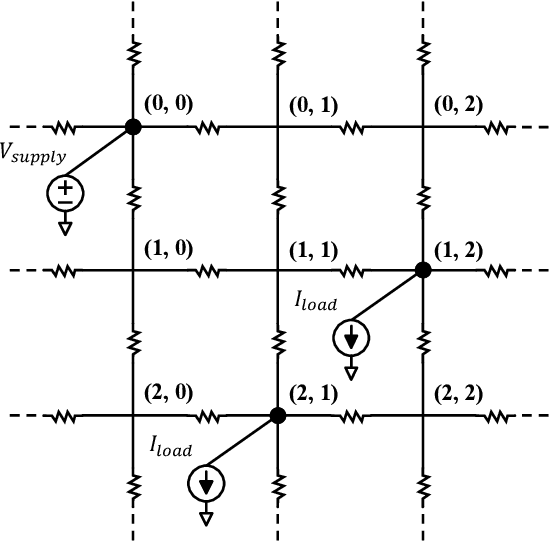
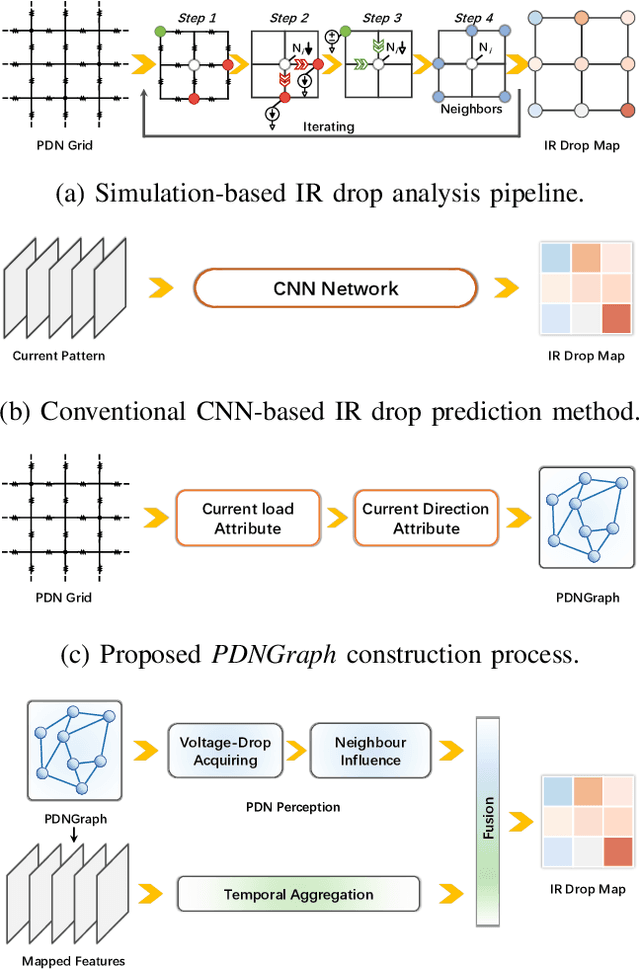
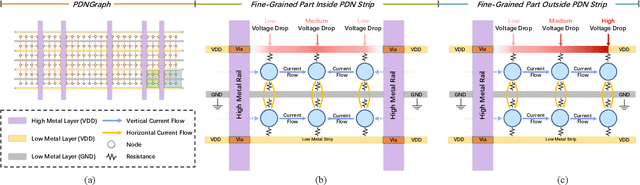
IR drop on the power delivery network (PDN) is closely related to PDN's configuration and cell current consumption. As the integrated circuit (IC) design is growing larger, dynamic IR drop simulation becomes computationally unaffordable and machine learning based IR drop prediction has been explored as a promising solution. Although CNN-based methods have been adapted to IR drop prediction task in several works, the shortcomings of overlooking PDN configuration is non-negligible. In this paper, we consider not only how to properly represent cell-PDN relation, but also how to model IR drop following its physical nature in the feature aggregation procedure. Thus, we propose a novel graph structure, PDNGraph, to unify the representations of the PDN structure and the fine-grained cell-PDN relation. We further propose a dual-branch heterogeneous network, PDNNet, incorporating two parallel GNN-CNN branches to favorably capture the above features during the learning process. Several key designs are presented to make the dynamic IR drop prediction highly effective and interpretable. We are the first work to apply graph structure to deep-learning based dynamic IR drop prediction method. Experiments show that PDNNet outperforms the state-of-the-art CNN-based methods by up to 39.3% reduction in prediction error and achieves 545x speedup compared to the commercial tool, which demonstrates the superiority of our method.